해당 글은 링크의 내용을 바탕으로 작성된 글입니다.
다소 번역이 부드럽지 못한 부분이 있을 수 있습니다.

2024년 6월 27일, 구글 딥마인드는 90억 개(9B) 및 270억 개(27B) 파라미터 크기로 제공되는 Gemma 2의 공식 출시를 발표했습니다.
이 모델은 chat-gpt 같은 Closed-source LLM을 사용해야만 달성할 수 있었던 높은 성능과 효율성을 제공하며, 이는 AI 기술의 비약적인 발전을 의미합니다.
이 글은 최신 open source 및 closed-source LLM과 비교하여 Gemma 2(9B)와 Gemma 2(27B)의 다국어 이해도를 비교 분석 한 글입니다.
Official Statements from Google
구글 딥마인드 연구원들은 공식 블로그를 통해 Gemma 2의 학습 과정, 평가 지표 및 기술 보고서를 설명했습니다. 블로그에서 언급했듯이 Gemma 2 모델은 크기 대비 동급 최고의 성능을 제공합니다.
27B 모델은 크기가 두 배 이상 큰 모델과 경쟁하며, 9B 모델은 Llama 3 8B를 비롯한 동급의 다른 모델보다 성능이 뛰어나다고 명시되어 있습니다.
Gemma 2의 두드러진 특징 중 하나는 효율성입니다. 27B 모델은 단일 Google Cloud TPU 호스트 또는 NVIDIA A100 80GB Tensor 코어 GPU에서 full precision inference에 최적화되어 있습니다. 이는 분산 컴퓨팅 인프라가 필요하지 않은 단순성으로 인해 배포 비용이 크게 절감된다는 것을 의미합니다.
구글 딥마인드는 책임감 있는 AI 개발의 중요성을 강조합니다. 사전 학습 데이터 필터링, 다양한 안전성과 관련된 벤치마크에 대한 종합적인 테스트 등 엄격한 환경에서 모델을 학습시켰다고 명시되어 있습니다.
또한, 구글 딥마인드는 다양한 AI 과제를 해결하기 위해 새로운 아키텍처와 관련된 연구를 계속할 것이라고 합니다. 이러한 연구에는 곧 공개될 낮은 접근성과 강력한 성능, 두 마리 토끼를 잡을 수 있도록 설계된 2.6B 크기의의 매개변수를 가진 Gemma 2 모델이 포함됩니다.
How to use Gemma 2?
Gemma 2는 네이티브 Keras 3.0, vLLM, Gemma.cpp, Llama.cpp를 통해 Hugging Face Transformers, JAX, PyTorch, TensorFlow와 같은 주요 AI 프레임워크와 호환됩니다.
또한 Google AI Studio 및 Google Vertex AI에서도 Gemma 2를 사용할 수 있습니다.
Evaluation Framework
Gemma 2를 평가하기 위해 사용된 데이터는 Topic Dataset입니다.
이 데이터 세트는 50개의 서로 다른 주제로 분류된 200개 문장으로 구성되어 있습니다.
해결해야 할 과제는 각 문장을 올바른 주제로 분류하는 것이며, 이를 통해 언어별 정확도를 측정할 수 있습니다.
원글에서는 해당 데이터를 gpt-4를 이용하여 번역해 평가를 진행하였다고 명시되어 있습니다.
Results — Gemma 2 vs. Open Source
이 글의 가장 큰 목적은 Gemma 2의 성능과 최신 LLM을 비교하는 것입니다.
Meta의 Llama 3, Microsoft의 Phi3, Alibaba의 Qwen2 등 주요 오픈 소스 LLM의 8비트 양자화 버전을 선택했는데, 모두 오픈 소스 LLM입니다.
- Llama 3 (8B) (Released April 18, 2024) (Blog post)
- Phi3 (14B) (Released April 23, 2024) (Blog post)
- Qwen2 (7B) (Released June 7, 2024) (Blog post)
첫 번째 단계는 모든 모델에서 평가 프레임워크를 실행하여 각 언어 별 정확도 점수를 계산하였고,
그런 다음 아래와 같이 언어 별 모델의 성능을 시각화하였습니다.
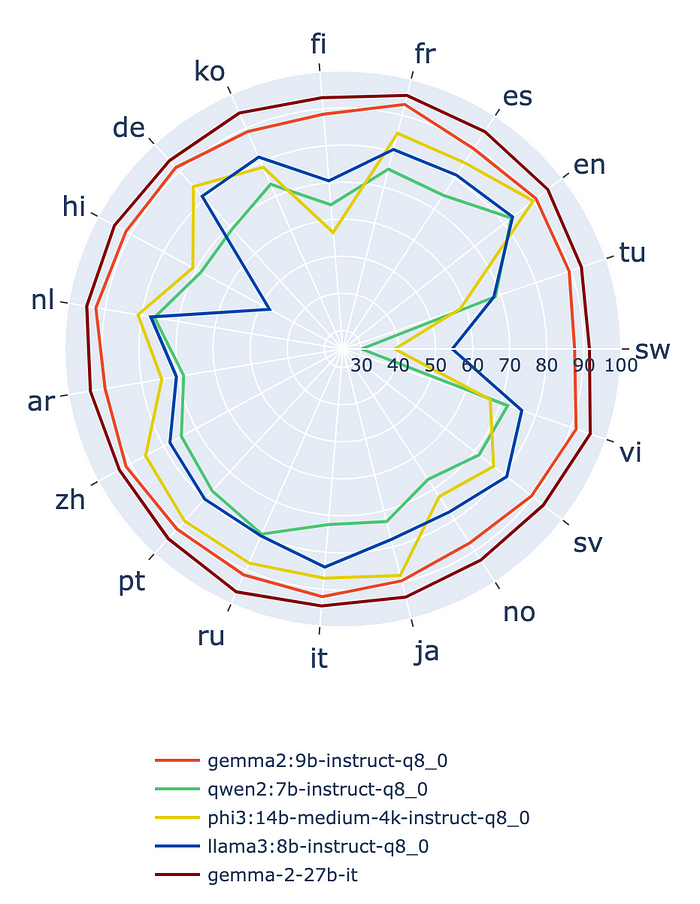
위의 그래프에서 볼 수 있듯이 Gemma 2는 다국어 언어 이해에서 다른 오픈 모델보다 훨씬 뛰어난 성능을 발휘합니다.
Gemma 2-9B(8bit) 모델은 한국어, 힌디어와 같이 일반적으로 LLM에 어려운 언어를 포함한 모든 언어에서 탁월한 성능을 보여줍니다.
또한 더 큰 모델인 Gemma 2-27B(full precision) 모델은 모든 언어에서 훨씬 더 우수한 성능을 보였습니다.
Results — Gemma 2 vs. Closed-Source LLMs
원글에서는 Gemma 2를 OpenAI, Google, Anthropic의 저비용 LLM, 특히 GPT-3.5-turbo, Gemini 1.0 Pro, Gemini 1.5 Flash, Claude-3-haiku와 비교했습니다. 또한 비교 테스트에 sota Close-source LLM(claude-3.5-sonnet, Gemini 1.5 Pro, GPT-4o)도 포함했습니다.
이러한 비공개 소스 모델은 이전 오픈 소스 모델보다 성능이 눈에 띄게 우수하므로 보다 정확한 비교를 위해 Radar plot의 스케일을 조정해야 합니다.
기존 30점에서 100점까지 점수를 표시하는 대신 80점에서 100점으로 범위를 좁힙니다. 이렇게 조정하면 모델 간 성능 차이를 더 명확하게 파악할 수 있습니다.
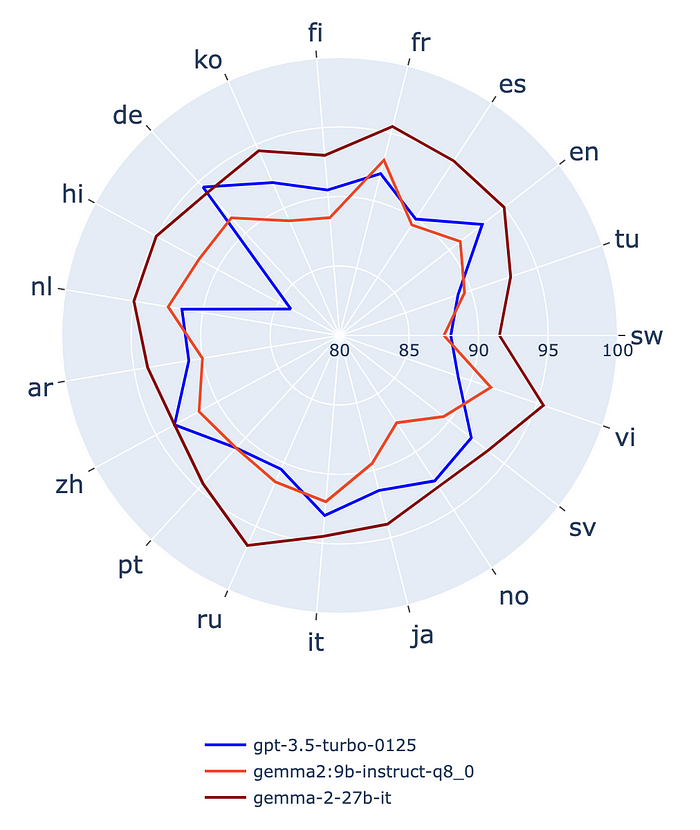
Gemma 2 vs. OpenAI’s GPT-3.5-Turbo
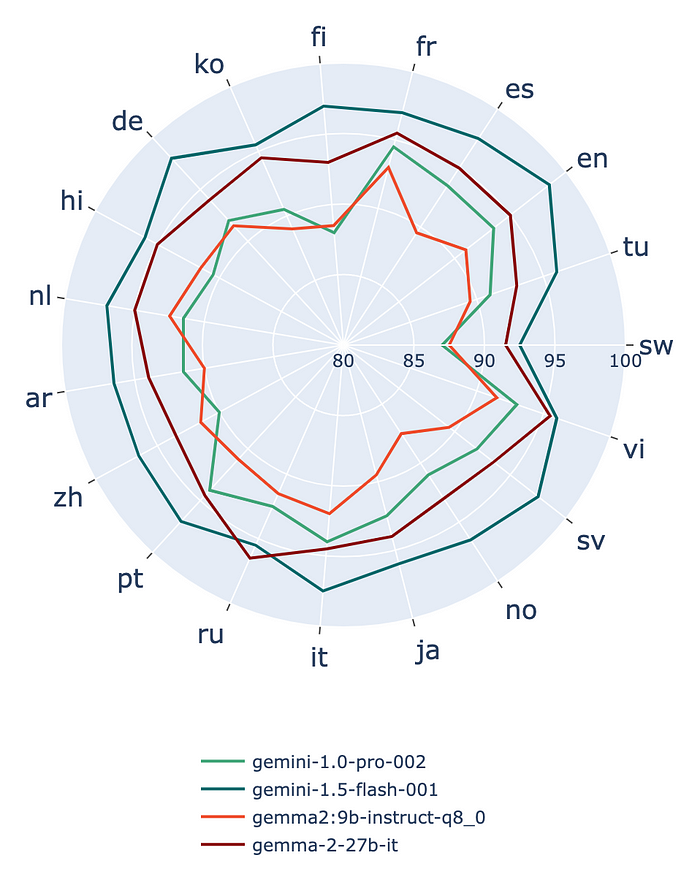
Gemma 2 vs. Google’s Gemini 1.0 Pro and Gemini 1.5 Flash
Gemma 2 vs. Anthropic’s Claude-3.5-Haiku

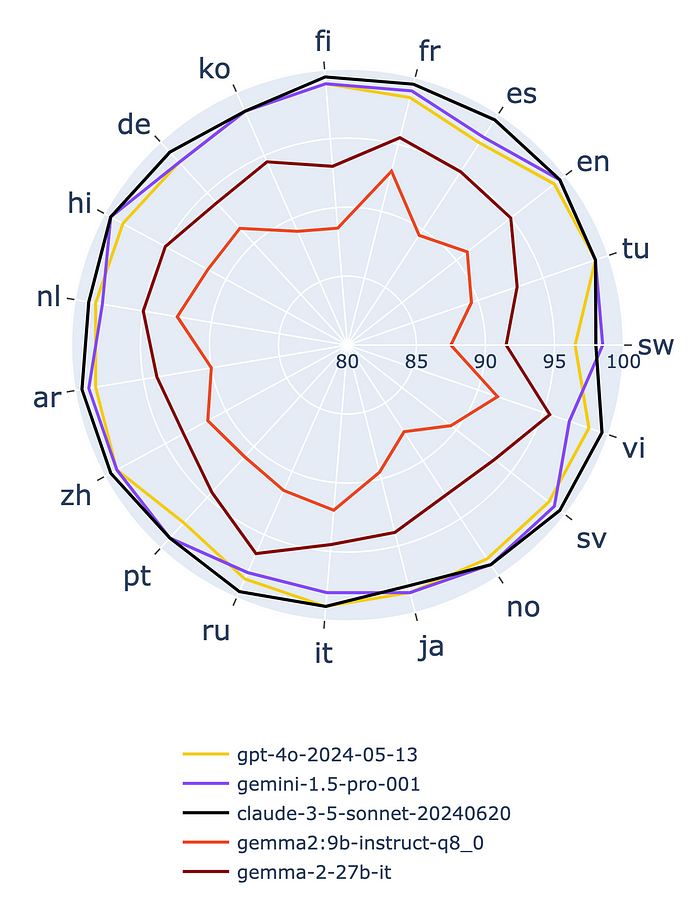
Gemma 2 vs. State-of-the-art Closed-Source LLMs
Aggregated Results
각 모델의 성능을 한눈에 파악하기 위해 모든 모델에 대해 barplot을 생성하였습니다.
그래프에서 Average Errors는 100 - mean(acc)로 계산됩니다. 이 접근 방식을 사용하면 모델의 성능을 명확하고 정확하게 표현할 수 있습니다.
오류율이 낮을수록 더 좋은 성능을 의미합니다.

Conclusion
언어별 높은 정확성
Gemma 2는 한국어, 힌디어, 핀란드어와 같이 LLMs에 일반적으로 어려운 언어를 포함하여 모든 언어에서 높은 정확성을 입증했습니다. 이러한 성능은 더 큰 규모의 Close-source model과 견줄 만합니다.
효율성과 성능
Gemma 2는 뛰어난 성능뿐만 아니라 효율성도 뛰어납니다. 특히 9B 양자화 모델은 낮은 비용의 Close-source LLMs 중 일부와 동일한 수준의 성능을 발휘하며, 로컬 모델의 새로운 기준을 제시합니다.
Close-source model 과의 경쟁력
OpenAI의 GPT-3.5-turbo와 Google의 Gemini 모델과 같은 낮은비용의 Close-source LLMs과 비교했을 때, Gemma 2는 인상적이며 일부 모델을 능가하기도 합니다. 특히 27B 모델은 GPT-3.5-turbo와 Gemini 1.0 Pro를 능가합니다.
한계와 미래 전망
고비용(sota)의 Close-source LLMs는 여전히 Gemma 2를 능가하지만, Gemma 2의 도입은 오픈 소스 다국어 언어 모델에서 중요한 발전을 나타내며 새로운 기준을 확립했습니다. 향후에는 낮은 접근성과 높은 성능의 균형을 맞춘 2.6B 파라미터 Gemma 2 모델이 출시될 예정입니다.
또한 강력하고 빠른 다국어 LLMs을 로컬에서 실행할 수 있게 되었으며, 이는 10GB 미만의 용량을 요구합니다. 이러한 발전은 더 많은 사람들이 AI 기술을 더 쉽게 접근할 수 있게 하며, 향후 on-device에서 활용될 가능성이 큽니다.
Reference
- https://storage.googleapis.com/deepmind-media/gemma/gemma-2-report.pdf
- Gemma 2 (9B & 27B) Evaluation — vs. Open/Closed-Source LLMs
'딥러닝 > LLM' 카테고리의 다른 글
| LLM의 다양한 SFT 기법: Full Fine-Tuning, PEFT (LoRA, QLoRA) (0) | 2024.08.06 |
|---|---|
| Supervised Fine-tuning: customizing LLMs (0) | 2024.08.06 |
| Pretraining LLMs (0) | 2024.07.31 |
| 데이콘 - 도배 하자 질의 응답 처리 후기 (0) | 2024.05.05 |
| Kaggle - LLM Science Exam 후기 (1) | 2023.10.23 |