EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
·
딥러닝/Vision
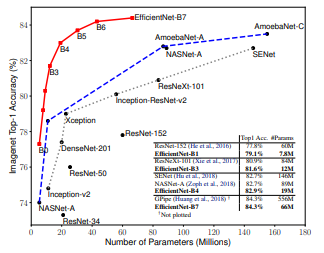
Efficient net 은 2019 CVPR에 발표된 MnasNet: Platform-Aware Neural Architecture Search for Mobile 의 저자인 Mingxing Tan*과 *Quoc V. Le 가 쓴 논문이며 Image Classification 타겟의 굉장히 성능이 좋은 Model인 EfficientNet을 제안하였습니다. Intorduction ConvNet의 성능을 올리기 위해 scaling up을 시도하는 것은 일반적은 일 입니다. 잘 알려진 ResNet은 ResNet-18 부터 ResNet-200 까지 망의 깊이(depth)를 늘려 성능 향상을 이루어 냈습니다. scaling up 하는 방식은 크게 3가지가 있습니다. 신경망의 depth(깊이)를 늘리는 것 cha..


