
GPT-1
GPT 1은 Transformer 구조에서 디코더 부분을 활용한 모델 구조 입니다.
원본 논문
해당 논문에서는 라벨링 되지 않은 텍스트 데이터를 이용하여 모델을 pre-training 시킨 후 특정 task에 맞춤 fine-tunning 하는 방식을 제안합니다.
또한 GPT는 두가지 학습단계 1) Unsupervised pre-training, 2)supervised fine-tunning을 활용하여 모델구조를 최소한으로 변화시키고, fine-tuning 단게에서 과제에 맞는 Input representations을 사용 하였습니다.
여러 실험을 통해 해당 모델은 당시 12개의 task 중 9개에서 SOTA 수준의 성능을 발휘 하였습니다.
GPT-1에서는 <S>, <E>, <Delim> 등 다양한 special token을 활용하여 fine-tuning 시의 성능을 끌어 올렸습니다.
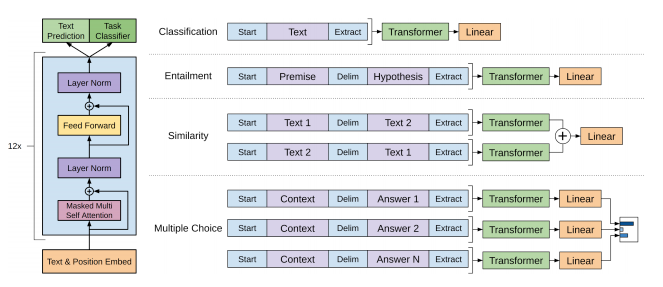
( 출처 : https://towardsdatascience.com/i-didnt-write-this-article-alone-bc604e50859c )
위 사진을 살펴보면 기존 처럼 문장의 시작에는 Start token을 넣어주고, 문장의 끝에는 Extract toekn을 넣어 주었다. 여기서 extract token은 EOS 기능 뿐만 아니라 이후 downwrad task의 query 벡터로 활용 된다.
Classfication
- 사진의 첫번째 task인 분류 문제를 푼다고하면, transformer 구조의 마지막 output으로 나온 extrack token을 별도의 linear layer에 통과 시켜 분류를 수행함.
Entailment
- text Entailment는 Delim(delimiter) token이 활용되는데, 해당 토큰은 서로 다른 두 문장을 이어주는 역할을 함.
- 두 문장을 각각 넣지 않고 Delim 토큰을 이용해 한번에 넣음.
Similarity
- 두 개의 텍스트의 순서가 없으므로 텍스트 2개를 다른 순서로 이어 붙여 2개 모두 입력으로 사용.
Multiple Choice
문맥 문서 z,질문 q,가능한 답변 a_k라 하면 [z; q; delim token; a_k]로 연결하고 input 개수는 답변의 갯수만큼 생성
GPT의 이러한 input 구조의 장점은 transformer 구조를 별도의 학습 없이 여러 task에서 활용가능하다는 것이다.
사용자는 down-stream task를 위한 마지막 linear layer만 별도로 학습 시켜(fine-tunning) 원하는 task에 활용하면 된다.
다만 구조를 더 깊게 들여다보면 사실 transformer(pre-training model) 부분도 학습을 진행한다.
다만 fine tuning 부분에 비해 상대적으로 learning rate를 매우 작게 주어 거의 학습을 시키지 않고, fine tuning 부분에 learning rate를 크게 주어 이 부분을 중점적으로 학습 시킨다.
이때 수행하고자 하는 task에 대한 데이터가 거의 없을 때 pre-training model만 대규모의 데이터로 학습시킬 수 있다면 어느정도 target task에도 성능이 보장된다.즉, pre-training model의 지식을 fine tuning부분에 자연스럽게 전이학습시킬 수 있다.
(출처 : https://hwk0702.github.io)
GPT-1에서 활용한 구조를 더 자세히 보면 다음과 같은 특징이 있다.
- 12개의 decoder-only transformer layer 활용
- 12개의 multihead
- 인코딩 벡터의 차원 768
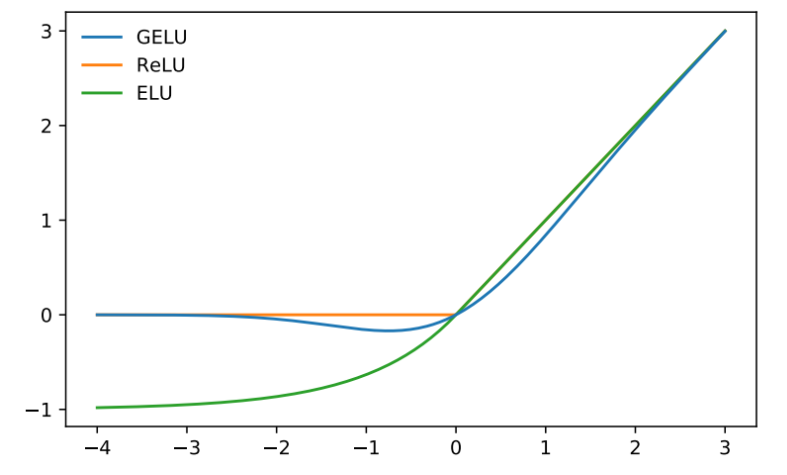
- ReLu와 비슷한 생김새를 가진
GELU 활성화 함수사용
reference
https://simonezz.tistory.com/73
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
'딥러닝 > NLP' 카테고리의 다른 글
| GPT-2/GPT-3 (0) | 2021.03.20 |
|---|---|
| BERT (0) | 2021.03.20 |
| Transformer (0) | 2021.03.18 |
| BLEU (0) | 2021.03.18 |
| Seq2Seq (0) | 2021.03.17 |