
파이썬 머신러닝 완벽 가이드 (권철민 저)을 요약정리했습니다.
앙상블 학습
앙상블 학습을 통한 분류는 여러 개의 분류기를 생성하고 그 예측을 결합함으로써 보다 정확한 최종 예측 결과를 도출 하는 기법을 말한다.
앙상블 학습의 유형은 보팅,배깅, 부스팅 세 가지로 나눌 수 있으며, 이외에도 스태킹을 포함한 다양한 앙상블 기법이 있다.
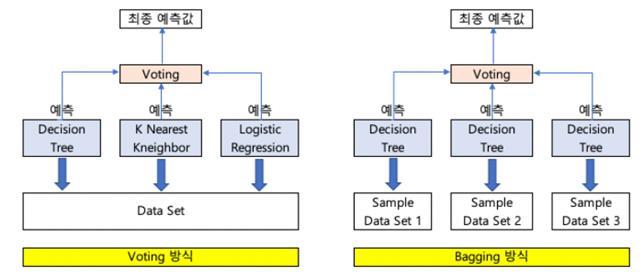
보팅과 배깅
보팅과 배깅의 다른점은 보팅의 경우 일반적으로 서로 다른 알고리즘을 가진 분류기를 결합한 것이고 배깅의 경우 각각의 분류기가 모두 같은 유형의 알고리즘 기반이지만 데이터 샘플링을 서로 다르게 가져가면서 학습을 수행해 보팅 하는 것이다. 대표적인 배깅 방식이 바로 랜덤 포레스트 알고리즘 이다.
부스팅
부스팅은 여러 개의 분류기가 순차적으로 학습을 수행하 되, 분류기에서 예측을 잘못한 데이터에 더 집중하여 다음 모델에서 학습한다. 즉 각 분류기에서 가중치를 부여하며 학습과 예측을 진행한다. 분류기에게 가중치를 부스팅하면서 학습을 진행하기에 부스팅 방식으로 불린다.
대표적인 부스팅 모듈로는 XGBoost, LightGBM 등이 있다.
스태킹
스태킹은 여러가지 다른 모델의 예측 결괏값을 다시 학습데이터로 마들어서 다른 모델로 재학습 시켜 결과를 예측하는 방법이다.
하드 보팅(Hard Voting) 과 소프트 보팅(Soft Voting)
보팅 방법에는 하드보팅과 소프트 보팅 2가지 방법이 있는데, 하드 보팅을 이용한 분류는 다수결 원칙과 비슷하다.
예측한 결괏값들 중 다수의 분류기가 결정한 예측값을 최종 보팅 결괏값으로 선정하는 것이다.
소프트 보팅은 분류기들의 레이블 값 결정 확률을 모두 더하고 이를 평균하여 이들중 확률 값이 가장 높은 레이블 값을 최종 보팅 결괏값으로 선정한다.
일반적으로 소프트 보팅을 많이 한다.

부스팅 스트래핑
여러개의 데이터셋을 중첩되게 분리하는 방식을 부스틍 스트래핑분할 방식이라고 한다.
원본 데이터 건수가 10 개인 학습데이터 셋에 랜덤 포레스트를 3개의 결정 트리 기반으로 학습하기 위해 n_estimators = 3으로 하이퍼 파라미터를 부여하면 다음과 같은 데이터 서브셋이 만들어 진다.
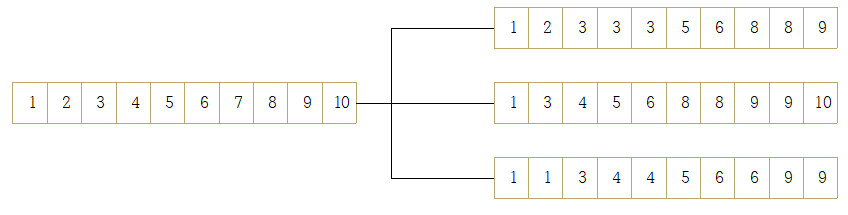
이렇게 데이터가 중첩된 개별 데이터 셋에 결정 트리 분류기를 각각 적용하는 것이 랜덤 포레스트 이다.
사이킷런을 이용한 랜덤 포레스트
import pandas as pd
def get_human_dataset( ):
# 각 데이터 파일들은 공백으로 분리되어 있으므로 read_csv에서 공백 문자를 sep으로 할당.
feature_name_df = pd.read_csv('./human_activity/features.txt',sep='\s+',
header=None,names=['column_index','column_name'])
# DataFrame에 피처명을 컬럼으로 부여하기 위해 리스트 객체로 다시 변환
feature_name = feature_name_df.iloc[:, 1].values.tolist()
# 학습 피처 데이터 셋과 테스트 피처 데이터을 DataFrame으로 로딩. 컬럼명은 feature_name 적용
X_train = pd.read_csv('./human_activity/train/X_train.txt',sep='\s+', names=feature_name)
X_test = pd.read_csv('./human_activity/test/X_test.txt',sep='\s+', names=feature_name)
# 학습 레이블과 테스트 레이블 데이터을 DataFrame으로 로딩하고 컬럼명은 action으로 부여
y_train = pd.read_csv('./human_activity/train/y_train.txt',sep='\s+',header=None,names=['action'])
y_test = pd.read_csv('./human_activity/test/y_test.txt',sep='\s+',header=None,names=['action'])
# 로드된 학습/테스트용 DataFrame을 모두 반환
return X_train, X_test, y_train, y_test
X_train, X_test, y_train, y_test = get_human_dataset()from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
# 결정 트리에서 사용한 get_human_dataset( )을 이용해 학습/테스트용 DataFrame 반환
X_train, X_test, y_train, y_test = get_human_dataset()
# 랜덤 포레스트 학습 및 별도의 테스트 셋으로 예측 성능 평가
rf_clf = RandomForestClassifier(random_state=0)
rf_clf.fit(X_train , y_train)
pred = rf_clf.predict(X_test)
accuracy = accuracy_score(y_test , pred)
print('랜덤 포레스트 정확도: {0:.4f}'.format(accuracy))랜덤 포레스트 정확도: 0.9108랜덤 포레스트 하이퍼 파라미터 튜닝
트리 기반의 앙상블 알고리즘의 단점을 굳이 뽑자면 하이퍼 파라미터가 너무 많고, 그로 인해 튜닝에 소요되는 시간이 많다는 것이다. 또 튜닝을 한다고해서 예측 성능이 크게 향상되지도 않습니다.
이번에는 GridSearchCV를 이용해 랜덤 포레스트의 하이퍼 파라미터를 튜닝해 보자. 앞의 사용자 행동 데이터 셋을 그대로 이용하고,
튜닝 시간을 절약하기 위해 n_estimaotrs는 100으로 ,cv를 2로 설정해서 최적 하이퍼 파라미터를 구해보자.
다른 하이퍼 파라미터를 최적화 한뒤 n_estimators는 나중에 300으로 증가시켜서 예측 성능을 평가해봅시다.
멀티 코어 cpu 환경에서 RandomForestClasssifier 생성자와 GridSearchCV 생성시
n_jobs = -1 파라미터를 추가하면 모든 CPU 코어를 이용해 학습할 수 있다.
from sklearn.model_selection import GridSearchCV
params = {
'n_estimators':[100],
'max_depth' : [6, 8, 10, 12],
'min_samples_leaf' : [8, 12, 18 ],
'min_samples_split' : [8, 16, 20]
}
# RandomForestClassifier 객체 생성 후 GridSearchCV 수행
rf_clf = RandomForestClassifier(random_state=0, n_jobs=-1)
#하이퍼 파라미터
grid_cv = GridSearchCV(rf_clf , param_grid=params , cv=2, n_jobs=-1 )
grid_cv.fit(X_train , y_train)
print('최적 하이퍼 파라미터:\n', grid_cv.best_params_)
print('최고 예측 정확도: {0:.4f}'.format(grid_cv.best_score_))최적 하이퍼 파라미터:
{'max_depth': 10, 'min_samples_leaf': 8, 'min_samples_split': 8, 'n_estimators': 100}
최고 예측 정확도: 0.9168
feature_importances_ 속성을 이용하여 알고리즘이 선택한 피처의 중요도를 알 수 있다. 피처 중요도를 막대그래프로 시각화 해보자.
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
ftr_importances_values = rf_clf1.feature_importances_
ftr_importances = pd.Series(ftr_importances_values,index=X_train.columns )
ftr_top20 = ftr_importances.sort_values(ascending=False)[:20]
plt.figure(figsize=(8,6))
plt.title('Feature importances Top 20')
sns.barplot(x=ftr_top20 , y = ftr_top20.index)
plt.show()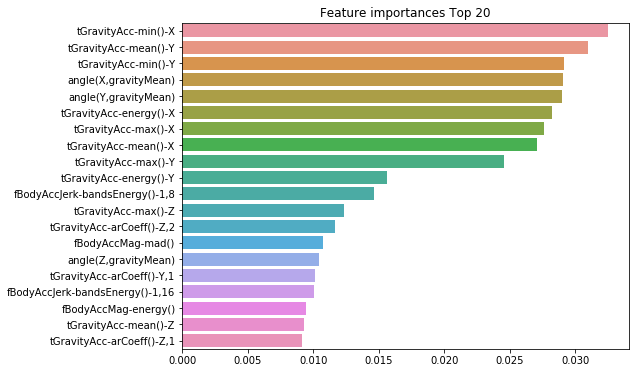
GBM(gradient Boosting Machine)
부스팅 알고리즘은 여러개의 약한 학습기를 순차적으로 학습 - 예측 하면서 잘못 예측한 데이터에 가중치를 부여하여 오류를 개선해 학습하는 방식이다.
부스팅의 대표적인 구현은 AdaBoost와 그래디언트 부스트가 있다.
에이다부수트는 오류 데이터에 가중치를 부여 하면서 부스팅을 수행하는 대표적인 알고즘이다. 아래 그림을 통해 에이다 부스트가 어떻게 작동하는지 살펴 봅시다.
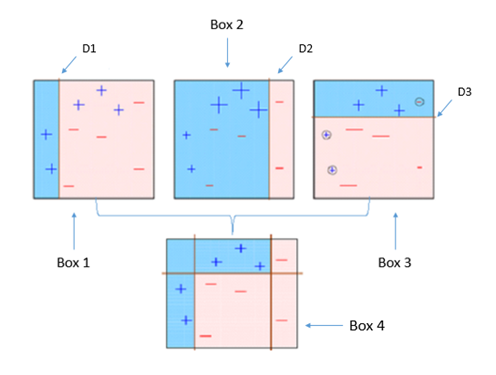
- 첫 번째 약한 학습기가 첫번째 분류기준(D1)으로 + 와 - 를 분류
- 잘못 분류된 데이터에 대해 가중치를 부여(두 번째 그림에서 커진 + 표시)
- 두 번째 약한 학습기가 두번째 분류기준(D2)으로 +와 - 를 다시 분류
- 잘못 분류된 데이터에 대해 가중치를 부여(세 번째 그림에서 커진 - 표시)
- 세 번째 약한 학습기가 세번째 분류기준으로(D3) +와 -를 다시 분류해서 오류 데이터를 찾음
- 마지막으로 분류기들을 결합하여 최종 예측 수행
약한 학습기를 순차적으로 학습시켜, 개별 학습기에 가중치를 부여하여 모두 결합함으로써 개별 약한 학습기보다 높은 정확도의 예측 결과를 만든다.
GBM도 에이다 부스트와 유사하나, 가중치 업데이트를 경사 하강법을 이용하는 것이 큰 차이다.
사이킷런은 GBM기반의 분류를 위해서 GradientBoostinClassifer 클래스르 제공한다. 사이킷런의 GBM을 이용해 사용자 행동 데이터 셋을 예측 분류 해보자. 또한 GBM으로 학습하는 시간이 얼마나 걸리는지 수행 시간도 같이 측정해보자.
from sklearn.ensemble import GradientBoostingClassifier
import time
import warnings
warnings.filterwarnings('ignore')
X_train, X_test, y_train, y_test = get_human_dataset()
# GBM 수행 시간 측정을 위함. 시작 시간 설정.
start_time = time.time()
gb_clf = GradientBoostingClassifier(random_state=0)
gb_clf.fit(X_train , y_train)
gb_pred = gb_clf.predict(X_test)
gb_accuracy = accuracy_score(y_test, gb_pred)
print('GBM 정확도: {0:.4f}'.format(gb_accuracy))
print("GBM 수행 시간: {0:.1f} 초 ".format(time.time() - start_time))GBM 정확도: 0.9376
GBM 수행 시간: 160.2 초 기본 하이퍼 파라미터만으로 93.76%의 예측 정확도로 앞의 랜덤 포레스트보다 나은 예측 성능을 나타낸다.
일반적으로 GBM이 랜덤 포레스트보다는 예측 성능이 조금 뛰어난 경우가 많다.
그러나 수행시간이 오래걸리고, 하이퍼 파라미터 튜닝 노력도 더 필요하다. 특히 수행 시간 문제는 GBM이 극복해야할 문제이다.
-> Light GBM으로 해결됨 다음에 포스팅 예정.
'머신러닝' 카테고리의 다른 글
| 스태킹 앙상블 (0) | 2020.08.21 |
|---|---|
| LightGBM (0) | 2020.08.21 |
| 결정 트리 (0) | 2020.08.20 |
| 머신러닝 성능 평가 (0) | 2020.08.20 |
| numpy, pandas 기초 (0) | 2020.08.20 |