서론
우리는 ChatGPT나 Gemini와 같은 서비스를 통해 LLM과 대화할 수 있습니다. 이러한 LLM들은 방대한 인터넷 데이터를 학습하여 사용자가 질문하는 거의 모든 질문에 답할 수 있습니다.
그러나, 이러한 모델에도 한계가 있습니다. 바로 학습한 이후의 최신 정보나 특정 도메인에 대한 지식이 부족하다는 점입니다. 이 문제를 해결하기 위한 기술로 RAG가 등장하게 되었습니다.
RAG란 무엇인가?
RAG는 Retrieval-Augmented Generation의 약자로, LLM의 성능을 향상하기 위해 외부 데이터를 검색하고 결합하는 방식을 의미합니다. 이 방식은 사용자가 묻는 질문에 대해 관련된 문서나 데이터를 검색하여, LLM에게 새롭고 다양한 정보(context)를 제공함으로써 답변의 정확성과 신뢰성을 높이는 것을 목표로 합니다.
요약하자면, RAG는 LLM이 최신 정보에 접근하거나 특정 도메인에 특화된 지식을 제공할 수 있도록 돕습니다.
RAG로 해결하려는 challenge: LLM의 한계
LLM은 방대한 데이터로 학습되었지만, 몇 가지 주요 문제가 있습니다.
- 최신 정보 부족: LLM은 한 번 학습된 데이터를 바탕으로 작동하기 때문에 새로운 사건이나 변화된 정보에 접근할 수 없습니다. 예를 들어, 2022년까지 학습된 LLM은 목성(Jupiter)이 가장 많은 위성을 가진 행성이라고 답할 것입니다. 하지만, 2023년에는 토성(Saturn)이 더 많은 위성을 가지게 되었기 때문에 최신 정보를 제공하지 못하는 문제가 발생합니다.
- 도메인 지식 부족: LLM은 학습한 데이터가 없거나 부족한 특정 도메인에 대한 질문에 대해 부정확하거나 제한적인 답변을 할 수 있습니다.
이러한 문제를 RAG가 어떻게 해결할 수 있을까요?
RAG의 작동 원리
RAG의 정의는 아래 그림으로 설명가능합니다.
Chatgpt를 통해 최근의 뉴스에 대한 내용을 문의하게 되면, 사전 학습 데이터의 제약으로 인해 제대로 된 결과를 얻을 수 없습니다. 하지만, RAG를 활용하면 외부 지식을 ChatGPT에게 전달할 수 있어 이러한 문제를 해결할 수 있습니다.
아래 예시는 실시간 정보 검색을 통해 모델의 응답을 향상시키는 기능을 보여주는 RAG의 프로세스입니다.
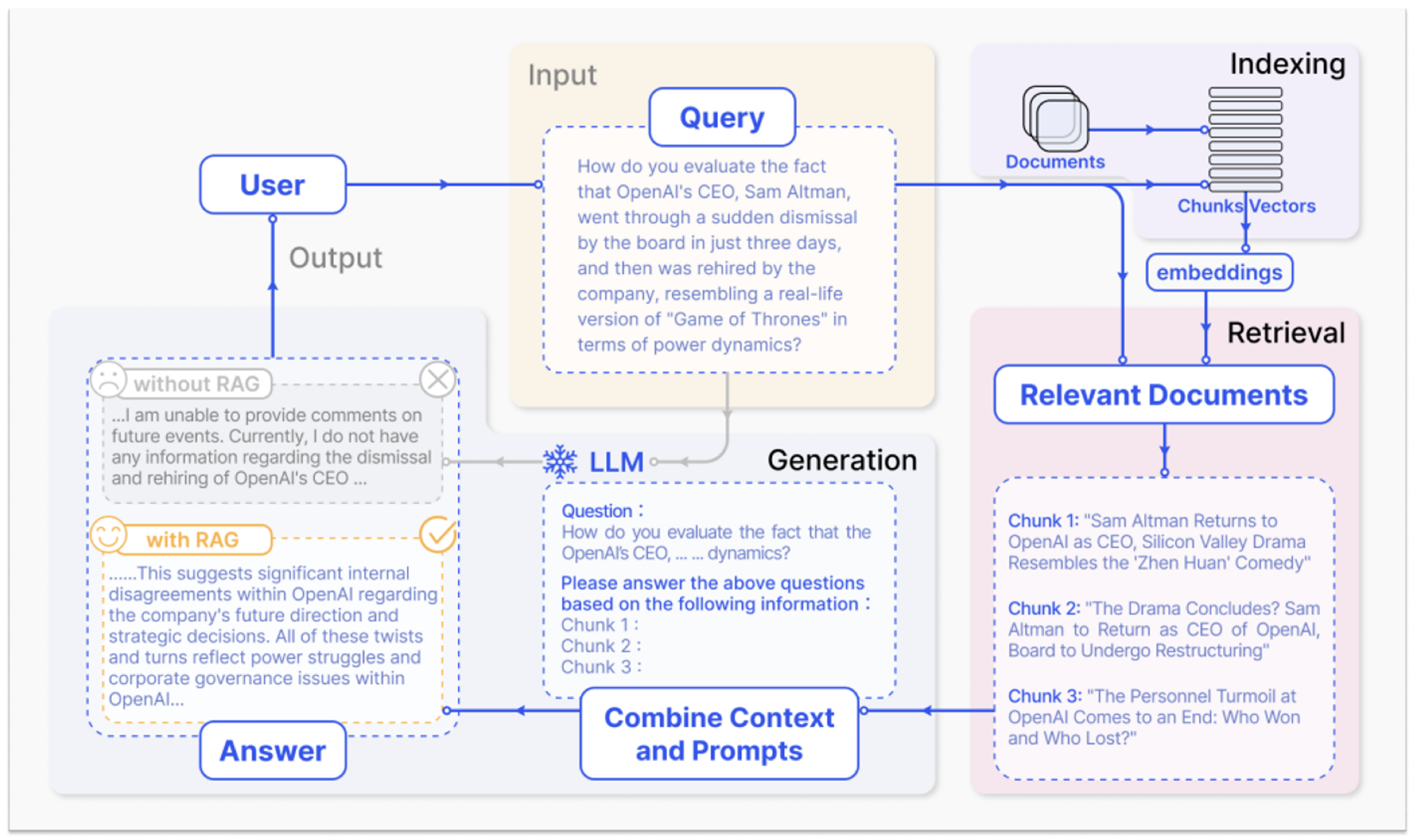
RAG의 작동 원리를 3단계로 요약하면 다음과 같습니다:
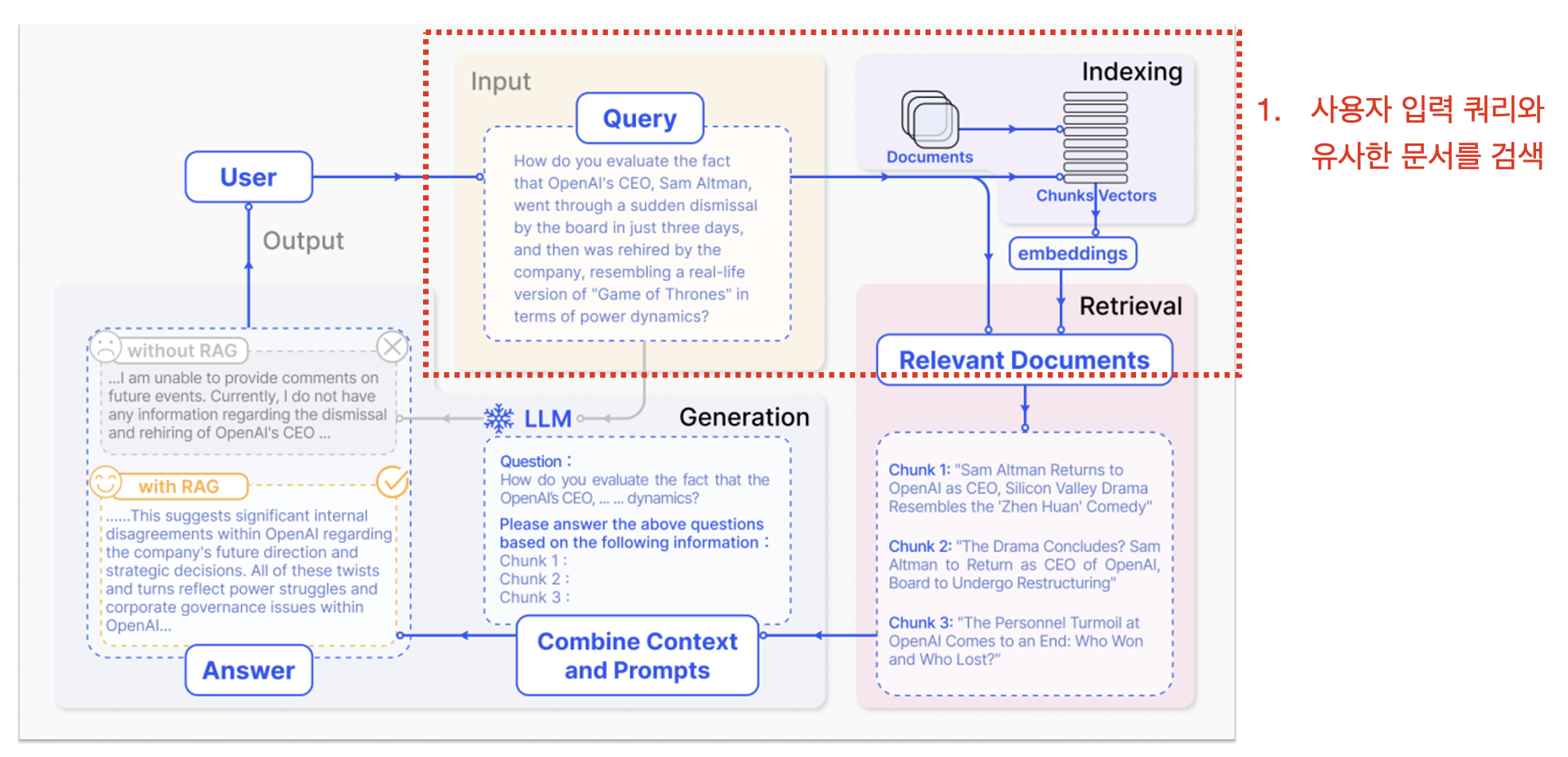
1. 입력 쿼리와 유사한 문서 검색:
- 사용자가 질문을 입력하면, RAG는 먼저 질문과 관련된 외부 문서나 데이터를 벡터 데이터베이스에서 검색합니다. 문서들은 임베딩(embedding) 형태로 저장되어 있으며, 입력 쿼리와 가장 유사한 문서들이 선택됩니다.
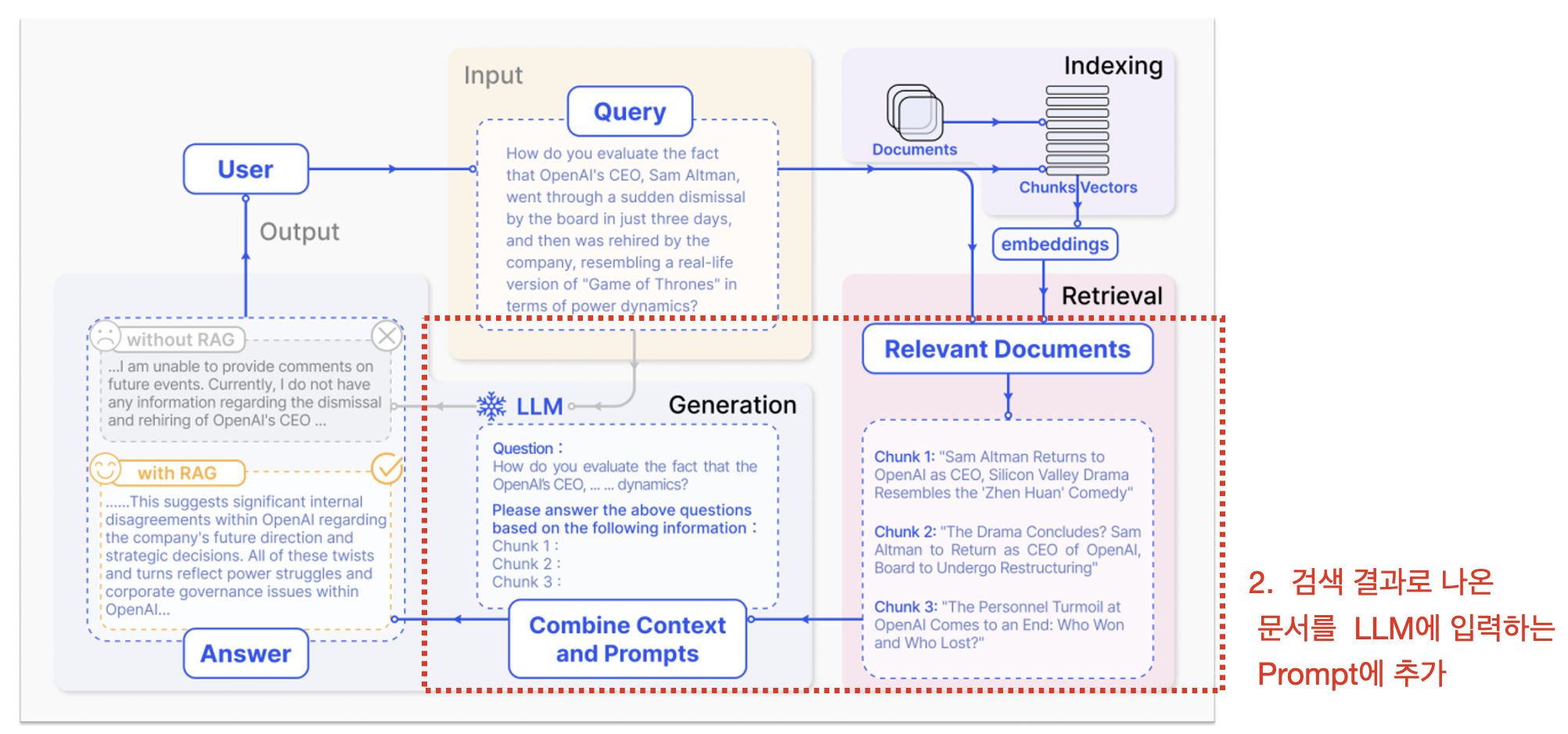
2. 유사한 문서를 원본 프롬프트에 결합:
- 검색된 유사 문서들은 사용자가 입력한 질문과 결합되어 LLM에게 제공됩니다. 이를 통해 LLM은 더 많은 정보(context)을 가지게 되며, 입력된 쿼리뿐만 아니라 추가적인 외부 정보까지 활용할 수 있게 됩니다.
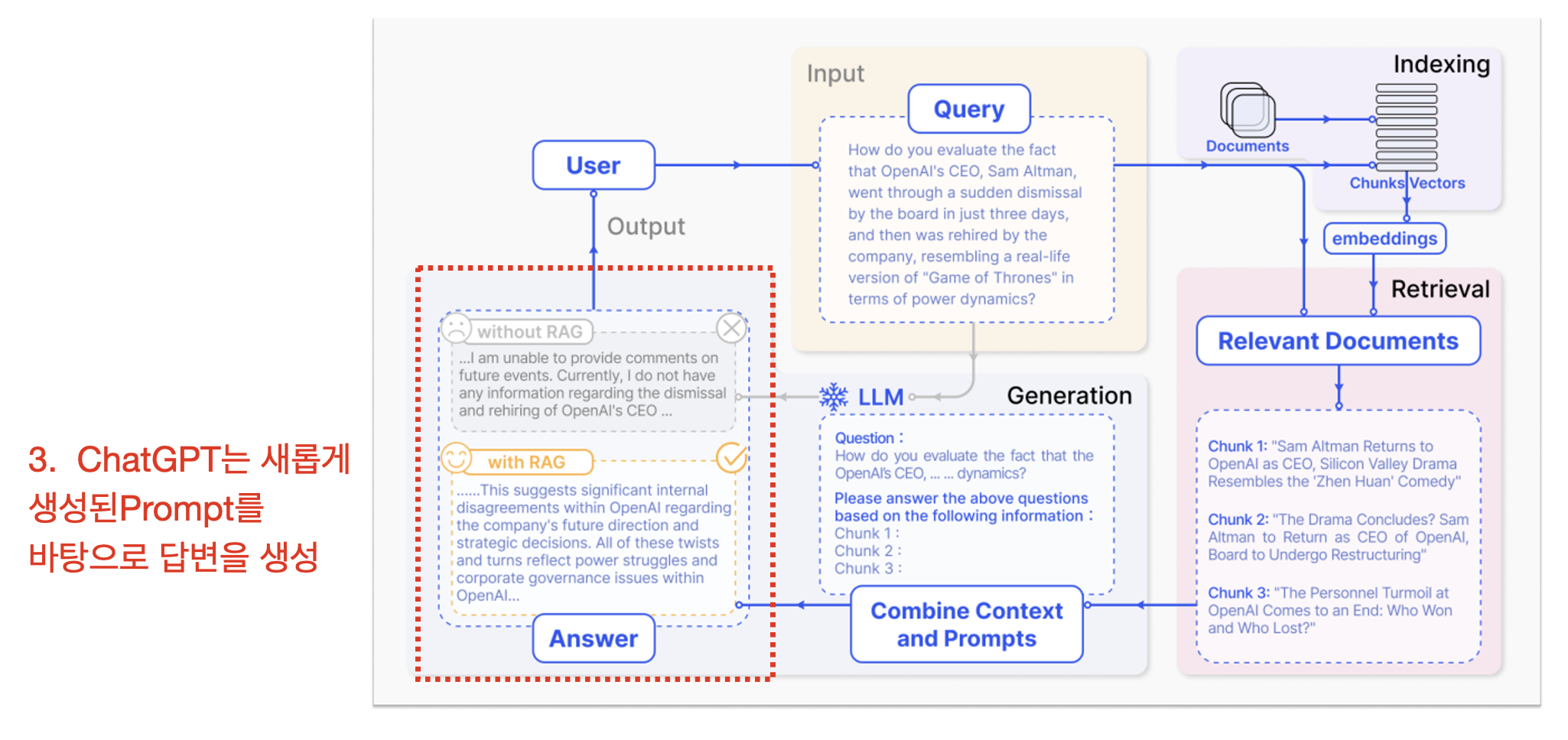
3. LLM을 통해 답변 생성:
- 마지막으로 LLM은 원본 질문과 결합된 추가 정보를 바탕으로 최종 답변을 생성합니다. 이 과정에서 LLM은 검색된 문서를 참고하여 더 정확하고 관련성 높은 답변을 제공합니다.
이러한 방식으로 RAG는 LLM의 한계를 극복하고, 최신 정보나 도메인 특화 지식을 기반으로 한 답변을 가능하게 합니다
RAG의 benefits과 challenges

RAG의 benefits
1. 정확하고 최신의 응답 제공:
- RAG 모델은 정적이고 오래된 학습 데이터에 의존하지 않고, 최신 정보를 활용하여 정확하고 시기적절한 응답을 생성합니다.
2. 환각(hallucination) 감소:
- 외부의 관련 지식에 초점을 맞추기 때문에 모델이 부정확하거나 단순히 만들어낸 정보를 제공할 위험을 줄입니다. 실제로, 출력 결과에 원본 출처를 인용할 수도 있어, 생성된 콘텐츠의 신뢰성을 사람이 쉽게 확인할 수 있습니다.
3. 도메인 특화 응답 제공:
- RAG는 조직의 독자적이거나 특정 도메인에 특화된 데이터를 바탕으로 정보에 맞는 맞춤형 응답을 제공할 수 있습니다.
4. 효율적이고 비용 효율적인 배포:
- RAG는 모델 자체를 사용자 정의할 필요가 없기 때문에, 도메인 특화 데이터를 활용하는 LLM을 훨씬 더 간단하고 비용 효율적으로 사용할 수 있습니다. 이는 특히 자주 새로운 데이터로 모델을 업데이트해야 하는 경우에 유리합니다.
5. 개선된 프라이버시:
- RAG의 소유자는 자신의 데이터를 직접 제어할 수 있습니다.
RAG의 challenges
그러나 RAG도 다른 LLM이나 AI 배포와 마찬가지로 주의 깊게 다뤄야 하는 몇 가지 challenges가 있습니다.
1. 편향 가능성:
- 가장 관련성이 높은 데이터를 선택하지 못하는 검색 모델은 출력에 큰 부정적 영향을 미칠 수 있습니다. 이는 학습 데이터의 편향에서 비롯될 수 있으며, 모델이 특정 유형의 데이터나 콘텐츠를 선호하는 경향을 보이는 경우도 있습니다. 따라서 중립적인 응답을 보장하는 것은 복잡하지만 필수적인 도전 과제입니다.
2. 모호성 처리:
- 검색된 정보(context)가 불분명하거나 의도가 부족한, 혹은 애매한 질문(쿼리)은 RAG 모델에 어려움을 줄 수 있습니다. RAG 모델은 입력 쿼리의 정확성에 크게 의존하기 때문에, 이로 인해 의도된 목적과 관련이 없는 콘텐츠가 생성될 수 있습니다.
결론
RAG는 LLM의 한계를 보완하여 최신 정보와 도메인 특화 지식을 제공하는 혁신적인 기술입니다. 이를 통해 LLM은 더욱 정확하고 신뢰성 있는 답변을 생성할 수 있으며, 환각 현상을 줄이고 효율성을 극대화할 수 있습니다.
특히, RAG는 모델 자체를 사용자 정의하지 않으면서도 최신 정보에 신속히 접근할 수 있게 해 주며, 이는 비용 절감과 프라이버시 보호 측면에서도 큰 이점을 제공합니다.
그러나 RAG의 도입에는 몇 가지 도전 과제가 따릅니다. 편향된 데이터를 선택하는 문제, 특정 도메인에서의 일반화 어려움, 애매한 질문 처리의 어려움 등이 그 예입니다. 이러한 문제들을 해결하고 더 나은 성능을 발휘하려면, 신중하고 정교한 관리가 필요합니다.
RAG는 여전히 진화 중인 기술이며, 지속적인 발전을 통해 다양한 산업 분야에서 더욱 큰 역할을 할 것입니다.
다음글에서는 RAG의 성능을 끌어올리기 위한 여러 기법에 대해 알아보도록 하겠습니다.
Reference
- What is RAG (Retrieval Augmented Generation) ?
- Retrieval-Augmented Generation (RAG): A Leap in Generative AI
- Retrieval-Augmented Generation for Large Language Models: A Survey
'딥러닝 > LLM' 카테고리의 다른 글
| LLM 효율성을 높이는 양자화 기법 탐구 및 성능 분석 (0) | 2024.11.12 |
|---|---|
| All you need to know about RAG (0) | 2024.10.09 |
| LLM을 활용한 지식 증류: sLLM 성능 최적화 실험 (5) | 2024.09.01 |
| LLM의 양자화가 한국어에 미치는 영향 (0) | 2024.08.19 |
| [논문리뷰] How Does Quantization Affect Multilingual LLMs? (0) | 2024.08.12 |
서론
우리는 ChatGPT나 Gemini와 같은 서비스를 통해 LLM과 대화할 수 있습니다. 이러한 LLM들은 방대한 인터넷 데이터를 학습하여 사용자가 질문하는 거의 모든 질문에 답할 수 있습니다.
그러나, 이러한 모델에도 한계가 있습니다. 바로 학습한 이후의 최신 정보나 특정 도메인에 대한 지식이 부족하다는 점입니다. 이 문제를 해결하기 위한 기술로 RAG가 등장하게 되었습니다.
RAG란 무엇인가?
RAG는 Retrieval-Augmented Generation의 약자로, LLM의 성능을 향상하기 위해 외부 데이터를 검색하고 결합하는 방식을 의미합니다. 이 방식은 사용자가 묻는 질문에 대해 관련된 문서나 데이터를 검색하여, LLM에게 새롭고 다양한 정보(context)를 제공함으로써 답변의 정확성과 신뢰성을 높이는 것을 목표로 합니다.
요약하자면, RAG는 LLM이 최신 정보에 접근하거나 특정 도메인에 특화된 지식을 제공할 수 있도록 돕습니다.
RAG로 해결하려는 challenge: LLM의 한계
LLM은 방대한 데이터로 학습되었지만, 몇 가지 주요 문제가 있습니다.
- 최신 정보 부족: LLM은 한 번 학습된 데이터를 바탕으로 작동하기 때문에 새로운 사건이나 변화된 정보에 접근할 수 없습니다. 예를 들어, 2022년까지 학습된 LLM은 목성(Jupiter)이 가장 많은 위성을 가진 행성이라고 답할 것입니다. 하지만, 2023년에는 토성(Saturn)이 더 많은 위성을 가지게 되었기 때문에 최신 정보를 제공하지 못하는 문제가 발생합니다.
- 도메인 지식 부족: LLM은 학습한 데이터가 없거나 부족한 특정 도메인에 대한 질문에 대해 부정확하거나 제한적인 답변을 할 수 있습니다.
이러한 문제를 RAG가 어떻게 해결할 수 있을까요?
RAG의 작동 원리
RAG의 정의는 아래 그림으로 설명가능합니다.
Chatgpt를 통해 최근의 뉴스에 대한 내용을 문의하게 되면, 사전 학습 데이터의 제약으로 인해 제대로 된 결과를 얻을 수 없습니다. 하지만, RAG를 활용하면 외부 지식을 ChatGPT에게 전달할 수 있어 이러한 문제를 해결할 수 있습니다.
아래 예시는 실시간 정보 검색을 통해 모델의 응답을 향상시키는 기능을 보여주는 RAG의 프로세스입니다.
RAG의 작동 원리를 3단계로 요약하면 다음과 같습니다:
1. 입력 쿼리와 유사한 문서 검색:
- 사용자가 질문을 입력하면, RAG는 먼저 질문과 관련된 외부 문서나 데이터를 벡터 데이터베이스에서 검색합니다. 문서들은 임베딩(embedding) 형태로 저장되어 있으며, 입력 쿼리와 가장 유사한 문서들이 선택됩니다.
2. 유사한 문서를 원본 프롬프트에 결합:
- 검색된 유사 문서들은 사용자가 입력한 질문과 결합되어 LLM에게 제공됩니다. 이를 통해 LLM은 더 많은 정보(context)을 가지게 되며, 입력된 쿼리뿐만 아니라 추가적인 외부 정보까지 활용할 수 있게 됩니다.
3. LLM을 통해 답변 생성:
- 마지막으로 LLM은 원본 질문과 결합된 추가 정보를 바탕으로 최종 답변을 생성합니다. 이 과정에서 LLM은 검색된 문서를 참고하여 더 정확하고 관련성 높은 답변을 제공합니다.
이러한 방식으로 RAG는 LLM의 한계를 극복하고, 최신 정보나 도메인 특화 지식을 기반으로 한 답변을 가능하게 합니다
RAG의 benefits과 challenges
RAG의 benefits
1. 정확하고 최신의 응답 제공:
- RAG 모델은 정적이고 오래된 학습 데이터에 의존하지 않고, 최신 정보를 활용하여 정확하고 시기적절한 응답을 생성합니다.
2. 환각(hallucination) 감소:
- 외부의 관련 지식에 초점을 맞추기 때문에 모델이 부정확하거나 단순히 만들어낸 정보를 제공할 위험을 줄입니다. 실제로, 출력 결과에 원본 출처를 인용할 수도 있어, 생성된 콘텐츠의 신뢰성을 사람이 쉽게 확인할 수 있습니다.
3. 도메인 특화 응답 제공:
- RAG는 조직의 독자적이거나 특정 도메인에 특화된 데이터를 바탕으로 정보에 맞는 맞춤형 응답을 제공할 수 있습니다.
4. 효율적이고 비용 효율적인 배포:
- RAG는 모델 자체를 사용자 정의할 필요가 없기 때문에, 도메인 특화 데이터를 활용하는 LLM을 훨씬 더 간단하고 비용 효율적으로 사용할 수 있습니다. 이는 특히 자주 새로운 데이터로 모델을 업데이트해야 하는 경우에 유리합니다.
5. 개선된 프라이버시:
- RAG의 소유자는 자신의 데이터를 직접 제어할 수 있습니다.
RAG의 challenges
그러나 RAG도 다른 LLM이나 AI 배포와 마찬가지로 주의 깊게 다뤄야 하는 몇 가지 challenges가 있습니다.
1. 편향 가능성:
- 가장 관련성이 높은 데이터를 선택하지 못하는 검색 모델은 출력에 큰 부정적 영향을 미칠 수 있습니다. 이는 학습 데이터의 편향에서 비롯될 수 있으며, 모델이 특정 유형의 데이터나 콘텐츠를 선호하는 경향을 보이는 경우도 있습니다. 따라서 중립적인 응답을 보장하는 것은 복잡하지만 필수적인 도전 과제입니다.
2. 모호성 처리:
- 검색된 정보(context)가 불분명하거나 의도가 부족한, 혹은 애매한 질문(쿼리)은 RAG 모델에 어려움을 줄 수 있습니다. RAG 모델은 입력 쿼리의 정확성에 크게 의존하기 때문에, 이로 인해 의도된 목적과 관련이 없는 콘텐츠가 생성될 수 있습니다.
결론
RAG는 LLM의 한계를 보완하여 최신 정보와 도메인 특화 지식을 제공하는 혁신적인 기술입니다. 이를 통해 LLM은 더욱 정확하고 신뢰성 있는 답변을 생성할 수 있으며, 환각 현상을 줄이고 효율성을 극대화할 수 있습니다.
특히, RAG는 모델 자체를 사용자 정의하지 않으면서도 최신 정보에 신속히 접근할 수 있게 해 주며, 이는 비용 절감과 프라이버시 보호 측면에서도 큰 이점을 제공합니다.
그러나 RAG의 도입에는 몇 가지 도전 과제가 따릅니다. 편향된 데이터를 선택하는 문제, 특정 도메인에서의 일반화 어려움, 애매한 질문 처리의 어려움 등이 그 예입니다. 이러한 문제들을 해결하고 더 나은 성능을 발휘하려면, 신중하고 정교한 관리가 필요합니다.
RAG는 여전히 진화 중인 기술이며, 지속적인 발전을 통해 다양한 산업 분야에서 더욱 큰 역할을 할 것입니다.
다음글에서는 RAG의 성능을 끌어올리기 위한 여러 기법에 대해 알아보도록 하겠습니다.
Reference
- What is RAG (Retrieval Augmented Generation) ?
- Retrieval-Augmented Generation (RAG): A Leap in Generative AI
- Retrieval-Augmented Generation for Large Language Models: A Survey
'딥러닝 > LLM' 카테고리의 다른 글
| LLM 효율성을 높이는 양자화 기법 탐구 및 성능 분석 (0) | 2024.11.12 |
|---|---|
| All you need to know about RAG (0) | 2024.10.09 |
| LLM을 활용한 지식 증류: sLLM 성능 최적화 실험 (5) | 2024.09.01 |
| LLM의 양자화가 한국어에 미치는 영향 (0) | 2024.08.19 |
| [논문리뷰] How Does Quantization Affect Multilingual LLMs? (0) | 2024.08.12 |