
Reranker, Query Expansion, Hybrid Search는 정말 필요한가?
이전 글까지 해서 Chunking → Embedding이라는 RAG 검색 파이프라인의 핵심 요소들을 하나씩 살펴봤다.
원래는 이다음으로 “검색 결과를 기반으로 실제 답변을 생성했을 때 품질이 얼마나 달라지는지”까지 테스트해보려 했는데
솔직히 말하면, "굳이 답변생성 비교까지 해야 의미가 있을까?"라는 생각이 들었다.
이미 검색 단계에서 성능 차이가 명확히 갈리고,
답변 생성은 결국 LLM 성능 + 프롬프트 영향이 너무 커서 검색 전략 자체의 비교가 흐려질 가능성이 컸다.
그래서 이번 글에서는 RAG의 검색 품질을 마지막으로 끌어올리는 단계에 집중하고 이번 시리즈를 마무리하려고한다.
- Reranking
- Query Transfer (HyDE, Multi-Query)
- Hybrid Search
과연 이 기법들이 실제로 성능을 올려주는지, 그리고 어디까지가 과한 설계인지를 정리해 보자.
Reranking 테스트 결과
Embedding 기반 검색으로 “후보 문서”를 모았다면,
Reranker는 그 후보들을 질문과 문서 쌍 단위로 다시 비교해 순서를 재정렬하는 단계다.
이번 테스트에서는 다음과 같은 Reranker들을 비교했다.
| 모델 |
Mean Reciprocal Rank (MRR) |
Mean Precision@K | reranking 방식 | 비고 |
|---|---|---|---|---|
| Baseline | 0.763 | 0.292 | - | - |
| qwen3_reranking | 0.7117 | 0.280 | LLM-based | 오픈소스 |
| Dongjin-kr / ko-reranker | 0.8100 | 0.296 | Cross Encoder | 오픈소스 |
| dragonkue/bge-reranker-v2-m3-ko | 0.8017 | 0.288 | Cross Encoder | 오픈소스 |
| Gemini Reranking API | 0.8367 | 0.292 | Cross Encoder | 유로 API |
세부 분석
- Cross Encoder 기반 Reranker가 압도적으로 강함
- LLM-based reranking(Qwen)은 생각보다 성능이 안 좋다.
- Gemini Reranking API가 MRR 기준 1위
- “가장 관련 있는 문서가 1번으로 오는가?”라는 질문에는 가장 정확했다.
- 다만 Precision@K는 ko-reranker가 근소하게 1위
- 비용 문제로 유료 API를 쓰기 어렵다면 충분히 현실적인 대안이다.
👉 결론적으로 Reranking은 ‘무조건’ 넣을 가치가 있다.
Embedding 모델 간 성능 차이보다, Reranker 유무의 차이가 더 크다고 느껴질 정도다.
부록: Qwen3-Reranker는 어떻게 점수를 매길까?
앞서 살펴본 Reranker들(Gemini, BGE, ko-reranker)은 모두
전형적인 *Cross Encoder 방식이다.
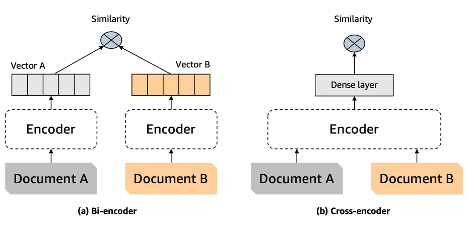
*Cross Encoder : Query + document를 함께 넣고 "얼마나 관련 있는가"를 하나의 유사도로 바로 출력하는 방식이다.
그런데 Qwen3-Reranker-0.6B는 구조가 조금 다르다.
Qwen3-Reranker는 query와 document를 직접 점수화하지 않는다.
대신, 다음과 같은 형태의 판정 문제(Judgement task)로 변환한다.
Instruct: 주어진 검색 쿼리에 대해 관련 있는 문서를 찾아라
Query: {질문}
Document: {문서}
이 문서가 질문에 부합하는가? (yes / no)그리고 모델에게 정말로 yes 또는 no만 생성하도록 강제한다.
점수가 계산되는 방법은 다음과 같다.
- 모델은 마지막 토큰에서
"yes"가 나올 확률"no"가 나올 확률
이 두 가지만을 비교한다.
yes토큰이 생성될 확률을
→ 해당(query, document)쌍의 관련도 점수로 사용한다.
즉,
✔️ yes가 나올 확률이 높다
→ “이 문서는 질문에 답이 될 가능성이 높다”
→ ranking에서 위로 올라간다
이 방식의 장단점
장점
- “이 문서가 답이 되는가?”라는 질문에 매우 직관적인 판단
- instruction-aware 구조라서 질문 의도 반영이 잘 됨
- 검색 품질이 나쁜 문서를 강하게 걸러내는 경향
단점
- 추론 비용이 상대적으로 큼
- 일반적인 reranker보다 속도 / 효율이 떨어짐
- 이번 실험에서도 보였듯,
- 전통적인 Cross Encoder 대비 성능이 안정적이지는 않음
그래서 왜 성능이 상대적으로 낮았을까?
이번 실험 결과를 다시 보면
Qwen3-Reranker는“완전히 맞냐 / 아니냐”에는 강하지만 미묘한 문서 간 우열을 가리는 데는 약한 편이다.
반면, Gemini / ko-reranker 같은 Cross Encoder는 relevance를 연속적인 스코어로 다루기 때문에 MRR, Precision@K 같은 랭킹 지표에서 더 유리했다.
Query Transfer (Query Expansion)
다음은 검색 범위를 넓히기 위한 쿼리 확장 기법들이다.
[1] HyDE (Hypothetical Document Embeddings)
HyDE는 질문에 대해 “그럴듯한 가짜 답변”을 먼저 생성한 뒤, 그 답변을 임베딩해서 검색하는 방식이다.
이번 테스트에서 가짜 답변을 생성하는데 사용한 프롬프트는 다음과 같다.
다음 질문에 대한 간단한 답변을 3문장 이내로 작성해주세요.
답변은 구체적이고 정보가 풍부해야 하며, 실제 문서에서 찾을 수 있는 형태로 작성해주세요.
질문: {question}
답변:*모든 생성은 gemini-2.5-flash-lite 모델을 사용했다.
| 방식 | MRR | Precision@K |
|---|---|---|
| Baseline | 0.763 | 0.292 |
| HyDE | 0.7567 | 0.292 |
👉 Baseline 대비 성능이 소폭 하락했다. 이것만으로도 쓸 이유는 없고, 사실 그게 아니더라도, '그럴듯한 가짜 답변'을 생성하는 게 시간이 좀 걸리기 때문에 실시간 서비스에서는 해당 기술을 쓰기는 거의 불가능에 가깝다
[2] Multi-Query Retrieval
Multi-Query는 하나의 질문을 여러 검색 쿼리로 확장하는 방식이다.
사용한 프롬프트는 다음과 같다.
다음 질문에 대해 {num_queries}개의 서로 다른 검색용 쿼리를 생성해주세요.
각 쿼리는 원본 질문의 다양한 측면이나 관련 정보를 찾기 위한 것이어야 합니다.
각 쿼리는 한 줄로 작성하고, 번호를 붙여주세요.
원본 질문: {question}
검색용 쿼리:- 원본 쿼리 + LLM 생성 쿼리 3개
- 각 쿼리를 임베딩 → Semantic Search 수행
- 총 15개 후보 문서 확보 (중복 가능)
- 이후 Gemini Reranking API로 재정렬
| 방식 | MRR | Precision@K |
|---|---|---|
| baseline | 0.762 | 0.292 |
| Multi-Query | 0.8240 | 0.276 |
중요한 해석 포인트
겉으로 보면 성능이 좋아 보이지만, 사실 첫 번째로 테스트한 Reranking 성능 표를 보면
Multi-Query + Reranking 조합보다, 그냥 단일 쿼리로 Top 10 검색 → Reranking → Top 5 추출
이 방식이 MRR / Precision 모두 더 안정적인 것을 알 수 있다.
즉,
- 쿼리를 늘리면 노이즈도 같이 늘어난다
- Reranker가 아무리 강해도, 후보 풀이 지나치게 커지면 손해이다.
Hybrid Search (Semantic + BM25)
마지막은 Hybrid Search다.
| 방식 | MRR | Precision@K |
|---|---|---|
| baseline | 0.762 | 0.292 |
| Semantic + BM25 | 0.7017 | 0.260 |
솔직히 말하면 점수가 너무 낮게 측정되었다.
기대했던 “시맨틱 + 키워드 보완 효과”가 거의 보이지 않았다.
구현 상의 문제인지, 가중치 설정 문제인지, 데이터셋 특성 때문인지는 아직 명확하지 않다.
이 부분은 내가 뭘 잘못한 건지 더 파봐야 할 영역이라, 이번 시리즈에서는 보류로 남겨두겠다.
최종 결론: 지금 시점에서의 추천 조합
이번 시리즈 전체 실험을 종합해서, 지금 당장 실무에서 쓰기 좋은 RAG 검색 조합은 다음 조합이다.
✅ 내가 추천하는 구성
- Embedding
Qwen3-Embedding-0.6B
- Chunking
- Page 기반, 문서 구조를 고려한 chunking
- Reranking
- 가능하면 Gemini Reranking API
- 유료 API가 부담된다면 →
Dongjin-kr/ko-reranker
❌ 굳이 안 써도 될 것 같은 것들
- Query Expansion (HyDE, Multi-Query)
- 관리 복잡도 대비 성능 이득이 크지 않음
- Hybrid Search
- 아직은 신뢰할 수 있는 결과가 아님 (추후 재검증 필요)
마무리하며
RAG를 하다 보면 어느 순간 이런 생각이 든다.
“이걸 더 복잡하게 만드는 게 정말 의미가 있을까?”
이번 실험을 통해 느낀 건,
Embedding + Reranking까지만 제대로 해도, 이미 검색 품질은 실무에서 충분히 쓸 수준까지 올라온다는 점이다.
이 글이 “RAG 파이프라인을 어디까지 설계해야 할지 고민하는 사람”에게 불필요한 복잡도를 줄이는 기준점이 되었으면 한다.
아마 이 글로, 이 시리즈는 마무리가 될 것 같은데, 2026년에 다시 이어서 작성할지도 모르겠다.
Reference
- https://arxiv.org/pdf/2312.10997
- https://huggingface.co/Qwen/Qwen3-Reranker-0.6B
- https://docs.cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/retrieval-and-ranking?hl=ko
- https://huggingface.co/dragonkue/bge-reranker-v2-m3-ko
- https://huggingface.co/Dongjin-kr/ko-reranker
- https://aws.amazon.com/ko/blogs/tech/korean-reranker-rag/
'AI' 카테고리의 다른 글
| Anthropic: Demystifying evals for AI agents (1) | 2026.01.16 |
|---|---|
| [RAG] #3 - Embedding (0) | 2025.12.28 |
| RAG #2 - Chunking (0) | 2025.12.28 |
| RAG #1 (0) | 2025.12.28 |
| Google file search (0) | 2025.11.18 |