GPT-2/GPT-3
GPT-2,GPT-3는 GPT-1에 이어 OpenAI에서 발표한 GPT-n 시리즈의 후속 모델로, 사용하는 도구 면에서는 크게 달라진 것이 없다. 다만 transformer layter의 크기를 더욱 늘리고 몇가지 추가 하였다.
GPT-2
이전처럼 다음 단어를 예측하는 language modeling으로 학습시킨 pre-trainig model이 zero-shot setting으로 down-stream task를 수행할수 있게 되었다.
zero-shot setting이란 원하는 task를 위한 별도의 예제를 주지 않고 task에 대한 지시사항만을 모델에 전달하는 것을 말한다. 앞서 본 독해기반 질의응답으로 모든 task를 수행 할 수있다.
Dataset으로는 BPE(Byte Pair Encoding) token을 사용하였고 Reddit에서 up-vote가 3개 이상인 글에 걸려있는 링크(즉, 사람에 의해 필터링된)를 총 4500만개 긁어와서 이를 모델 학습에 이용하였다. 그 외에도 위키피디아 문서 등을 이용하였는데 이와 같이 크롤링을 하되 많은 사람들에게 인정받아 신빙성이 보장될만한 글들을 모두 학습에 이용하였다. 이에 따라 training data의 양과 질을 모두 향상 시킬 수 있었다.
모델의 측면에서는 앞서 말했듯이 절대적인 레이어의 양을 늘렸다. 또한 layer normalization의 위치가 변경된 부분이 있고, 위쪽(깊은) 레이어일수록 weight parameter를 작게(1/√n 배,n은 residual layer의 수)하여 위쪽에 잇는 레이어의 역할이 줄어들 수 있도록 구성되었다.
이 부분을 좀 더 자세히 들여다보면 결국 scalilng은 분산을 강제로 조절해주기 위해 사용된다. 모델 내에서 모든 계산은 곱셈과 덧셈이 반복되는 구조로 이루어져있고, rsidual layer를 거칠수록 input이 뒤에 더해지면서 exploding, vanishin이 일어날 우려가 있다. 그래서 애초에 residual layer의 weight을 scaling해줌으로써 위와 같은 일이 벌어지지 않도록 막아주는 것이다.
GPT-3
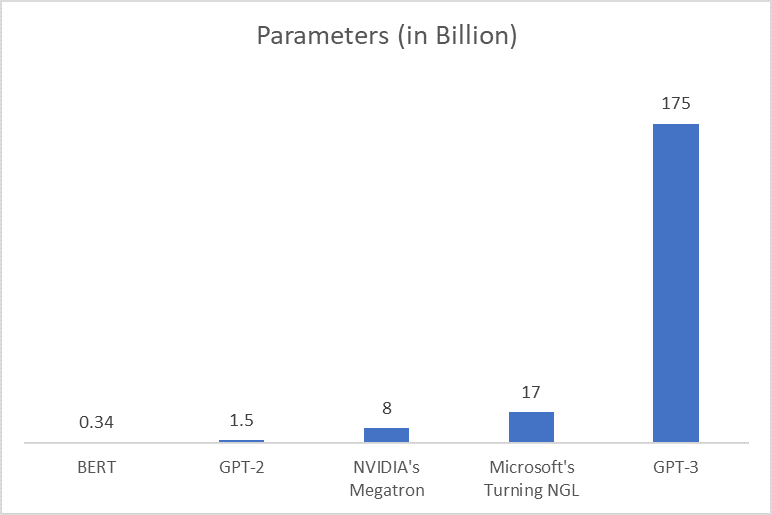
GPT-3에서는 GPT-2에서보다도 모델의 규모를 늘렸다. 약 1750억개의 paramter를 포함한 96개의 attention layer를 사용하였고 batch size를 320만개로 늘렸다. 또한 few-shot setting으로 별도의 학습 없이 소량의 test data로도 원하는 답을 내놓을 수 있게 되었다.

위 그림과 같이 fine-tuning 없이 inference 과정에서 예시만을 주면 모델이 적절한 답을 내놓을 수 있게 된다. 한편, zero-shot, one-shot, few-shot 등 여기에도 줄 데이터의 수를 조절하면서 줘볼 수 있는데 아래 그래프와 같이 few-shot에서 parameter수가 늘어날 수록 더 높은 폭의 성능 향상을 보여주었다.
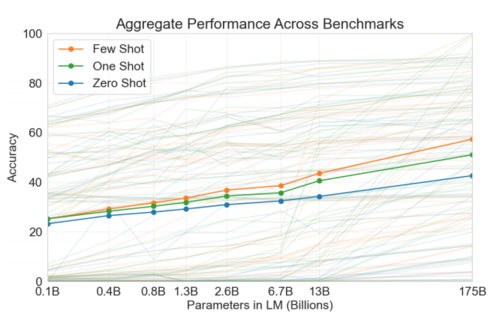
pre-training 모델은 모델 사이즈가 커지면 계속해서 성능이 더 좋아진다. 특히 few-shot을 적용하면 zero-shot이나 one-shot에 비해 상대적으로 그 정확도가 더 빨리 올라가는것을 확인 할 수 있다.