ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacments Accurately)
ECECTRA는 BERT의 파생 모델 중 하나이다.
BERT의 경우 MLM과 NSP 태스크를 사용해 사전 학습을 진행한다. MLM 태스크는 전체 토큰의 15%를 무작위로 마스킹한 후 해당 토큰을 예측하는 방식으로 진행한다.
MLM 태스크를 사전 학습에 사용하는 대신 ELECTRA는 replaced toekn detection라는 태스크를 사용해 학습을 진행한다.
replaced toekn detection는 마스킹 대상인 토큰을 다른 토큰으로 변경한 후 이 토큰이 실제 토큰인지 아니면 교체한 토큰인지를 판별하는 형태로 학습을 진행한다.
그렇다면 MLM 태스크 대신 replaced toekn detection를 사용하는 이유는 무엇일까 ?
MLM 태스크의 문제 중 하나는 사전 학습 중에는 [MLM]] 토큰을 사용하지만 파인 튜닝 태스크에서는 [MASK] 토큰을 사용하지 않는 다는 점이다.
이로 인해 사전 학습과 파인 튜닝 사이에 토큰에 대한 불일치가 생길 수 있다. 그 대신 토큰을 다른 토큰으로 교체하고 주어진 토큰이 실제 토큰인지 아니면 대체된 토큰인지를 분류하도록 모델을 학습시키는 것이다. 이와 같은 방법을 적용하면 사전 학습과 파인 튜닝 사이의 불일치 문제를 해결할 수 있다.
replaced toekn detection 이해하기
replaced toekn detection를 이해하기 위해 The chef cooked the meal문장을 예시로 이해해보자.
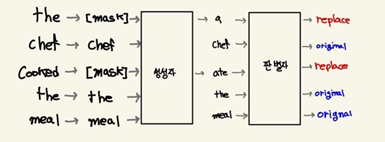
- 생성자 : MLM 태스크 수행 -> 15% 확률로 전체 토큰을 마스크된 토큰으로 교체하고 생성기에서 마스크된 토큰을 예측하도록 학습을 진행
- 판별자 : 주어진 토큰이 변경 되었는지 아니면 원본인지 여부 판별
BERT와 비교했을때 ELECTRA 장점
BERT의 MLM태스크의 경우 전체 토큰의 15%만 마스킹한 후 학습을 진행한다. 그래서 모델 학습은 15%의 마스크된 토큰만 예측하는 것을 주목적으로한다.
하지만 ELECTRA는 주어진 토큰의 원본 여부를 판별하는 방법으로 학습을진행하기 때문에 모든 토큰을 대상으로 학습이 이뤄진다.
ELECTRA의 효율적인 학습
ELECTRA 모델을 효율적으로 학습시키기 위해서 생성자와 판별자의 가중치를 공유한다. 즉, 생성자와 판별자 크기가 같다면 인코더의 가중치를 공유할 수 있다.
하지만 생성자와 판별자를 같은 크기로 하면 학습 시간이 늘어난다. 따라서 이와 같은 형상을 막기 위해 생성자 크기를 작게 해 모델 학습을 진행한다.
만약 생성자 크기가 작으면, 임베딩 레이어를 생성자와 판별자가 서로 공유할 수 있다. 이렇게 하면 임베딩의 학습 시간을 줄일 수 있다.
ELECTRA 모델은 3가지 형태로 사용가능하다.
- ELECTRA-small : 12개의 인코더와 은닉 크기 256로 구성
- ELECTRA-base : 12개의 인코더와 은닉 크기 768로 구성
- ELECTRA-large : 24개의 인코더와 은닉 크기 1,024로 구성
'딥러닝 > NLP' 카테고리의 다른 글
| bertsum (0) | 2022.01.26 |
|---|---|
| ROUGE 이해하기 (0) | 2022.01.25 |
| RoBERTa (0) | 2022.01.23 |
| ALBERT (2) | 2021.03.20 |
| GPT-2/GPT-3 (0) | 2021.03.20 |