본 글은 데이콘에서 주관한 도배 하자 질의응답 처리 대회 참여 후기이다.
팀원 1명을 포함해 2명이서 대회에 참가했고, 대회 시작은 1월부터였지만, 제대로 참여한 건 3월 쯔음부터 시작한 거 같다.

대회 개요
해당 대회는 한솔데코에서 주최한 대회로, NLP(자연어 처리) 기반의 QA (질문-응답) 시스템을 통해 도배하자와 관련된 깊이 있는 질의응답 처리 능력을 갖춘 AI 모델 개발을 목표로 하고 있다. 아래 사이트에서 활용하는 LLM을 개발하고자 하는 것 같았다.
Chat UI Screen
마감재 하자 (벽지, 마루, 타일, 시트지!!) 관련해서 뭐든지 물어보세요!
sosohajalab.pages.dev
데이터
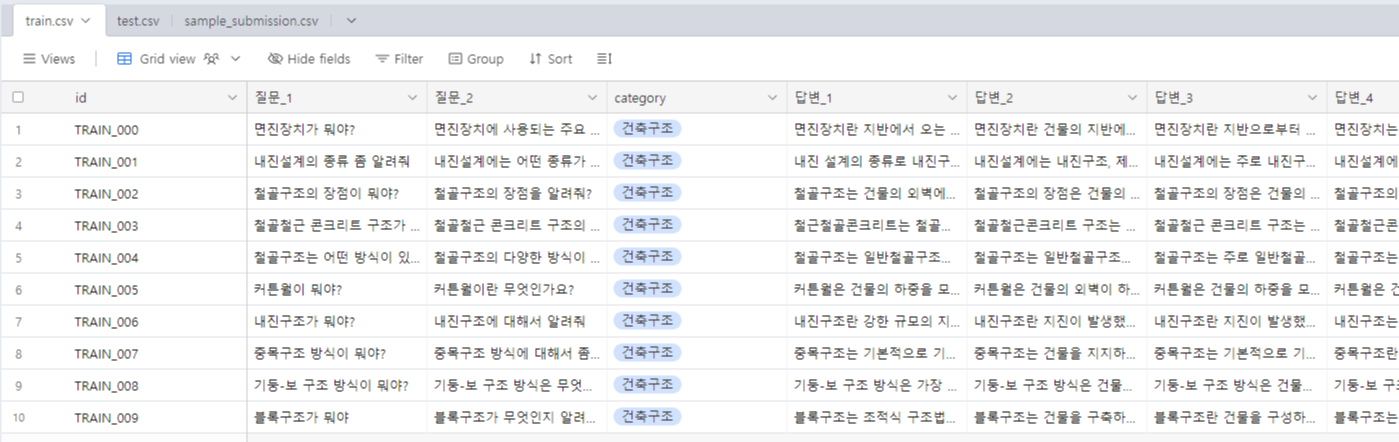
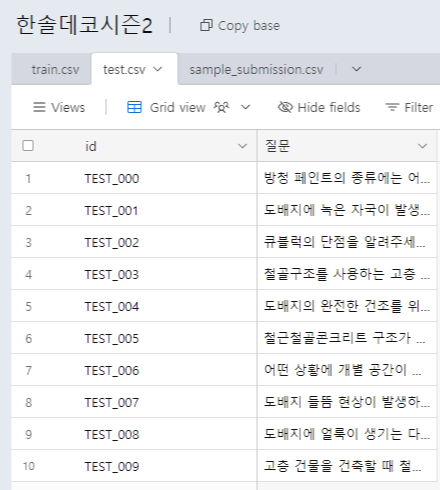
train데이터와 test 데이터를 살펴보면 train 데이터는 데이터 1개에 질문 2개와 답변 5가지가 주어진다. 그러나 test 데이터는 데이터 1개에 질문 1개가 주어지고 해당 질문에 대한 답변을 생성하는 모델을 개발하면 된다.
한 가지 특이한 점은 답변을 생성한 다음 sentence-transformer 계열 모델을 이용해 답변을 임베딩하고 해당 결과를 제출해야 하는 것이었다. 그래서 점수를 계산할 때, 임베딩 벡터의 코사인 유사도를 바탕으로 점수를 계산한다고 명시되어 있었다. 자세한 내용은 규칙을 참고하면 좋을 거 같다.
대회 접근 방식
우리 팀은 최적화된 모델을 개발하기 위해 총 3가지의 큰 틀로 프로세스를 나눠서 진행했다.
1. 데이터 전처리
데이터 전처리를 진행한 이유는 제공된 데이터의 검수가 완전하지 않았었고, 해당 부분이 모델에 안 좋은 영향을 줄 것이라 판단해서 전체 제공 데이터에 대한 검수를 자체적으로 진행했다. 검수 후 수정된 내용은 크게 3가지가 있었다.
(1) train데이터에서 1개 데이터에서 제공되는 질문이 서로 다른 질문인 경우

(2) 텍스트의 문법, 맞춤법 오류

(3) 질문에 대한 답변이 옳지 않았던 경우

2. 데이터 증강
데이터 증강을 적용한 이유는 첫 번째로 모델을 다양한 유형의 데이터로 학습하고 싶었기 때문이다. 예를 들면 공모전에서 제공된 train 데이터는 한 번에 2가지 내용에 대한 질문이 없었다. 그러나 test 데이터에는 한 번에 2개의 질문을 하는 경우가 꽤 있었고, 그런 경우에도 답변을 잘하는 모델을 개발하기 위해 데이터 증강을 적용했다.
두 번째 이유는 모델 학습 시 DPO기법을 적용하고자 했는데, 해당 기법을 적용하기 위해서는 질문에 대한 답변 내용뿐만 아니라 사용자가 선호할 만한 답변에 대한 labeling 된 데이터가 필요했기 때문에 데이터 증강이 필수적으로 필요하였다.
요약하면 모델을 최적화하기 위해 더 다양한 데이터를 확보하고자 하였고, 제공된 데이터를 바탕으로 데이터를 생성하거나 결합하여 데이터를 증강했다.
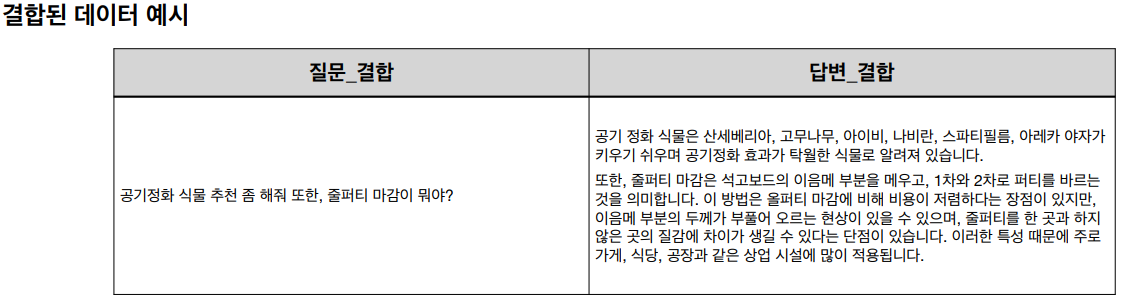
2-1 두 가지 질문 결합
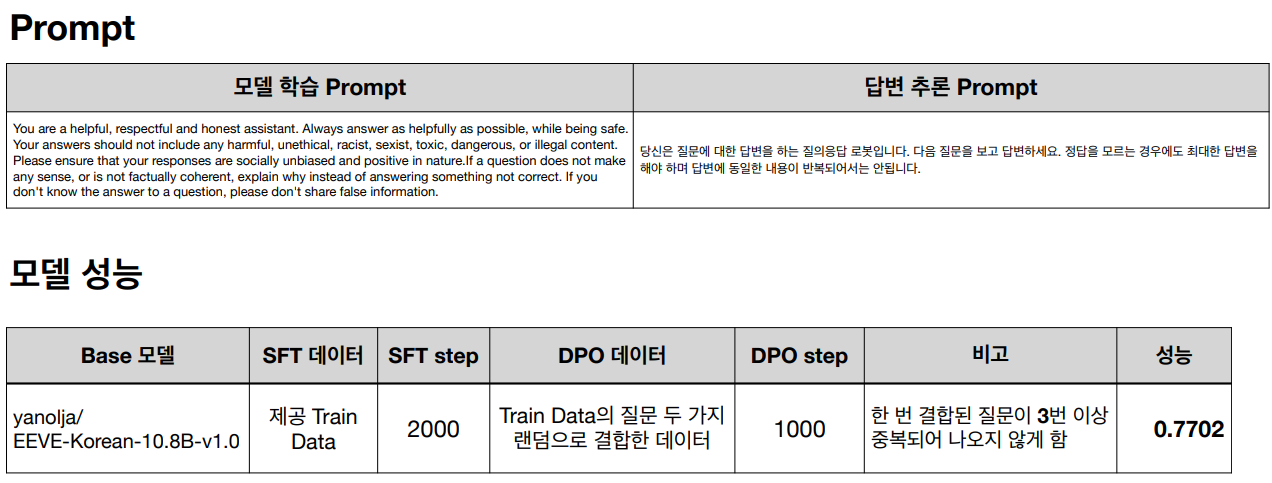
질문 결합을 위해서 train data의 질문 두 가지를 랜덤으로 결합하였다. 또한 동일한 질문이 반복되어 결합되는 것을 방지하기 위해 데이터 결합 시 한번 결합된 내용이 3번 이상 나오는 것을 방지하였다.
2-2 DPO용 데이터 생성
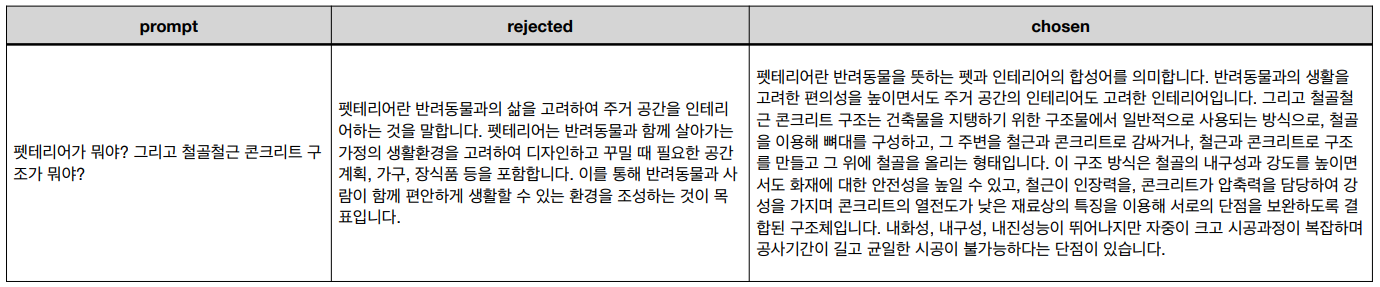
DPO 학습을 위한 데이터셋을 만들기 위해 아래와 같은 기준으로 DPO 데이터셋을 구축하였다.
- prompt : 두 가지 질문
- Human chosen : 두 가지 질문에 대한 두 가지 답변이 잘 이루어짐
- Human rejected : 두 가지 질문에 대해 한 가지 답변만 이뤄짐.
또한 위에서 구축한 DPO 데이터셋을 다양화하기 위해 RAG(Retrieval Augmented Generation) 기술을 적용하여 추가 데이터를 생성하였다. LangChain 및 Faiss 라이브러리를 이용해 질문(prompt)에 대한 관련 답변의 결과를 받아와 해당 결과를 이용해 GPT4로 답변을 생성하였다.
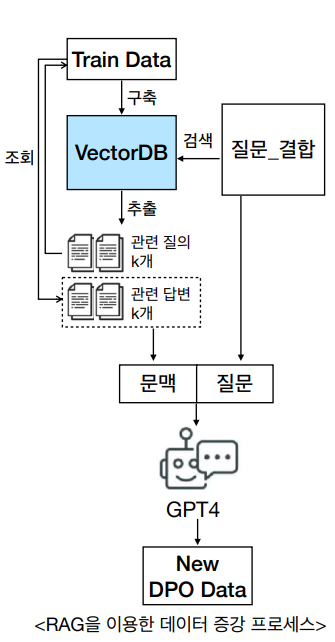
왼쪽 프로세스를 간략히 설명하면 아래와 같다.
1. train 데이터의 질문과 답변을 임베딩 모델을 이용해 임베딩하고, 해당 결과를 Vercor DB로 저장.
2. GPT4에 답변 생성을 요청하기 위해 질문과 관련된 내용을 vector db에서 조회해서 가져와 Context로 활용.
3. 2번에서 가져온 내용을 GPT4가 참고해서 답변을 생성할 수 있게 질문과 해당 내용(Context)을 함께 GPT4에 전달해 답변 생성
위 결과를 통해 생성한 답변을 DPO 데이터 셋에서 Human chosen 칼럼으로 활용하였다.

3. 모델 학습
모델 학습은 크게 3가지를 적용했다. SFT, DPO 그리고 prompt tuning이다. prompt tuning을 모델 학습에 넣는 게 맞을지 잘 모르겠는데, 어쨌든 모델에 직접적인 영향을 주기 때문에 같은 카테고리로 넣었다.
SFT
SFT란 LLM (Large Language Model) 모델을 학습하는 방법 중 하나로 Labeling 된 데이터를 바탕으로 모델을 미세조정하는 방법이다. 그래서 일반적으로 LLM을 학습하기 위해 SFT를 적용한다.
다만 현재 공개되어 있는 모델 대부분은 특정 도메인에 활용하기 위함이 아닌 다양한 task에서 범용적으로 활용하기 위한 모델이다. 대회 목적에 맞는 모델을 개발하기 위해, 제공된 train 데이터셋을 이용해 SFT를 적용하였고, 그 결과 도배하자 질의응답 전용 LLM을 개발할 수 있었다.

DPO
모델 학습을 위해 DPO까지 진행한 이유는 다음과 같다.
- 단순 Supervised Fine-tuning으로 학습한 모델의 예측 답을 살펴본 결과, 답변 자체가 자연스럽지 못한 경우가 존재했다.
- DPO를 통해 학습 시 사용자가 더 선호할만한 답변을 생성하도록 학습할 수 있다는 장점이 있다.
아래 예시는 SFT를 적용한 모델의 답변 예시인데, 2가지 질문 중 첫 번째 질문에만 길게 답하고 두 번째 질문에는 짧게 답해 사용자가 원하는 결과물이 아니라는 생각이 들었다.

Prompt engineering
Prompt engineering이란 새로운 Task 해결을 위해 LLM의 답변을 통제하는 방법 중 하나이다. 가장 큰 특징은 가중치 업데이트 없이 모델의 답변 생성 성능을 향상할 수 있다는 것이다.
LLM으로 답변을 생성할 때, 아래 예시처럼 질문 답변 외에 텍스트(prompt)가 입력되는데, 해당 텍스트를 바꿔가며 모델이 생성하는 결과를 조정하는 것을 Prompt engineering이라고 한다.

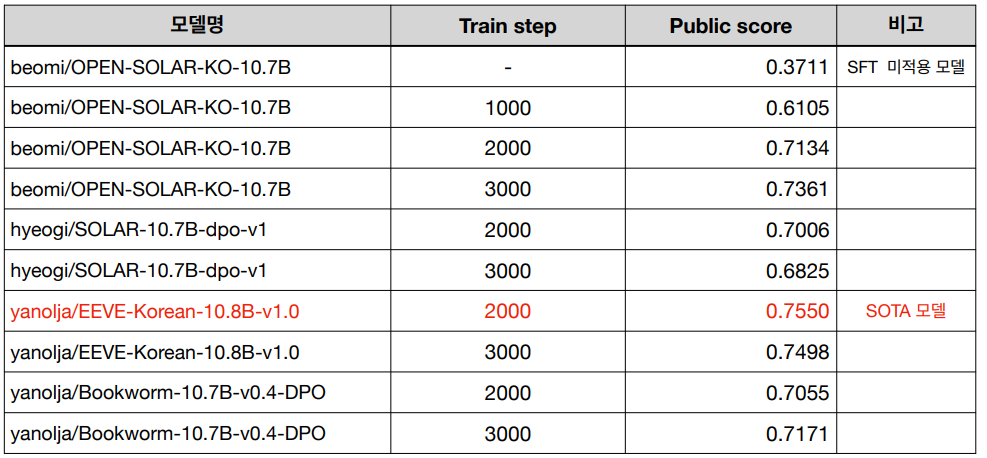
학습 실험 결과
아래 결과는 각 학습 기법에 대한 모델 성능 결과이다.
SFT
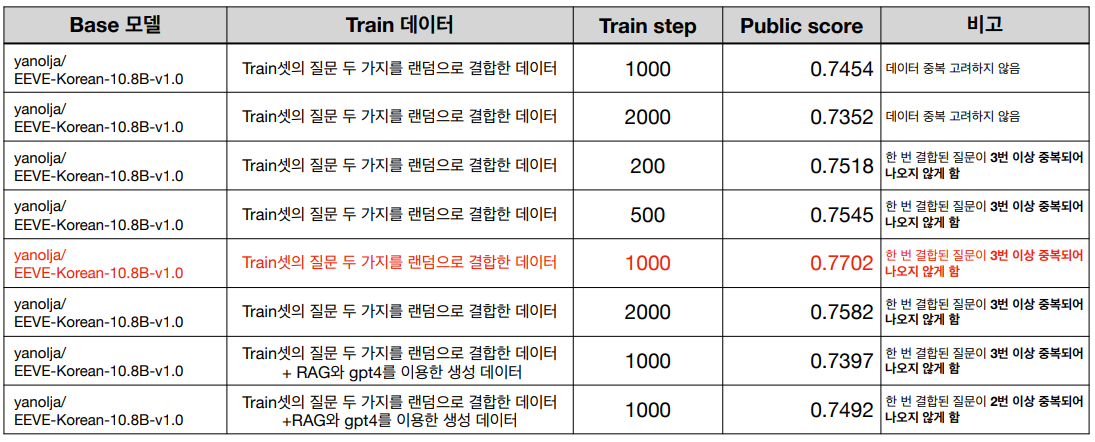
DPO
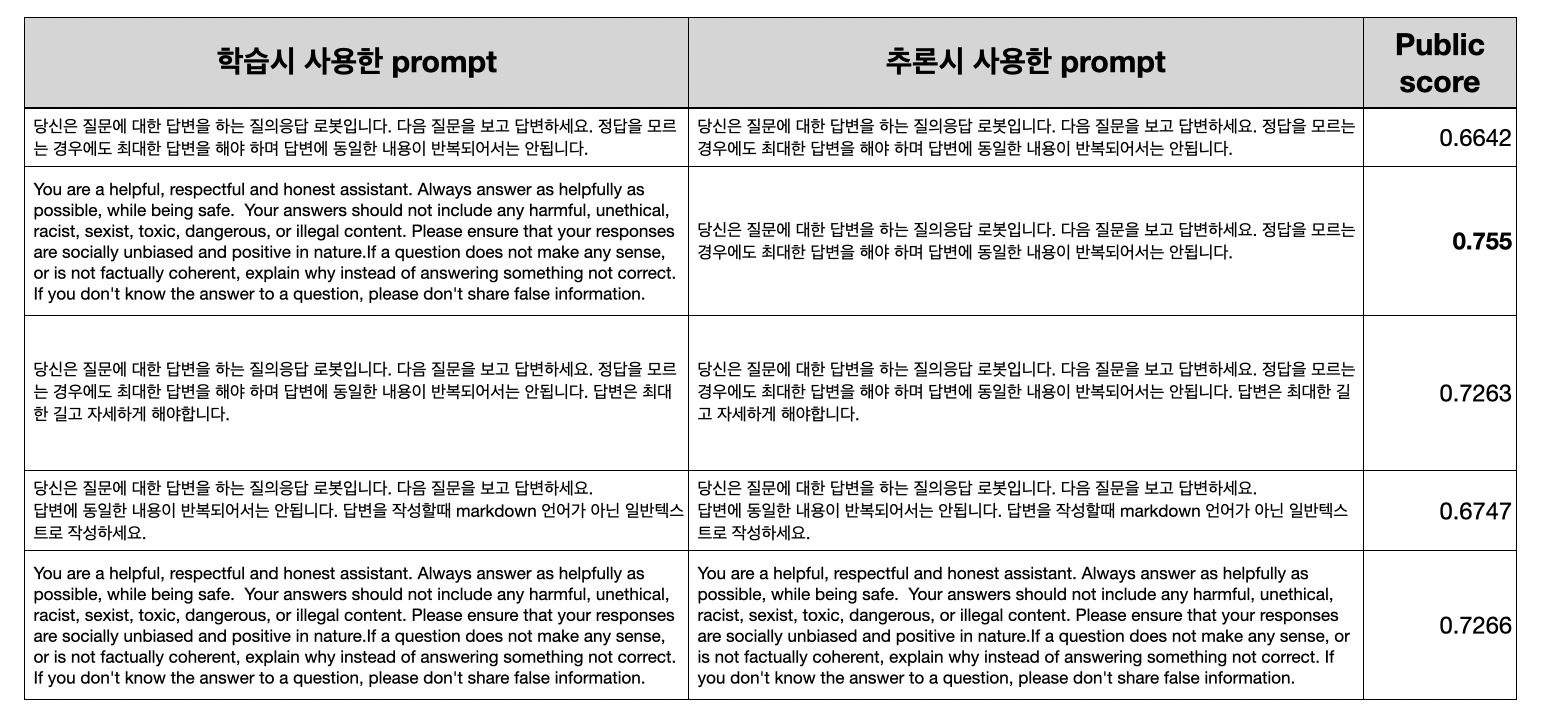
Prompt engineering
각각의 과정을 통해 해당 대회에 맞는 최적의 모델을 선정하고자 했으며, 우리팀이 최종적으로 선정한 모델은 다음과 같다.
회고
배운 점
1. 특정 Domain에 특화된 LLM을 개발하기 위해서는 SFT가 필수적이고 가장 빠르게 결과물을 얻어 낼 수 있다.
2. DPO나 Prompt tuning 기법등을 통해 조금 더 세밀하게 모델을 조정하여 원하는 형태와 형식의 답변을 도출해 낼 수 있다.
3. 해당 대회를 참가하기 전에도 SFT나 DPO 같은 기술들은 적용해 본 적이 있지만 RAG기술을 처음 접해보았다. Vector DB를 만들고 Retrieval 해서 Context로 활용하고 이런 것들이 실제 적용해 보기 전까지는 어렵게 느껴졌었는데, 구현해서 활용해 보니 생각보다 쉽고 직관적으로 이해할 수 있었다.
4. 혼자서 대회에 참가했으면 사실 이렇게 많은 시도를 해볼 수 없었을꺼 같다. 끝까지 함께 할 수 있는 팀원의 중요성을 느꼈고, 감사하다.
아쉬운 점
1. 대회가 종료되고 상위권 참가자들이 코드를 공개해서 몇 개 살펴보았는데, DPO를 적용하지 않고도 좋은 결과를 얻은 참가자들이 꽤 있었다. 대회 참가를 약 3주 정도밖에 하지 않아서, SFT 학습 시 다양한 파라미터를 고려하지 않았는데 해당 과정에서 더 많은 실험을 할 수 있었다면, 어쩌면 수상도 할 수 있지 않았을까? 하는 아쉬움이 남는다.
2. RAG를 통한 데이터 증강이 크게 효과가 없었다. 증강된 데이터 자체는 꽤 괜찮다고 판단했었는데 어떤 부분이 문제여서 효과가 없었는지 제대로 분석해내지 못했다.
Reference
'딥러닝 > LLM' 카테고리의 다른 글
| Supervised Fine-tuning: customizing LLMs (0) | 2024.08.06 |
|---|---|
| Gemma 2 (9B & 27B) Evaluation vs. Open/Closed-Source LLMs (0) | 2024.08.01 |
| Pretraining LLMs (0) | 2024.07.31 |
| Kaggle - LLM Science Exam 후기 (1) | 2023.10.23 |
| LLM과 LangChain (0) | 2023.05.23 |
본 글은 데이콘에서 주관한 도배 하자 질의응답 처리 대회 참여 후기이다.
팀원 1명을 포함해 2명이서 대회에 참가했고, 대회 시작은 1월부터였지만, 제대로 참여한 건 3월 쯔음부터 시작한 거 같다.
대회 개요
해당 대회는 한솔데코에서 주최한 대회로, NLP(자연어 처리) 기반의 QA (질문-응답) 시스템을 통해 도배하자와 관련된 깊이 있는 질의응답 처리 능력을 갖춘 AI 모델 개발을 목표로 하고 있다. 아래 사이트에서 활용하는 LLM을 개발하고자 하는 것 같았다.
Chat UI Screen
마감재 하자 (벽지, 마루, 타일, 시트지!!) 관련해서 뭐든지 물어보세요!
sosohajalab.pages.dev
데이터
train데이터와 test 데이터를 살펴보면 train 데이터는 데이터 1개에 질문 2개와 답변 5가지가 주어진다. 그러나 test 데이터는 데이터 1개에 질문 1개가 주어지고 해당 질문에 대한 답변을 생성하는 모델을 개발하면 된다.
한 가지 특이한 점은 답변을 생성한 다음 sentence-transformer 계열 모델을 이용해 답변을 임베딩하고 해당 결과를 제출해야 하는 것이었다. 그래서 점수를 계산할 때, 임베딩 벡터의 코사인 유사도를 바탕으로 점수를 계산한다고 명시되어 있었다. 자세한 내용은 규칙을 참고하면 좋을 거 같다.
대회 접근 방식
우리 팀은 최적화된 모델을 개발하기 위해 총 3가지의 큰 틀로 프로세스를 나눠서 진행했다.
1. 데이터 전처리
데이터 전처리를 진행한 이유는 제공된 데이터의 검수가 완전하지 않았었고, 해당 부분이 모델에 안 좋은 영향을 줄 것이라 판단해서 전체 제공 데이터에 대한 검수를 자체적으로 진행했다. 검수 후 수정된 내용은 크게 3가지가 있었다.
(1) train데이터에서 1개 데이터에서 제공되는 질문이 서로 다른 질문인 경우
(2) 텍스트의 문법, 맞춤법 오류
(3) 질문에 대한 답변이 옳지 않았던 경우
2. 데이터 증강
데이터 증강을 적용한 이유는 첫 번째로 모델을 다양한 유형의 데이터로 학습하고 싶었기 때문이다. 예를 들면 공모전에서 제공된 train 데이터는 한 번에 2가지 내용에 대한 질문이 없었다. 그러나 test 데이터에는 한 번에 2개의 질문을 하는 경우가 꽤 있었고, 그런 경우에도 답변을 잘하는 모델을 개발하기 위해 데이터 증강을 적용했다.
두 번째 이유는 모델 학습 시 DPO기법을 적용하고자 했는데, 해당 기법을 적용하기 위해서는 질문에 대한 답변 내용뿐만 아니라 사용자가 선호할 만한 답변에 대한 labeling 된 데이터가 필요했기 때문에 데이터 증강이 필수적으로 필요하였다.
요약하면 모델을 최적화하기 위해 더 다양한 데이터를 확보하고자 하였고, 제공된 데이터를 바탕으로 데이터를 생성하거나 결합하여 데이터를 증강했다.
2-1 두 가지 질문 결합
질문 결합을 위해서 train data의 질문 두 가지를 랜덤으로 결합하였다. 또한 동일한 질문이 반복되어 결합되는 것을 방지하기 위해 데이터 결합 시 한번 결합된 내용이 3번 이상 나오는 것을 방지하였다.
2-2 DPO용 데이터 생성
DPO 학습을 위한 데이터셋을 만들기 위해 아래와 같은 기준으로 DPO 데이터셋을 구축하였다.
- prompt : 두 가지 질문
- Human chosen : 두 가지 질문에 대한 두 가지 답변이 잘 이루어짐
- Human rejected : 두 가지 질문에 대해 한 가지 답변만 이뤄짐.
또한 위에서 구축한 DPO 데이터셋을 다양화하기 위해 RAG(Retrieval Augmented Generation) 기술을 적용하여 추가 데이터를 생성하였다. LangChain 및 Faiss 라이브러리를 이용해 질문(prompt)에 대한 관련 답변의 결과를 받아와 해당 결과를 이용해 GPT4로 답변을 생성하였다.
왼쪽 프로세스를 간략히 설명하면 아래와 같다.
1. train 데이터의 질문과 답변을 임베딩 모델을 이용해 임베딩하고, 해당 결과를 Vercor DB로 저장.
2. GPT4에 답변 생성을 요청하기 위해 질문과 관련된 내용을 vector db에서 조회해서 가져와 Context로 활용.
3. 2번에서 가져온 내용을 GPT4가 참고해서 답변을 생성할 수 있게 질문과 해당 내용(Context)을 함께 GPT4에 전달해 답변 생성
위 결과를 통해 생성한 답변을 DPO 데이터 셋에서 Human chosen 칼럼으로 활용하였다.
3. 모델 학습
모델 학습은 크게 3가지를 적용했다. SFT, DPO 그리고 prompt tuning이다. prompt tuning을 모델 학습에 넣는 게 맞을지 잘 모르겠는데, 어쨌든 모델에 직접적인 영향을 주기 때문에 같은 카테고리로 넣었다.
SFT
SFT란 LLM (Large Language Model) 모델을 학습하는 방법 중 하나로 Labeling 된 데이터를 바탕으로 모델을 미세조정하는 방법이다. 그래서 일반적으로 LLM을 학습하기 위해 SFT를 적용한다.
다만 현재 공개되어 있는 모델 대부분은 특정 도메인에 활용하기 위함이 아닌 다양한 task에서 범용적으로 활용하기 위한 모델이다. 대회 목적에 맞는 모델을 개발하기 위해, 제공된 train 데이터셋을 이용해 SFT를 적용하였고, 그 결과 도배하자 질의응답 전용 LLM을 개발할 수 있었다.
DPO
모델 학습을 위해 DPO까지 진행한 이유는 다음과 같다.
- 단순 Supervised Fine-tuning으로 학습한 모델의 예측 답을 살펴본 결과, 답변 자체가 자연스럽지 못한 경우가 존재했다.
- DPO를 통해 학습 시 사용자가 더 선호할만한 답변을 생성하도록 학습할 수 있다는 장점이 있다.
아래 예시는 SFT를 적용한 모델의 답변 예시인데, 2가지 질문 중 첫 번째 질문에만 길게 답하고 두 번째 질문에는 짧게 답해 사용자가 원하는 결과물이 아니라는 생각이 들었다.
Prompt engineering
Prompt engineering이란 새로운 Task 해결을 위해 LLM의 답변을 통제하는 방법 중 하나이다. 가장 큰 특징은 가중치 업데이트 없이 모델의 답변 생성 성능을 향상할 수 있다는 것이다.
LLM으로 답변을 생성할 때, 아래 예시처럼 질문 답변 외에 텍스트(prompt)가 입력되는데, 해당 텍스트를 바꿔가며 모델이 생성하는 결과를 조정하는 것을 Prompt engineering이라고 한다.
학습 실험 결과
아래 결과는 각 학습 기법에 대한 모델 성능 결과이다.
SFT
DPO
Prompt engineering
각각의 과정을 통해 해당 대회에 맞는 최적의 모델을 선정하고자 했으며, 우리팀이 최종적으로 선정한 모델은 다음과 같다.
회고
배운 점
1. 특정 Domain에 특화된 LLM을 개발하기 위해서는 SFT가 필수적이고 가장 빠르게 결과물을 얻어 낼 수 있다.
2. DPO나 Prompt tuning 기법등을 통해 조금 더 세밀하게 모델을 조정하여 원하는 형태와 형식의 답변을 도출해 낼 수 있다.
3. 해당 대회를 참가하기 전에도 SFT나 DPO 같은 기술들은 적용해 본 적이 있지만 RAG기술을 처음 접해보았다. Vector DB를 만들고 Retrieval 해서 Context로 활용하고 이런 것들이 실제 적용해 보기 전까지는 어렵게 느껴졌었는데, 구현해서 활용해 보니 생각보다 쉽고 직관적으로 이해할 수 있었다.
4. 혼자서 대회에 참가했으면 사실 이렇게 많은 시도를 해볼 수 없었을꺼 같다. 끝까지 함께 할 수 있는 팀원의 중요성을 느꼈고, 감사하다.
아쉬운 점
1. 대회가 종료되고 상위권 참가자들이 코드를 공개해서 몇 개 살펴보았는데, DPO를 적용하지 않고도 좋은 결과를 얻은 참가자들이 꽤 있었다. 대회 참가를 약 3주 정도밖에 하지 않아서, SFT 학습 시 다양한 파라미터를 고려하지 않았는데 해당 과정에서 더 많은 실험을 할 수 있었다면, 어쩌면 수상도 할 수 있지 않았을까? 하는 아쉬움이 남는다.
2. RAG를 통한 데이터 증강이 크게 효과가 없었다. 증강된 데이터 자체는 꽤 괜찮다고 판단했었는데 어떤 부분이 문제여서 효과가 없었는지 제대로 분석해내지 못했다.
Reference
'딥러닝 > LLM' 카테고리의 다른 글
| Supervised Fine-tuning: customizing LLMs (0) | 2024.08.06 |
|---|---|
| Gemma 2 (9B & 27B) Evaluation vs. Open/Closed-Source LLMs (0) | 2024.08.01 |
| Pretraining LLMs (0) | 2024.07.31 |
| Kaggle - LLM Science Exam 후기 (1) | 2023.10.23 |
| LLM과 LangChain (0) | 2023.05.23 |