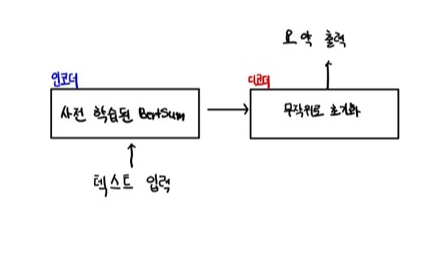
BERTSUM
BERTSUM이란 텍스트 요약에 맞춰 파인 튜닝된 BERT 모델이다.
텍스트 요약
텍스트 요약에는 2가지 유형이 있다.
- 추출 요약
- 생성 요약
추출 요약
추출 요약은 주어진 텍스트에서 중요한 문장만 추출해 요약하는 과정을 의미한다.
즉, 많은 문장이 포함된 긴 문서에서 문서의 본질적인 의미를 담고 있는 중요한 문장만 추출해 문서의 요약을 생성하는 것이다.
BERT를 활용한 추출 요약
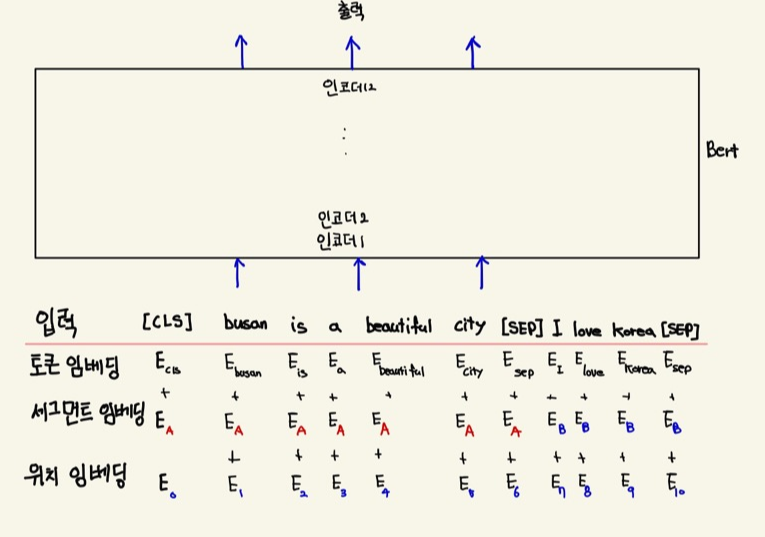
busan is beautiful city.와 i love korea라는 문장이 있다고 가정해보자.
- 입력 문장을 토큰 형태로 변경
- 첫 문장의 시작 부분에만 [CLS] 토큰 추가
- 문장의 마지막 부분에 [SEP] 토큰 추가
이것을 토큰 임베딩, 세그먼트 임베딩, 위치 임베딩 이렇게 3개의 임베딩 레이어 형태로 변환한다.
아래 이미지는 세 가지 입력값을 받은 BERT모델이다.
그렇다면, 텍스트 요약 태스크에 BERT를 어떻게 사용할 수 있을까 ? ?
요약 태스크에서는 모든 토큰의 표현이 필요하지 않고, 모든 문장의 표현이 필요하다.
추출 요약은 전체 텍스트 중 중요한 문장만 선택하는 task이다. 문장의 표현이라는 것은 문장이 갖는 의미를 표현한 형태이다.
즉, 모든 문장의 표현을 통해 문장의 중요성 여부를 결정할 수 있다.
따라서 BER를 통해 모든 문장의 표현을 얻으면 표현을 분류기에 넣은 후 분류기를 통해 문장의 중요성 여부를 판단할 수 있다.
문장의 표현을 얻기 위해서는 모든 문장의 시작 부분에 [CLS] 토큰을 추가해 주면 된다. 그리고 각 문장은 마찬가지로 [SEP] 토큰으로 분리한다.
str one,str two,str three 이렇게 세 개의 문장이 있다고 할 때 입력값이 어떻게 변환되는지 알아보자.
우선 토큰 임베딩과 위치 임베딩은 기존과 동일하게 진행한다.
그러나 세그먼트 임베딩은 조금 다르게 적용해야 되는데, 그 이유는 세그먼트 임베딩의 경우 단어를 $E_A$ 또는 $E_B$형태로 반환해야 되지만 문장이 2개 이상일 경우가 보통이기 때문이다.
이와 같은 경우 인터벌 세그먼트 임베딩을 사용해주면 된다. 인터벌 세그먼트 임베딩은 **홀수 번째 문장에서 발생한 토큰은 $E_A$에, 짝수번째 문장에서 발생한 토큰은 $E_B$에 매핑시켜준다.
아래 그림은 입력 데이터의 형태이다.

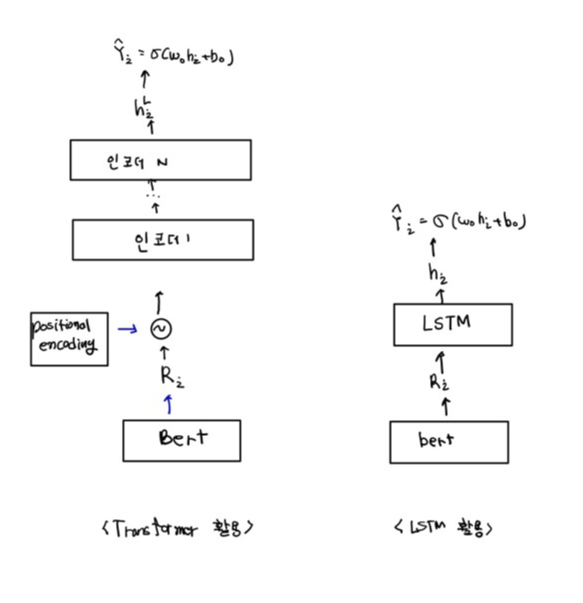
이제 이 세 가지 형태의 입력 데이터를 BERT 모델에 제공한다. BERT 모델은 입력 데이터를 받아 모든 토큰의 표현을 출력 값으로 반환한다.
그림에서 알 수 있듯이 $R_1$은 문장 1, $R_2$는 문장 2, $R_3$는 문장 3에 대한 표현을 의미한다.

그렇다면 이러한 방법을 이용해서 추출 요약 태스크에 어떻게 적용할 수 있을까 ?? 바로 아래 그림처럼 분류기를 이어 붙여 추출 요약 태스크에 이용하면 된다.

분류기에는 아래 그림처럼 각 문장의 표현이 입력값으로 들어가게 되고, 해당 문장을 사용 여부를 출력하여 생성 요약 문을 만들 게 된다.
생성 요약
생성 요약은 추출 요약과 다르게 주어진 텍스트에서 중요한 문장만 추려 문장을 생성하지 않는다. 그 대신 주어진 텍스트를 의역해 요약을 만든다.
여기서 의역이란 텍스트의 의미를 좀 더 명확하게 나타내기 위해서 다른 단어를 사용해 주어진 텍스트를 새롭게 표현하는 것을 말한다.
따라서 생성 요약에서는 주어진 텍스트의 의미만 지닌 다른 단어를 사용해 주어진 텍스트를 새로운 문장으로 표현한다.
BERT를 사용한 생성 요약
생성 요약을 수행하는 데는 트랜스포머의 인코더-디코더 아키텍처를 사용한다. 텍스트를 인코더에 입력하면 인코더는 주어진 텍스트에 대한 표현을 출력한다.
인코더의 출력 값을 디코더에 입력하면, 디코더는 이 입력값을 사용해 요약을 생성한다.
사전 학습된 BERTSUM 모델(인코더)은 의미 있는 표현을 생성하고, 디코더는 이 표현을 사용해 요약을 생성하는 방법을 학습한다.
하지만 여기에 한 가지 문제가 있다. 지금 사용하는 트랜스포머 모델은 인코더가 사전 학습된 BERTSUM 모델이지만 디코더는 무작위로 초기화되어 있다. 이로 인해 파인 튜닝 중에 불일치가 발생한다.
인코더가 이미 사전 학습되었기 때문에 과적합될 수 있고, 디코더가 사전 학습되지 않았기 때문에 과소 적합이 일어날 수 있다.
이를 해결하기 위해 옵티마이저를 인코더와 디코더에 개별적으로 사용한다. 또한 인코더와 디코더는 서로 다른 학습률을 사용한다.
인코더는 이미 사전 학습되어서 인코더에는 학습률을 줄이고 좀 더 sommth 하게 감소하도록 설정한다.