최근 경향
Trends of NLP
-
word embedding: 문장 내 각 단어가 의미를 갖도록 벡터 공간 내 하나의 점과 매핑(word2vec) -
RNN-family models: 문장이라는 시퀀스 데이터에 맞는 모델들(LSTM, GRU, transformer)-
각 언어의 어순 등 rule 기반으로 수행되던 알고리즘을 벗어나(많은 예외사항과 다양한 사용 패턴이 존재)
-
영어와 한글이 잘 번역된 문장을 학습하여 특별한 언어학적인 룰을 배제하고, 단지 시퀀스 데이터를 학습할 수 있는 RNN 기반의 모델을 활용하자 성능이 크게 증가했음
-
-
Transformer model: 현재 가장 활발히 활용 및 연구되고 있는 모델-
핵심 모듈인 self-attention 모듈을 단순히 계속 쌓아 나가는 식으로 모델의 크기를 키움
-
이 모델은 대규모 텍스트 데이터를 통해 소위 자가지도학습 수행(태스크를 위한 별도의 레이블이 필요하지 않은, 범용적 태스크)
-
다른 여러 태스크에 전이학습의 형태로 적용할 시 각 태스크에 특화되도록 설계된 기존 모델들보다 훨씬 월등한 성능을 냄
-
범용 인공지능 기술 : BERT, GPT-2, GPT-3
-
-
자가지도학습(self supervised learning): 입력 문장이 주어져 있을 때 일부 단어를 masking 하여 그 단어를 맞추도록 하는 태스크(그 의미와 품사가 어울리도록 예측)- 대규모의 데이터와 엄청난 GPU resource가 필요함
- GPT-3는 모델 학습하는 데만 엄청난 전기세가 사용됨..막강한 자본력 필요
Bag-of-Words(BOW)
딥러닝 이전(신경망 없는 머신러닝 등)에 많이 활용된 벡터화 기법이다.
문장(문서)에 나타난 모든 unique한 단어들을 one-hot encoding된 벡터로 나타낸 후 문장별(문서별) 단어의 빈도수를 체크하는 방법에서 출발한다.
Word2Vec
기존 one-hot encoding 기반 단어 벡터화는 희소 벡터가 생성되기 때문에 공간적 낭비가 커지게 되며 단어 자체의 의미를 벡터 수치 값이 지니지 못한다. 따라서 차원을 줄이고 수치 자체에 의미를 담은 밀집 벡터(dense vector)로 단어를 벡터화 하면 좋은데 이를 워드 임베딩(word embedding)이라고 한다.
분산 표현
워드 임베딩도 여러가지가 있는데, 여기서 다루고자 하는 Word2Vec,Glove는 모두 분산 표현을 목표로 하는 임베딩이다. 분산 표현이란 분포 가설(distributional hypothesis)에 기반한 표현 방법으로, 비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다라는 가정이다. 이 가정을 통해 생성된 임베딩 벡터들은한국 - 서울 + 도쿄 = 일본 와 같은 연산이 수행 가능한데, 이것은 임베딩 벡터에 단어간 유사도가 반영되었기 때문이다.
Word2Vec 수행
Word2Vec에는 CBOW(Continuous Bag of Words)와 Skip-Gram 두가지 방법이 있다. 두 방법 모두 중심 단어와 주변 단어(사전에 정의한 window size가 주변의 기준이 됨)가 비슷한 의미를 가진다는 것(분포 가설)을 학습시킴으로써 임베딩 벡터를 얻는 방법이다. 차이점을 보면 CBOW는 input, output으로(주변단어, 중심단어)가 들어가고 반면 Skip-Gram은 (중심단어, 주변단어)가 들어가게 된다. 방법도 약간의 차이가 있지만 거의 유사하다고 보면 된다. 다만 많은 논문에서 성능 비교시 Skip-gram이 대체로 더 우수한 성능을 가지고 있다고 알려져 있다.
Skip-Gram 방법을 살펴보자.
먼저 문서에 나타난 모든 단어들을 one-hot encoding한 후, 앞서 말했듯이 중심단어의 원핫벡터가 입력으로 들어갔을 때 출력으로 주변단어의 원핫벡터가 나오도록 가중치를 학습시키면 된다. 여기서 hidden layer의 차원은 hyper parameter인데, hidden layer의 차원수가 곧 임베딩 벡터의 차원수가 된다.

예를 들어 'I study math' 라는 문장은 {'I','study','math'}로 이러우져 있으므로 중심단어를 study로 보았을 때 window size를 3으로 하면 주변단어 'I','math'가 잘나오도록 가중치를 학습 시키면 된다.
여기서는 Input:'study'[0,1,0], Output:'math'[0,0,1]를 예시로 보자.
input인 study인 원학벡터는 레이어를 통과하여 output으로 math의원핫벡터가 나와야 한다.
여기서 워학 벡터의 특성상 결국 $W_1$의 2번째 column이 hidden layer로 들어오게 되므로 사실 이부분은 행렬곱이 아니라 해당 위치의 column vector를 뽑아 온다고 생각하면 된다.
또한 역으로 생각하면 $W_2$의 3번째 row가 math의 원핫벡터에 직접적 영향을 주게 되므로 사실 위 그림에서 색칠된 이 두 벡터가 여기서 가장 중요한 벡터 들이다.
output에 대하여 softmax를 취하므로 raw output은 $\left[ -\infty, -\infty, \infty \right]$가 나오도록 하는 것이 학습의 목표이며, 학습의 결과로 나온 색칠된 벡터들 즉 $W_1$의 2번째 column, $W_2$의 3번째 row는 각각 study를 나타내는 벡터, math를 나타내는 벡터가 된다.
이렇게 하여 최종 결과로 나온 $W_1^T$와 $W_2$중 어떤 것이든 임베딩 벡터로 사용해도 상관 없는데, 통상적으로 $W_1^T$를 임베딩 벡터로 사용하게 된다.
Property and Application
실제로 이렇게 학습된 임베딩 벡터들은 유사 의미관계를 보이는 벡터들간의 비슷한 위치관계를 보인다.

예를 들어, vec[queen]-vec[king] $\approx$vec[woman]-vec[man](여성 남성의 위치 관계가 비슷)임을 알 수 있다.
- Word2Vec의 임베딩 벡터 활용
- 주어진 단어 중 단어간 유클리드 거리 평균이 가장 큰 단어가 의미가 가장 상이한 단어이다.
- 대부분의 NLP 분야에 활용 가능.
GloVe
GloVe(Global Vectors for Word Representation)는 Word2Vec에 단어 빈도수에 대한 정보까지 포함하여 워드 임베딩을 수행한 방법이다.
상황에따라 Word2Vec와 Glove중 골라서 사용하면 된다.
LSA(SVD를 이용한 방법)는 단어 의미 유추 작업에서 약점을 보이며, Word2Vec는 윈도우 사이즈 밖의 단어들의 의미를 고려하지 못한다. 따라서 각각의 한계를 극복하여 LSA의 카운트 기반 방법과 Word2Vec의 예측 기반 방법을 결합하여 나오게 된 방법이 GloVe이다.
Co-occurrence Matrix(동시 등장 행렬)
동시 등장 행렬은 윈도우 크기 N일 때 중심 단어 주변 N개 단어들의 빈도를 나타낸 행렬이다.
ex )
I like deep learning
I like NLP
I enjoy flying
윈도우 크기가 N 일때는 좌,우에 존재하는 N개의 단어만 참고하게 된다. 윈도우 크기가 1일 때, 위의 텍스트를 가지고 구성한 동시 등장 행렬은 다음과 같다.

위 행렬은 전치해도 동일한 행렬이 된다는 특징이 있다.
Co-occurrence Probability(동시 등장 확률)
동시 등장확률 p(k|i)는 동시 등장 행렬로부터 특정 단어 i의 전체 등장 횟수를 카운트 하고, 위에서 배운 동시 등장 행렬에서 중심 단어 i의 행의 모든 값을 더한 값을 분모로 하고, i행 k열의 값을 분자로 한 값이라고 볼 수 있다.

위의 표를 보면 solid가 등장했을 때, ic가 등장할 확률은 0.00019 이고,
solid가 등장했을 때 stream이 등장할 확률은 0.00002 이다.
앞의 확률이 뒤의 확률보다 약 8.9배 크다는 것을 알 수있다.
그도 그럴 것이 solid는 단단한이라는 의미를 가졌으니까 증기라는 의미를 가진 steam보다는 당연히 얼음이라는 의미를 가진 ice와 더 자주 등장할 것이다.
Glove의 목적함수
우선 Glove에서는 임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 말뭉치(corpus)에서의 동시 등장 확률이 되도록 만드는 것이 목표이다. 이를 아래와 같이 표현 할 수 있다.
$dot\ product(w_{i}\ \tilde{w_{k}}) \approx\ P(k\ |\ i) = P_{ik}$
이제 우리는 이를 만족하는 임베딩 벡터를 찾기 위해 단어 간의 관계를 잘 표현하는 함수를 구해야한다. 우리가 찾고자 하는 함수 F는 아래와 같이 나타낼 수있다.
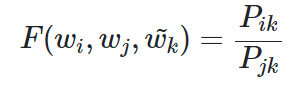
여기서 $P_{ik} = P(k \vert i)$를 의미한다. 즉 앞서 보았던 동시등장확률간비를 표현한 표를 참고하면, 아래와 같은 예시를 들 수 있다.
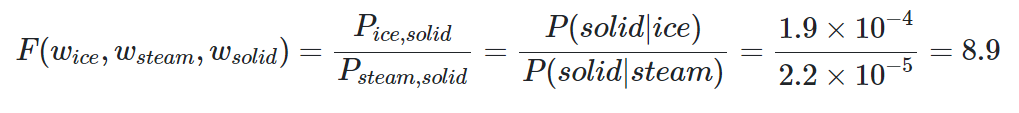
위 조건을 만족하는 F를 찾는 것이 목표이다.
GloVe 방법은 co-occurrent matrix를 찾기 위해 matrix decomposition을 해야하므로 계산복잡성이 커지는 단점이 있다.
다만 성능이 좋은 편에 속하며, 특히 수많은 단어에 대한 임베딩 벡터가 공개되어있기 때문에 실제로 활용하기 간편하다는 장점이 있다. (물론 Word2Vec도 임베딩 벡터 셋이 공개되어있다고 한다)