object detction - SSD
obejct detection 이란 한 장의 사진에 포함된 여러 물체에 대해 영역과 이름을 확인하는 작업입니다. 아래 이미지는 object detection의 결과입니다.

사람과 야구 방망이에 각각 테두리가 표시되어 있습니다. 물체의 위치를 나타내는 테두리를 bounding box라고 하고, 테두리의 왼쪽 상단에는 라벨명이 나오며 숫자가 함께 출력됩니다.
숫자는 해당 라벨의 정확도(신뢰도)를 의미합니다.
SSD를 활용한 object detection의 순서는 다음과 같습니다.
해당 순서는 SSD300의 경우입니다.
- 300 x 300으로 이미지 resize
- 픽셀을 300 X 300으로 리사이즈하고 색 정보의 표준화 적용
- 디폴트 박스 8,732개 준비
- 다양한 크기 및 비율의 디폴트 박스를 준비
- SSD는 8,732개의 디폴트 박스를 준비
- SSD 네트워크에 이미지 입력
- 전처리한 이미지를 SSD에 입력. 8,732개의 각 디폴트 박스를 바운딩 박스로 수정하는 오프셋 정보 4 변수와 디폴트 박스가 각 클래스의 물체인 신뢰도 21개의 합계 8,732 * (4+21) = 218,300 개의 정보를 출력한다
- 여기서 21은 타겟 LABEL의 종류의 수가 21이라 그런 것이다.
- 신뢰도 높은 디폴트 박스 추출
- 8,732개의 디폴트 박스 중 신뢰도 높은 것을 상위에서 TOP_K(SSD300에서느 200)추출
- 디폴트 박스에 대응하는 레벨은 그중에서도 신뢰도가 가장 높은 클래스
- 오프셋 정보로 수정 및 중복 제거
- 오프셋 정보를 사용하여 디폴트 박스를 바운딩 박스로 변형. 4번째 단계에서 꺼낸 TOK_k개의 디폴트 박스 중 바운딩 박스와 겹치는 것(같은 물체를 감지한 것으로 보이는)이 많다면 가장 신뢰도 높은 디폴트 박스만 남김
- 일정 신뢰도 이상을 최종 출력으로 선정
- 최종 바운딩 박스와 라벨 출력. 신뢰도의 임계치를 결정하여 그 이상의 신뢰도를 가진 바운딩 박스만 최종적으로 출력.
object detection의 입력과 출력
object detection의 입력은 이미지입니다. 출력은 다음과 같습니다.
- 이미지 어디에 물체가 존재하는지 나타내는 바운딩 박스의 위치와 크기 정보
- 각 바운딩 박스가 어떤 물체인지 나타내는 라벨 정보
- 라벨의 신뢰도
SSD 알고리즘은 바운딩 박스 중심의 좌표(cx, cy)와 바운딩 박스의 너비 w, 바운딩 박스의 높이 h로 바운딩 박스를 표현합니다.
또한 라벨 정보는 감지하려는 물체의 클래스 수 X에 어떠한 물체도 아닌 배경 클래스(background)를 더해 총 X+1 종류의 클래스로 각 바운딩 박스당 하나의 라벨을 구합니다.
라벨의 신뢰도는 각 바운딩 박스와 라벨에 대한 신뢰도를 보여줍니다. 물체 감지는 신뢰도가 높은 바운딩 박스만 최종 출력합니다.
- 이미지 데이터를 불러올 때 OpenCV를 사용하는데 OpenCV로 이미지를 불러올 때는
높이/폭/색상(BGR) 순으로불러옵니다. 색상 채널이 RGB가 아닌 BGR로 이미지를 불러온다.
Object Detection 알고리즘 소개
R-CNN
- R-CNN에 대한 논문에서는 아래와 같은 프로세스를 제시합니다.
- Input image에서 Selective search라는 알고리즘을 이용해 후보 2000개의 box들(regional proposal)을 검출
- CNN(AlexNet)을 통해 각 이미지마다 4096차원의 특성 벡터를 도출
- 단, output의 size를 같게 해줘야 하므로 모든 regional proposal의 크기를 정해진 같은 사이즈로 warping 해준다.
- SVM을 이용하여 해당 박스에 대한 클래스를 예측한다.
SPPNET(Spatial Pyramid Pooling)
- R-CNN에서는 후보 2000개에 대하여 모두 CNN을 한 번씩 돌려야 했기 때문에 시간이 너무 오래 걸림.
- 그래서 SPPNet에서는 CNN을 한번만 돌린다. 순서는 아래와 같다.
- Selective search로 똑같이 후보를 먼저 찾는다.
- CNN을 돌려 나온 feture map(output)에서 각각의 bounding box영역의 patch를 뜯어온다. inputsize를 고정해줄 필요가 없으므로 warp과정이 필요 없다.
- SVM을 이용하여 각 박스에 대한 클래스를 예측한다.
- 위 과정은 매우 축약된 과정으로, 실제로는 더 복잡하다.

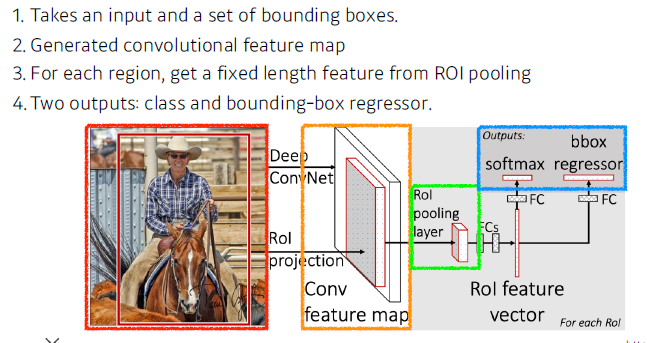
Fast R-CNN
- Fast R-CNN은 R-CNN의 단점(2000번의 CNN, 여러 모델에서 학습)을 극복한 기법이다. 순서는 다음과 같다.
- Selective search로 regional proposal 추출
- CNN을 돌려 feature map를 얻어옴(SPPNet와 여기까지 동일)
- 각 region마다 pooling을 진행하며 고정된 크기의 feature vector를 가져옴
- feature vector를 affine layer에 통과시켜 두 output(class, bounding box regressor)을 얻는다.
- class는 softmax를 통과시켜 분류를 적용하고, bounding box는 bounding box regression을 통해 box의 위치를 조정함으로써 얻는다.
Faster R-CNN
- Fast R-CNN에서 bounding box를 뽑는 것도 network로 학습하자는 아이디어(Region Propsal Network)가 추가되었다.
- Selective search 알고리즘 대신 regional proposal까지 학습하여 찾는 Region Proposal Network(RPN)에 Fast R-CNN을 결합한 형태이다.
- RPN
- RPN으로 분류는 하지 않고, 후보들만 찾아낸다(물체의 유무 판단)
- Anchor box(미리 정해놓은 bounding box의 크기)를 활용하는데, 후보에는 총 9개의 region size가 있으며, 각 region 후보 박스마다 4개의 bounding box regression parameter(w, h, x, y)가 있고, 해당 박스가 정말 쓸모 있는지를 판단하는 box classifier가 2개 있어 RPN에서는 총 9(4+2) = 5개의 채널이 필요하다.
YOLO
- YOLO는 현재 v5까지 나왔으며, v1에 대해 먼저 알아보자.
- RPN, CNN 등의 과정 없이 이미지를 한번 찍고 바로 여러 bounding box 예측 및 각 클래스에 대한 확률을 구해낸다.
- 따라서 매우 빠른 속도에 정확도도 높은 성능을 보여준다.
- 먼저 주어진 이미지를 일정 크기의 grid로 나누는데, 찾고 싶은 물체의 중앙이 grid cell에 있으면 그 grid cell의 응답을 통해 bounding과 예측을 동시에 진행한다.
- 각 grid cell은 B개의 bounding box를 예측한다.
- 각 바운딩 박스는 box refinement(x, y, w, h)와 confidence(정말 물체가 있는가?)를 예측한다.
- 또한 각 grid cell은 C개의 클래스에 대한 확률 값을 예측한다.
- 결론적으로, 한 이미지에 대하여 S x S x (B x 5 + C) 크기의 tensor를 가진다(S x S는 그리드의 개수)
'딥러닝 > Vision' 카테고리의 다른 글
| Semantic Segmentation (0) | 2022.03.30 |
|---|---|
| Mask R-CNN (0) | 2022.03.30 |
| CNN with pytorch (0) | 2022.02.12 |
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.07.25 |
| Mobile Net (0) | 2021.03.24 |