Basic of RNN

RNN은 기본적으로 동일한 모듈을 중심에 두고 input이 시간에 따라 변화하면서 들어가게 된다. 모듈 내에서 곱해지는 가중치가 시간에 따라 변하지 않는다는 점을 기억하도록 하자. 내부에서 출력과 직접적인 연관이 있는 hidden state의 값은 시간에따라 변화한다. hidden state는 과거의 정보를 기억 하는 역할을 한다.
RNN의 동작 과정
RNN의 동작 과정에 대해 살펴보자. 위의 예시처럼 반복적으로 활용되는 가중치 $W$가 RNN이라고 할 수 있으며, 해당 값은 아래 수식으로 표현될 수 있다.

$f_w$를 쪼개면 다음과 같이 표현 할 수 있다.
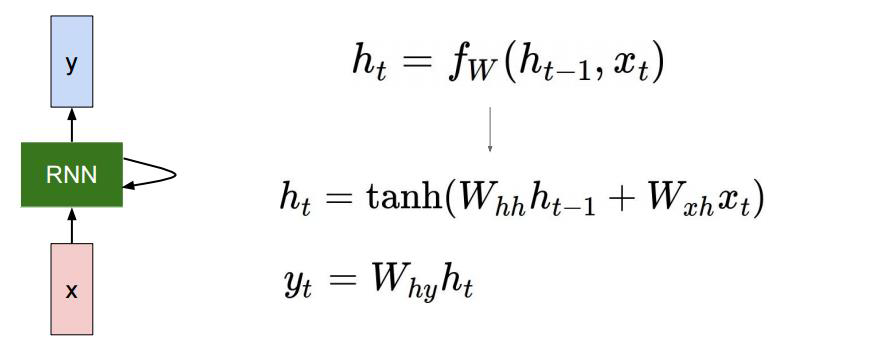
hidden state vecot가 가지는 차원 수는 hyper parameter로 우리가 직접 정해야 한다.
앞서 말했듯이 output이 필요한 경우 hidden state는 output layer의 가중치 $W_{hy}$와 곱해져나온 결과값이 된다. 원하는 것이 무엇이느냐에 따라 $y$의 차원 역시 달라진다. 만약 binary classification을 하고자 한다면 $y$는 scalar로 나올 것이고 multinomial classification을 하고자 한다면 class 갯수 만큼의 dimension을 가진 vector가 출력으로 나올 것이다.
이후 softmax를 통해 결과 값을 얻고, softmax loss등을 사용하여 학습을 할 수 있을 것이다.
RNN의 종류

One-to-one
- 엄밀히 말해 RNN 구조 라기 보다는 일반적인 신경망 구조이다.
- 사림의 키,몸무게,나이로 이뤄진 3차원 벡터를 입력 -> hidden-layer를 거친뒤
- 최종적으로 이사람의 혈압이 고혈압/정상/저혈압 3가지중 하나로 분류
one-to-many
- input 하나로 sequence output을 내놓는 구조.
- 이미지를에대한 설명들을 순차적으로 예측 또는 생성
- 입력이 첫번째 time step에만
many- to-one
- 입력을 각 time-step에서 받고
- 최종 출력을 마지막 time-step 에서만 한다.
- 감성분석에 사용될 수 있다.
many-to-many(1)
- 가장 상상하기 쉬운 RNN 모델
- 입력과 출력이 모두 sequence 형태
- 여기서는 input이 모두 들어올때까지 기다렸다가 다 읽고 output을 내놓는 형태이다.
- 기계 번역에 사용될 수있다.
mant-to-many(2)
- 입력이 될때마다 바로 바로 출력
- 각 단어별로 문장 성분이나 품사를 예측하는 경우에 활용 될 수 있다.
Character-level Language Model(예시)
RNN모델의 예시로 어떤 글자가 들어왔을 때 다음 글자를 맞힐 수 있는 모델을 떠올려 보자.

여기서는 hidden state의 dimension을 3으로 설정했고, 딕셔너리의 크기가 4이므로 hidden layer의 가중치 행렬의 shape를 3 x 7로 추측 할 수 있다.
첫번째 hidden layer의 input으로 들어가는 hidden state $h_0$는 3차원 영벡터로 주게 된다. (default는 이렇지만, 상황에 따라 다를 수 있다.)그리고 fully connected layer처럼, 실제로는 아래와 같이 bias term(b)이 각 layer에 들어간다.
$h_t = \tanh \left( W_{hh} h_{t-1} + W_{xh} x_t + b \right)$
$\text{Logit} = W_{hy} h_{t} + b$
output으로 나온 벡터는 softmax에 통과되어 확률로 변환된 후 이에 맞춰 예측 및 학습을 진행하게 된다. 단순하게 보면 아까 본 이미지에서 예측결과는 output vector에서 가장 큰 값을 가진 index가 된다. 예를 들어 첫번째 outpu의 예측결과는 [0,0,0,1]로 인코딩되는 'o'이다. 원래는 e가 와야하므로 틀린 값이며, softmax loss를 통해 학습을 진행한다.
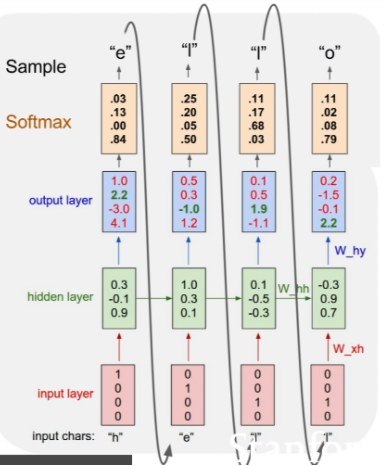
실제 추론(inference)시에는 위와 같이 이전의 output을 다음 input으로 넣어주게 된다.
지금까지 배운 character-level language model은 간단하게는 긴글부터, 코드, 논문 등에까지도 적용해볼 수 있다. 다만 글에서의 띄어쓰기, 쉼표, 줄바꿈 등을 모두 반영할 수 있도록 이 글자들도 딕셔너리에 추가되어야 한다. 마찬가지로 이를 코드에 적용한다면 indentation이나 괄호 등에 대한 규칙이 모두 학습되어야 한다.
Simple RNN(Vanlia RNN)의 문제점
- 기존 RNN에서는 sequence가 너무 길어지면 기울기가 vanishing/exploding될 우려가 있다. 이는 같은 값의 가중치 $W_{hh}$가 매 레이어마다 계속 곱해지면서 전달되기 때문에 발생하는 현상이다.

위의 예시에서는 3이 계속 곱해져 Gradient가 Exploding 될 수 있다.
RNN 실습 by pytorch
파이토치에서는 nn.RNN()을 통해 RNN셀을 구현 할 수 있습니다.
주요 Parameters
input_size: 입력 데이터의 input 사이즈, 보통 임베딩 사이즈hidden_size: 은닉층의 사이즈num_layers: Rnn의 은닉층 레이어 갯수, 기본 값 1bias: 바이어스 값 활성화 여부 기본 값 Truebatch_first: True일 시, output 값의 사이즈는 [배치사이즈, 문장 길이, hidden size]
input: input, h_0
input: [seq_len, batch_size, hidden_size], 만약 batch_size = True 라면, [batch_size, seq_len, hidden_size] 형태.hidden: [num_layers _num_directions, batch, hidden_size], *_batch_first 옵션과 무관**
output : output, h_n
output: [seq_len, batch_size, num_directions * hidden_size], 만약 batch_size = True 라면 [batch_size, seq_len, num_directions * hidden_size]h_n: [num_layers * num_directions, batch, hidden size]
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
# 입력 데이터
sentences = ["i like dog", "i love coffee", "i hate milk"]
# vocab 생성
vocab = list(set(' '.join(sentences).split()))
print('vocab : ', vocab)vocab : ['love', 'i', 'milk', 'like', 'coffee', 'dog', 'hate']# 각 단어에 고유 인덱스 부여
word2index ={tkn : i for i, tkn in enumerate(vocab)}
print('word2index : ', word2index)word2index : {'love': 0, 'i': 1, 'milk': 2, 'like': 3, 'coffee': 4, 'dog': 5, 'hate': 6}# 수치화된 데이터를 단어로 바꾸기 위한 사전
# word2index의 반대 개념
index2word = {v: k for k, v in word2index.items()}
print('index2word : ', index2word)index2word : {0: 'love', 1: 'i', 2: 'milk', 3: 'like', 4: 'coffee', 5: 'dog', 6: 'hate'}def make_batch(sentences,word2index,input_size):
"""
배치를 만드는 함수 이번 예제에서는
파라미터
---
sentences : list
각 단어가 들어있는 list
word2index : dict
단어 별 고유 인덱스가 매핑 되어 있는 dict
input_size : int
vocab의 사이즈
returns
---
input_batch : list
입력 데이터, 문장중 가장 마지막 단어를 제외한 모든 단어
target_batch : list
target 데이터, 문장의 가장 마지막 단어
"""
input_batch = []
target_batch = []
for sen in sentences:
# 단어를 공백을 기준으로 split
word = sen.split()
# 문장 중 가장 마지막 단어를 제외한 모든 단어를 input 으로
# word2index를 이용하여 input의 각 단어를 고유 인덱스 매핑
input = [word2index[n] for n in word[:-1]]
# 문장 중 가장 마지막 단어를 target으로
# word2index를 이용하여 target 단어를 고유 인덱스 매핑
target = word2index[word[-1]]
input_batch.append(np.eye(input_size)[input])
target_batch.append(target)
return input_batch, target_batchclass Net(nn.Module):
"""
간단한 rnn 함수
2개의 단어를 input으로 받아서 다음에 올 단어를 예측하는 모델
"""
def __init__(self,input_size,hidden_size, output_size):
super(Net,self).__init__()
self.rnn = nn.RNN(input_size = input_size, hidden_size = hidden_size,
batch_first = True)
self.linear = nn.Linear(hidden_size, output_size) # 출력은 단어 집합의 크기로 지정
def forward(self, x):
# rnn모델의 출력 값은 입력 데이터에 대한 출력과
# 다음 rnn셀로 보낼 hidden state
output, hidden = self.rnn(x)
# input 단어가 2개이기 때문에 2개 단어에 대한 출력 벡터가 생성되는데
# 2번째 단어(마지막으로 입력된 단어)의 출력 벡터만 사용
output = output[:,-1,:]
output = self.linear(output)
return outputinput_size = 7
hidden_size = 8
output_size = 7
model = Net(input_size,hidden_size,output_size)input_batch, target_batch = make_batch(sentences,word2index,input_size)
input_batch = torch.FloatTensor(input_batch)
target_batch= torch.LongTensor(target_batch)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr = 0.001)# Training
for epoch in range(5000):
optimizer.zero_grad()
# input_batch : [batch_size, n_step, n_class]
output = model(input_batch)
# output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()Epoch: 1000 cost = 0.076399
Epoch: 2000 cost = 0.017108
Epoch: 3000 cost = 0.007024
Epoch: 4000 cost = 0.003501
Epoch: 5000 cost = 0.001906predict = model(input_batch)
predicttensor([[-3.3083, 0.7306, 1.5619, -3.1968, -2.5974, -4.0368, 11.4551],
[-3.1389, 8.7950, -2.1982, -3.7065, -3.1166, -3.9962, -1.8720],
[-3.4346, -1.5432, 9.2117, -3.2313, -3.8037, -3.7866, -0.8816]],
grad_fn=<AddmmBackward>)torch.argmax(predict,axis = 1).tolist()[6, 1, 2]for i in torch.argmax(predict,axis =1).tolist():
print(index2word[i])dog
coffee
milkReference
Basic of RNN
RNN은 기본적으로 동일한 모듈을 중심에 두고 input이 시간에 따라 변화하면서 들어가게 된다. 모듈 내에서 곱해지는 가중치가 시간에 따라 변하지 않는다는 점을 기억하도록 하자. 내부에서 출력과 직접적인 연관이 있는 hidden state의 값은 시간에따라 변화한다. hidden state는 과거의 정보를 기억 하는 역할을 한다.
RNN의 동작 과정
RNN의 동작 과정에 대해 살펴보자. 위의 예시처럼 반복적으로 활용되는 가중치 $W$가 RNN이라고 할 수 있으며, 해당 값은 아래 수식으로 표현될 수 있다.
$f_w$를 쪼개면 다음과 같이 표현 할 수 있다.
hidden state vecot가 가지는 차원 수는 hyper parameter로 우리가 직접 정해야 한다.
앞서 말했듯이 output이 필요한 경우 hidden state는 output layer의 가중치 $W_{hy}$와 곱해져나온 결과값이 된다. 원하는 것이 무엇이느냐에 따라 $y$의 차원 역시 달라진다. 만약 binary classification을 하고자 한다면 $y$는 scalar로 나올 것이고 multinomial classification을 하고자 한다면 class 갯수 만큼의 dimension을 가진 vector가 출력으로 나올 것이다.
이후 softmax를 통해 결과 값을 얻고, softmax loss등을 사용하여 학습을 할 수 있을 것이다.
RNN의 종류
One-to-one
- 엄밀히 말해 RNN 구조 라기 보다는 일반적인 신경망 구조이다.
- 사림의 키,몸무게,나이로 이뤄진 3차원 벡터를 입력 -> hidden-layer를 거친뒤
- 최종적으로 이사람의 혈압이 고혈압/정상/저혈압 3가지중 하나로 분류
one-to-many
- input 하나로 sequence output을 내놓는 구조.
- 이미지를에대한 설명들을 순차적으로 예측 또는 생성
- 입력이 첫번째 time step에만
many- to-one
- 입력을 각 time-step에서 받고
- 최종 출력을 마지막 time-step 에서만 한다.
- 감성분석에 사용될 수 있다.
many-to-many(1)
- 가장 상상하기 쉬운 RNN 모델
- 입력과 출력이 모두 sequence 형태
- 여기서는 input이 모두 들어올때까지 기다렸다가 다 읽고 output을 내놓는 형태이다.
- 기계 번역에 사용될 수있다.
mant-to-many(2)
- 입력이 될때마다 바로 바로 출력
- 각 단어별로 문장 성분이나 품사를 예측하는 경우에 활용 될 수 있다.
Character-level Language Model(예시)
RNN모델의 예시로 어떤 글자가 들어왔을 때 다음 글자를 맞힐 수 있는 모델을 떠올려 보자.
여기서는 hidden state의 dimension을 3으로 설정했고, 딕셔너리의 크기가 4이므로 hidden layer의 가중치 행렬의 shape를 3 x 7로 추측 할 수 있다.
첫번째 hidden layer의 input으로 들어가는 hidden state $h_0$는 3차원 영벡터로 주게 된다. (default는 이렇지만, 상황에 따라 다를 수 있다.)그리고 fully connected layer처럼, 실제로는 아래와 같이 bias term(b)이 각 layer에 들어간다.
$h_t = \tanh \left( W_{hh} h_{t-1} + W_{xh} x_t + b \right)$
$\text{Logit} = W_{hy} h_{t} + b$
output으로 나온 벡터는 softmax에 통과되어 확률로 변환된 후 이에 맞춰 예측 및 학습을 진행하게 된다. 단순하게 보면 아까 본 이미지에서 예측결과는 output vector에서 가장 큰 값을 가진 index가 된다. 예를 들어 첫번째 outpu의 예측결과는 [0,0,0,1]로 인코딩되는 'o'이다. 원래는 e가 와야하므로 틀린 값이며, softmax loss를 통해 학습을 진행한다.
실제 추론(inference)시에는 위와 같이 이전의 output을 다음 input으로 넣어주게 된다.
지금까지 배운 character-level language model은 간단하게는 긴글부터, 코드, 논문 등에까지도 적용해볼 수 있다. 다만 글에서의 띄어쓰기, 쉼표, 줄바꿈 등을 모두 반영할 수 있도록 이 글자들도 딕셔너리에 추가되어야 한다. 마찬가지로 이를 코드에 적용한다면 indentation이나 괄호 등에 대한 규칙이 모두 학습되어야 한다.
Simple RNN(Vanlia RNN)의 문제점
- 기존 RNN에서는 sequence가 너무 길어지면 기울기가 vanishing/exploding될 우려가 있다. 이는 같은 값의 가중치 $W_{hh}$가 매 레이어마다 계속 곱해지면서 전달되기 때문에 발생하는 현상이다.
위의 예시에서는 3이 계속 곱해져 Gradient가 Exploding 될 수 있다.
RNN 실습 by pytorch
파이토치에서는 nn.RNN()을 통해 RNN셀을 구현 할 수 있습니다.
주요 Parameters
input_size: 입력 데이터의 input 사이즈, 보통 임베딩 사이즈hidden_size: 은닉층의 사이즈num_layers: Rnn의 은닉층 레이어 갯수, 기본 값 1bias: 바이어스 값 활성화 여부 기본 값 Truebatch_first: True일 시, output 값의 사이즈는 [배치사이즈, 문장 길이, hidden size]
input: input, h_0
input: [seq_len, batch_size, hidden_size], 만약 batch_size = True 라면, [batch_size, seq_len, hidden_size] 형태.hidden: [num_layers _num_directions, batch, hidden_size], *_batch_first 옵션과 무관**
output : output, h_n
output: [seq_len, batch_size, num_directions * hidden_size], 만약 batch_size = True 라면 [batch_size, seq_len, num_directions * hidden_size]h_n: [num_layers * num_directions, batch, hidden size]
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
# 입력 데이터
sentences = ["i like dog", "i love coffee", "i hate milk"]
# vocab 생성
vocab = list(set(' '.join(sentences).split()))
print('vocab : ', vocab)vocab : ['love', 'i', 'milk', 'like', 'coffee', 'dog', 'hate']# 각 단어에 고유 인덱스 부여
word2index ={tkn : i for i, tkn in enumerate(vocab)}
print('word2index : ', word2index)word2index : {'love': 0, 'i': 1, 'milk': 2, 'like': 3, 'coffee': 4, 'dog': 5, 'hate': 6}# 수치화된 데이터를 단어로 바꾸기 위한 사전
# word2index의 반대 개념
index2word = {v: k for k, v in word2index.items()}
print('index2word : ', index2word)index2word : {0: 'love', 1: 'i', 2: 'milk', 3: 'like', 4: 'coffee', 5: 'dog', 6: 'hate'}def make_batch(sentences,word2index,input_size):
"""
배치를 만드는 함수 이번 예제에서는
파라미터
---
sentences : list
각 단어가 들어있는 list
word2index : dict
단어 별 고유 인덱스가 매핑 되어 있는 dict
input_size : int
vocab의 사이즈
returns
---
input_batch : list
입력 데이터, 문장중 가장 마지막 단어를 제외한 모든 단어
target_batch : list
target 데이터, 문장의 가장 마지막 단어
"""
input_batch = []
target_batch = []
for sen in sentences:
# 단어를 공백을 기준으로 split
word = sen.split()
# 문장 중 가장 마지막 단어를 제외한 모든 단어를 input 으로
# word2index를 이용하여 input의 각 단어를 고유 인덱스 매핑
input = [word2index[n] for n in word[:-1]]
# 문장 중 가장 마지막 단어를 target으로
# word2index를 이용하여 target 단어를 고유 인덱스 매핑
target = word2index[word[-1]]
input_batch.append(np.eye(input_size)[input])
target_batch.append(target)
return input_batch, target_batchclass Net(nn.Module):
"""
간단한 rnn 함수
2개의 단어를 input으로 받아서 다음에 올 단어를 예측하는 모델
"""
def __init__(self,input_size,hidden_size, output_size):
super(Net,self).__init__()
self.rnn = nn.RNN(input_size = input_size, hidden_size = hidden_size,
batch_first = True)
self.linear = nn.Linear(hidden_size, output_size) # 출력은 단어 집합의 크기로 지정
def forward(self, x):
# rnn모델의 출력 값은 입력 데이터에 대한 출력과
# 다음 rnn셀로 보낼 hidden state
output, hidden = self.rnn(x)
# input 단어가 2개이기 때문에 2개 단어에 대한 출력 벡터가 생성되는데
# 2번째 단어(마지막으로 입력된 단어)의 출력 벡터만 사용
output = output[:,-1,:]
output = self.linear(output)
return outputinput_size = 7
hidden_size = 8
output_size = 7
model = Net(input_size,hidden_size,output_size)input_batch, target_batch = make_batch(sentences,word2index,input_size)
input_batch = torch.FloatTensor(input_batch)
target_batch= torch.LongTensor(target_batch)criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr = 0.001)# Training
for epoch in range(5000):
optimizer.zero_grad()
# input_batch : [batch_size, n_step, n_class]
output = model(input_batch)
# output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()Epoch: 1000 cost = 0.076399
Epoch: 2000 cost = 0.017108
Epoch: 3000 cost = 0.007024
Epoch: 4000 cost = 0.003501
Epoch: 5000 cost = 0.001906predict = model(input_batch)
predicttensor([[-3.3083, 0.7306, 1.5619, -3.1968, -2.5974, -4.0368, 11.4551],
[-3.1389, 8.7950, -2.1982, -3.7065, -3.1166, -3.9962, -1.8720],
[-3.4346, -1.5432, 9.2117, -3.2313, -3.8037, -3.7866, -0.8816]],
grad_fn=<AddmmBackward>)torch.argmax(predict,axis = 1).tolist()[6, 1, 2]for i in torch.argmax(predict,axis =1).tolist():
print(index2word[i])dog
coffee
milk