본 글은 "How Does Quantization Affect Multilingual LLMs?"라는 논문을 읽고 내용을 리뷰하는 글입니다.
서론
해당 논문의 주 내용은 모델 양자화(Quantization)가 다국어 LLM의 미치는 영향을 분석하는 내용이 주를 이룹니다.
양자화는 모델의 추론 속도를 향상시키고 배포를 용이하게 하기 위해 널리 사용되는 기법입니다. 그러나 대부분의 기존 연구는 영어 작업에 미치는 영향만을 다루고 있으며, 다국어에 미치는 영향에 대한 연구는 거의 없었습니다.
이 논문의 주요 포인트는 다음과 같습니다:
1. 양자화가 다국어 모델에 미치는 영향: 연구는 다국어 LLM에서 양자화가 어떻게 성능에 영향을 미치는지, 특히 다양한 언어와 규모에서의 성능 변화를 분석합니다. 논문에서는 자동화된 평가, LLM-기반 평가, human evaluation 등을 통해 양자화의 영향을 분석했습니다.
2. 양자화로 인한 성능 저하: human evaluation 결과에 따르면, 양자화로 인한 성능 저하가 매우 크며, 자동 평가에서 나타난 결과보다 훨씬 더 큰 차이가 있음을 발견했습니다. 예를 들어, 일본어에서 자동 평가는 1.7%의 성능 저하가 발생했고 human evaluation에서는 16.0%의 성능 저하가 발생하였스니다.
3. 언어별 영향 차이: 양자화가 언어마다 다르게 영향을 미치며, 특히 비라틴 문자 언어에서 더 큰 성능 저하가 나타났습니다. 라틴 문자 언어에 비해 비라틴 문자 언어는 양자화로 인한 성능 저하가 더 심각하게 나타났습니다.
4. 어려운 작업에서의 성능 저하: 수학적 추론과 같은 복잡한 작업에서 양자화로 인한 성능 저하가 더욱 두드러지게 나타났습니다. 이러한 작업에서는 양자화로 인한 성능 저하가 다른 작업에 비해 훨씬 더 큽니다.
5. 양자화의 일부 긍정적 효과: 일부 경우에는 양자화가 모델 성능에 긍정적인 영향을 미치는 경우도 있었습니다. 예를 들어, 35B LLM에서 W8A8 양자화는 일부 작업에서 1.3%의 성능 향상을 가져왔습니다.
양자화가 다국어 모델에 미치는 영향
논문에서 연구팀은 다국어 대형 언어 모델(LLM)에서 양자화가 미치는 영향을 다양한 방법으로 분석했습니다.
1. 양자화 방식과 모델 선택
- 연구팀은 8B ~103B의 파라미터를 가진 다양한 규모의 다국어 LLM(예: Command R+, Aya 23 모델)을 선택
- 양자화 방식으로는 주로 Weight-Only Quantization(W8, W4-g)과 Weight-and-Activation Quantization(W8A8, W8A8-SmoothQuant)를 사용하였고, 각각의 모델에서 다양한 양자화 설정을 적용해 비교 분석 진행
2. 평가 방법
- 자동 평가(Auto Evaluation): mMMLU, MGSM, FLORES-200 등 다양한 자동 평가 지표를 사용해 양자화된 모델의 성능을 측정. 주요 지표로는 번역 성능을 측정하는 SacreBLEU와 수학적 추론 능력을 평가하는 MGSM 등을 사용
- Multilingual MMLU (mMMLU): 여러 도메인에서 14,000개 이상의 객관식 질문을 포함하는 다중 도메인 질문 응답 데이터셋
- MGSM: GSM8K에서 수작업으로 번역된 생성적 수학 평가 세트입니다. 독일어, 스페인어, 프랑스어, 일본어, 중국어로 제공되며, 각 언어에 대해 250개 항목의 테스트 세트에 대한 정확도 계산.
- FLORES-200: 다중 병렬 테스트 세트로 번역 능력을 평가. 영어로 번역한 결과와 반대로 번역한 결과를 SacreBLEU 점수를 통해 평가
- Language Confusion: 사용자가 원하는 언어로 응답할 수 있는 모델의 능력을 평가하는 테스트 데이터 셋. 한 언어로 프롬프트를 제공하고, 그에 해당하는 언어로 응답해야 한다. Cross-lingual variant의 경우 영어로 프롬프트를 제공하고 다른 언어로 응답을 요청.
- 인간 평가(Human Evaluation): 다국어 인간 평가를 통해 실제 사용 시 양자화된 모델이 얼마나 성능 저하를 겪는지 분석. 일본어, 한국어, 프랑스어, 스페인어 등 네 가지 언어로 수행된 인간 평가는 특히 복잡한 질문과 현실적인 프롬프트에 대한 모델의 반응 평가
- LLM-as-a-Judge: 자동화된 평가와 인간 평가 사이의 격차를 줄이기 위해, LLM이 자체적으로 답변을 생성하고 그 결과를 평가하는 방법을 사용
3. 주요 분석 결과
언어별 영향 차이
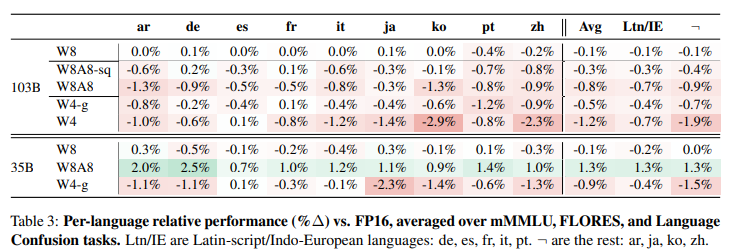
비라틴 문자 언어(예: 일본어, 한국어, 중국어 등)가 라틴 문자 언어(예: 영어, 프랑스어)보다 양자화로 인한 성능 저하가 더 심각하게 나타났습니다. 이는 양자화가 특정 언어에 불리하게 작용할 수 있다는 점을 보여줍니다.
그러나 일부 모델에서는 양자화가 오히려 성능을 개선하는 경우도 발견되었습니다. (Aya 35B 모델에서 W8A8 양자화 적용시 특정 작업 성능 1.3% 향상)
이는 특정 상황에서는 양자화가 모델의 효율성을 향상시킬 수 있음을 보여줍니다.
자동 평가와 인간 평가의 차이
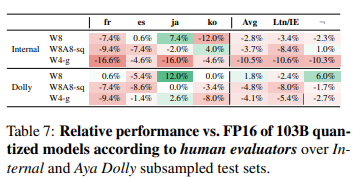
자동 평가에서 양자화로 인한 성능 저하가 1-2%로 비교적 적게 나타났지만, 인간 평가에서는 10% 이상, 일본어의 경우 최대 16%에 이르는 큰 성능 저하가 발견되었습니다. 이는 자동 평가가 실제 성능 저하를 과소평가할 수 있음을 시사합니다.
자동 평가 지표는 모델의 성능을 빠르고 일관되게 측정할 수 있는 도구입니다. 그러나 이러한 지표는 인간의 언어 이해 능력과 비교할 때 몇 가지 중요한 한계를 가지고 있습니다.
특히 양자화와 같은 모델 변형이 성능에 미치는 미묘한 영향을 정확히 포착하지 못할 수 있습니다.
복잡한 작업에서의 성능 저하
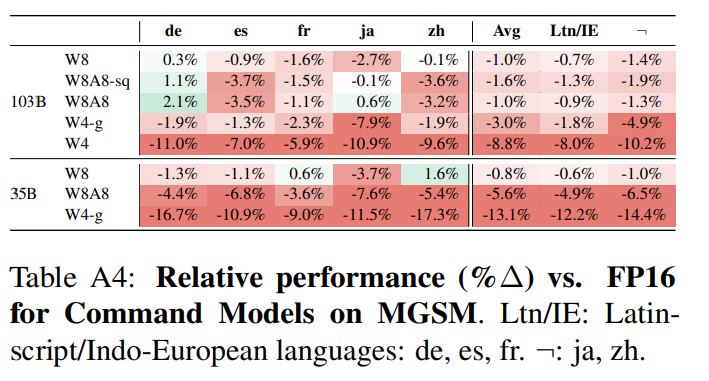
수학적 추론과 같은 복잡한 작업에서는 양자화로 인한 성능 저하가 특히 두드러졌습니다. 이는 복잡한 계산을 필요로 하는 작업이 양자화에 더 민감하다는 것을 시사합니다.
아래 표에서 MGSM(Mathematical Generalization and System Manipulation) 작업의 성능이 특히 큰 영향을 받는다고 설명 합니다.
특히, 35B 모델에서 W4-g 양자화가 적용된 경우, 평균 성능이 -13.1%까지 하락하며, 중국어에서 -17.3%로 가장 큰 감소를 보입니다.
4. 결론
- 다국어 성능의 중요성: 연구는 다국어 LLM에서 양자화가 특히 비라틴 문자 언어와 복잡한 작업에서 큰 영향을 미친다는 점을 강조하며, 다국어 성능을 고려한 모델 설계의 중요성을 강조합니다.
- 모델 설계의 주의사항: 연구 결과는 모델을 설계할 때 양자화로 인해 발생할 수 있는 다국어 성능 저하를 충분히 고려해야 한다고 말합니다. 특히, 자동 평가만으로는 성능 저하를 완전히 평가할 수 없으므로, 인간 평가와 같은 현실적인 평가가 필요하다는 점도 지적했습니다.
Reference
- https://arxiv.org/abs/2407.03211
'딥러닝 > LLM' 카테고리의 다른 글
| LLM을 활용한 지식 증류: sLLM 성능 최적화 실험 (5) | 2024.09.01 |
|---|---|
| LLM의 양자화가 한국어에 미치는 영향 (2) | 2024.08.19 |
| LLM의 다양한 SFT 기법: Full Fine-Tuning, PEFT (LoRA, QLoRA) (0) | 2024.08.06 |
| Supervised Fine-tuning: customizing LLMs (0) | 2024.08.06 |
| Gemma 2 (9B & 27B) Evaluation vs. Open/Closed-Source LLMs (0) | 2024.08.01 |