
서론
본 글은 LinkedIn에 AWS GenAI Lead인 Eduardo Ordax가 공유한 글을 기반으로 작성된 글입니다.
글의 내용이 많기 때문에 기술 설명에 필요한 추가 설명은 최소한으로 하였습니다.
글의 순서는 다음과 같습니다.
- Why RAG? Explanation of Naive RAG and Chunking Strategies
- Advance RAG Techniques
- RAG Generation
- RAG Evaluation
Why RAG? Explanation of Naive RAG and Chunking Strategies
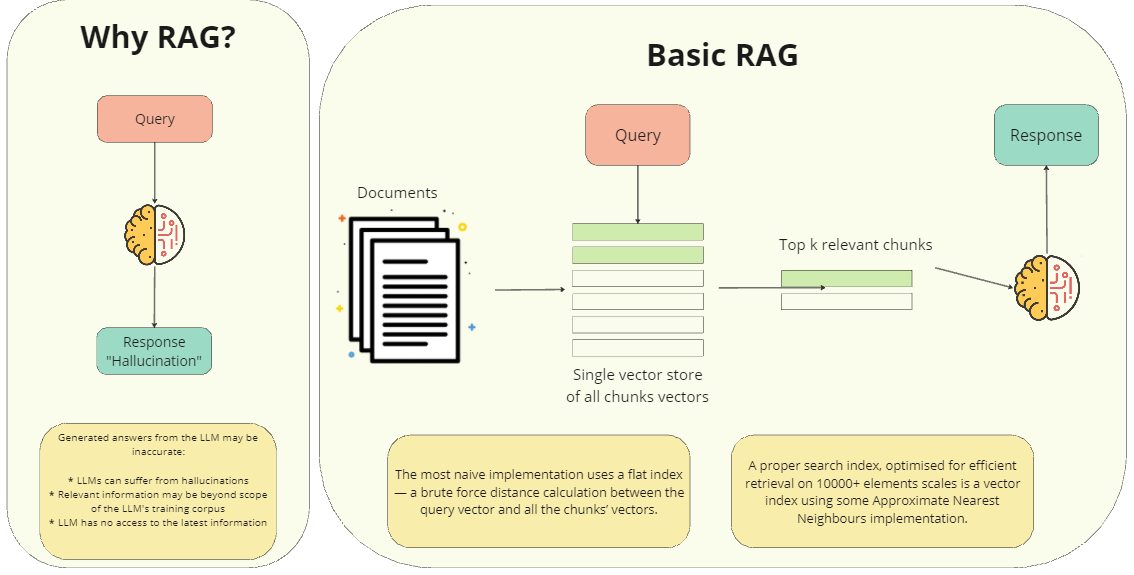
Why RAG ?
왜 RAG를 사용해야 할까요? 그 이유는 LLM에서 생성된 답변이 다음과 같은 이유로 부정확할 수 있기 때문입니다.
- LLM은 환각을 겪을 수 있습니다.
- 관련 정보가 LLM의 학습 코퍼스 범위를 벗어날 수 있습니다.
- LLM은 최신 정보에 액세스할 수 없습니다.
Basic RAG
- 문서 (Documents): 모델이 참조하는 다양한 종류의 텍스트 데이터입니다. 책, 논문, 뉴스 기사 등 다양한 형태의 정보가 포함될 수 있습니다.
- 단일 벡터 저장소 (Single vector store): 모든 문서를 벡터(수치 표현)로 변환하여 저장하는 공간입니다. 각 벡터는 해당 문서의 의미를 수치적으로 나타내며, 이를 통해 모델은 문서 간의 유사도를 빠르게 계산할 수 있습니다.
- 쿼리 (Query): 사용자가 모델에게 질문하는 내용입니다.
- 상위 k개의 관련 청크 (Top k relevant chunks): 쿼리와 가장 유사한 벡터를 가진 문서의 일부분(청크)을 추출합니다. 즉, 쿼리에 대한 답변과 관련이 높은 정보를 찾는 과정입니다.
- 응답 (Response): 추출된 청크를 바탕으로 LLM이 최종적인 답변을 생성합니다. LLM은 추출된 정보를 종합하여 사용자의 질문에 대한 의미 있는 답변을 만들어냅니다.
Basic RAG에서는 입력 쿼리 벡터와 모든 chunk vectors간의 거리를 계산하여 사용합니다.
하지만 chunk의 갯수가 많이 진다면 모든 chunk vectors간의 거리를 계산하는 것은 비효율적인 접근 방식이며, 대략적인 근사 이웃을 구하는 방법이 효율적인 접근 방법일 수 있습니다.
Chunking
RAG(Retrieval-Augmented Generation) 시스템에서 chunking 작업은 대규모 문서를 더 작고 관리하기 쉬운 단위로 나누는 과정입니다. chunking방법은 여러가지가 있으며, 방법에 따라 RAG 시스템의 성능과 효율성을 크게 향상시킬수 있기 때문에 어떤 chunking 방법을 사용할지 결정하는것은 매우 중요한 단계입니다.
FIXED-SIZE CHUNKING
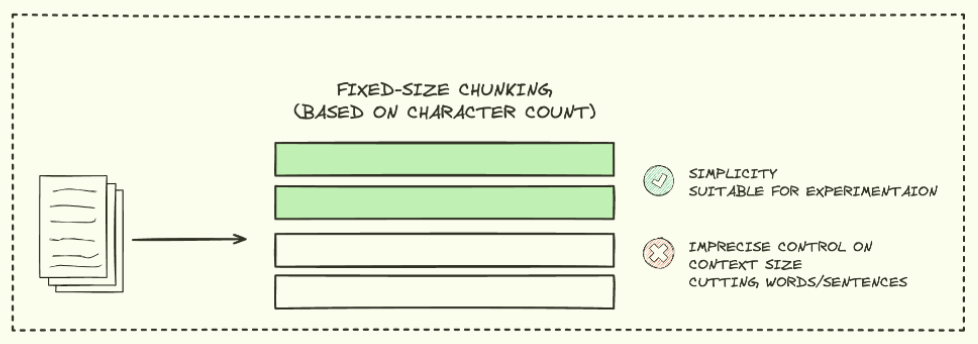
Fixed-size chunking 방법은 가장 간단하고 일반적인 chunking 방법입니다.
텍스트를 미리 정해진 크기(문자, 단어, 토큰 수)로 균일하게 나눕니다. 구현이 간단하고 계산 효율성이 높다는 특징을 가집니다.
그러나 문장이나 단어를 중간에 자를 수 있어 의미 단위를 해칠 수 있다는 단점이 존재합니다.
STRUCTURE AWARE CHUNKING
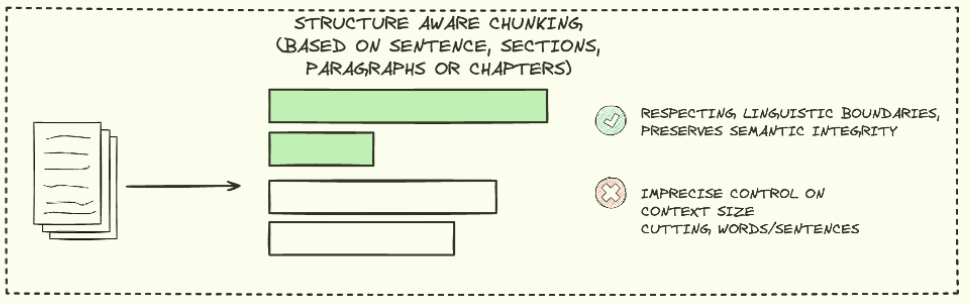
Structure aware chunking 방법은 문서의 구조를 고려하여 chunk를 생성하는 방법입니다.
문서의 구조(제목, 단락, 목록)을 기반으로 chunk를 생성하며, Markdown, LaTex등 구조화된 문서에 특히 유용합니다.
그러나 문서 구조에 따라 chunk 크기가 불균일하다는 단점을 가집니다.
CONTENT AWARE CHUNKING
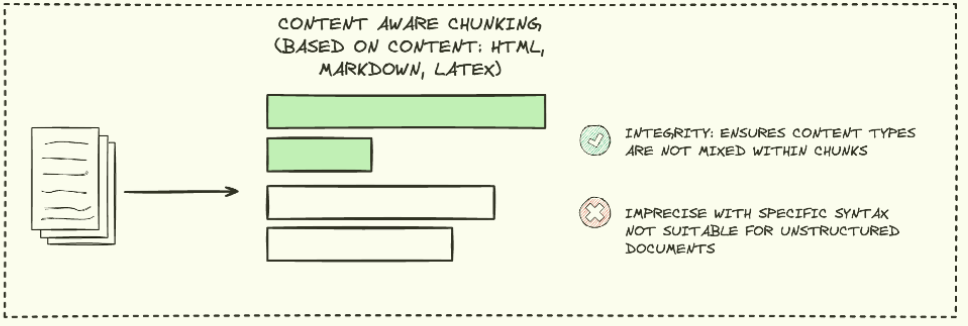
Content aware chunking 방법은 chunk 내에 다른 유형의 문서들이 혼합되지 않도록 보장하는 chunking 방법입니다.
문서를 유형 별(HTML, Markdown), 문장/문단 단위로 나눠 의미적 일관성을 유지한다는 특징을 가집니다.
하지만 텍스트 구조가 명확하지 않은 경우 성능이 저하되고, 문장이나 문단이 길 경우 chunk 크기가 커질 수 있습니다.
FIXED-SIZE CHUNKING + OVERAPPING SEGMENTS
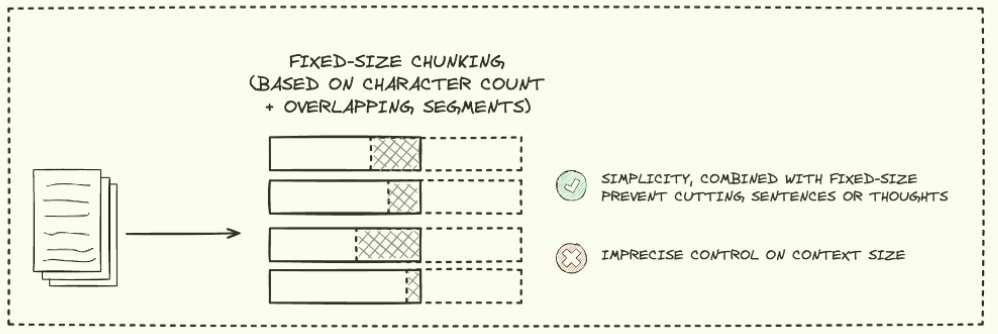
Fixed-size chunking처럼 미리 정의된 고정 크기의 chunk로 문서를 나누되, 각 chunk 간에 일정 부분 겹치응 영역을 두는 방식입니다.
overap을 통해 chunk간의 연속성을 보장하며, 문장이 중간에 잘리는 것을 어느정도 방지합니다.
하지만 마찬가지로 텍스트의 의미 구조를 완전히 고려하지 않기 때문에, 중요한 정보가 분리될 수 있으며 overlap으로 인한 중복된 정보가 생길 수 있습니다.
RECURSIVE CHUNKING
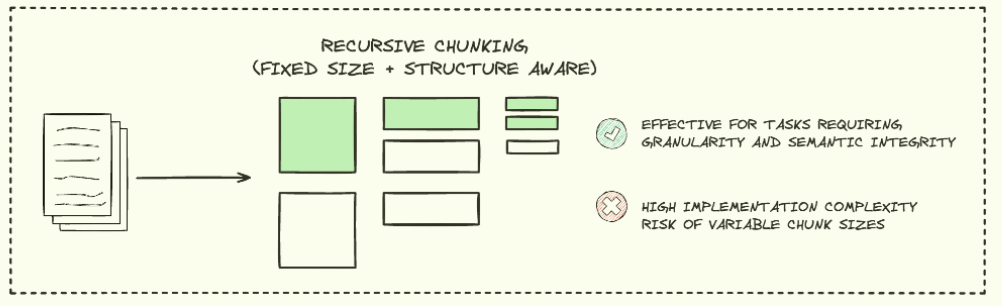
Recursive chunking은 문서를 재귀적으로 분할하여 계층적 구조를 만드는 방법입니다.
큰 문서를 점진적으로 작은 단위로 나누며, 문서의 구조와 의미를 유지하면서 다양한 크기의 chunk를 생성 할 수 있습니다.
그러나 구현이 복잡하고 계산 비용이 높을 수 있다는 단점이 있습니다.
NLP CHUNKING
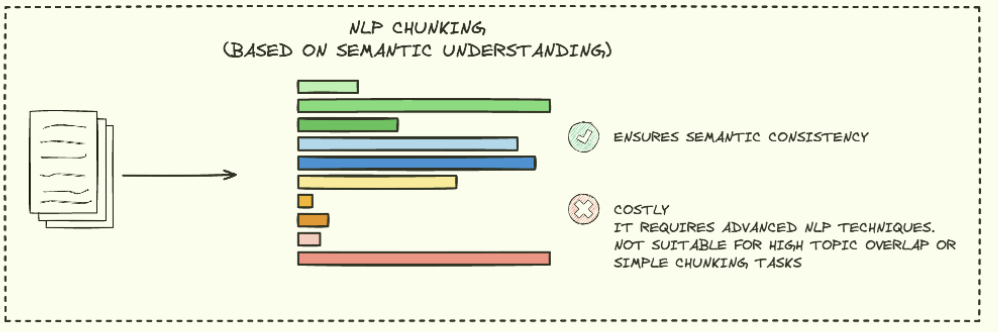
NLP chunking 방법은 자연어 처리 기술을 활용하여 텍스트를 의미있는 단위로 분할하는 방법입니다.
문장 분리, 명사구 추출 등 다양한 NLP 기술을 활용하여 언어의 문법적, 의미적 구조를 고려하여 chunk를 생성합니다.
그러나 어떤 언어모델을 사용하느냐에 따라 결과가 달라지며, 다국어 처리에서도 어려움을 겪을 수 있습니다.
AGENTIC CHUNKING

AI 에이전트(LLM)이 chunk에 포함할 텍스트의 길이와 종류를 결정하는 방법입니다.
이론적으로는 기존 chunking 방법들 보다 뛰어난 성능이 보장되지만, 비용이 많이들고 구현이 복잡하다는 단점이 존재합니다.
Advance RAG Techniques
Basic Index Retrieval + Metadata
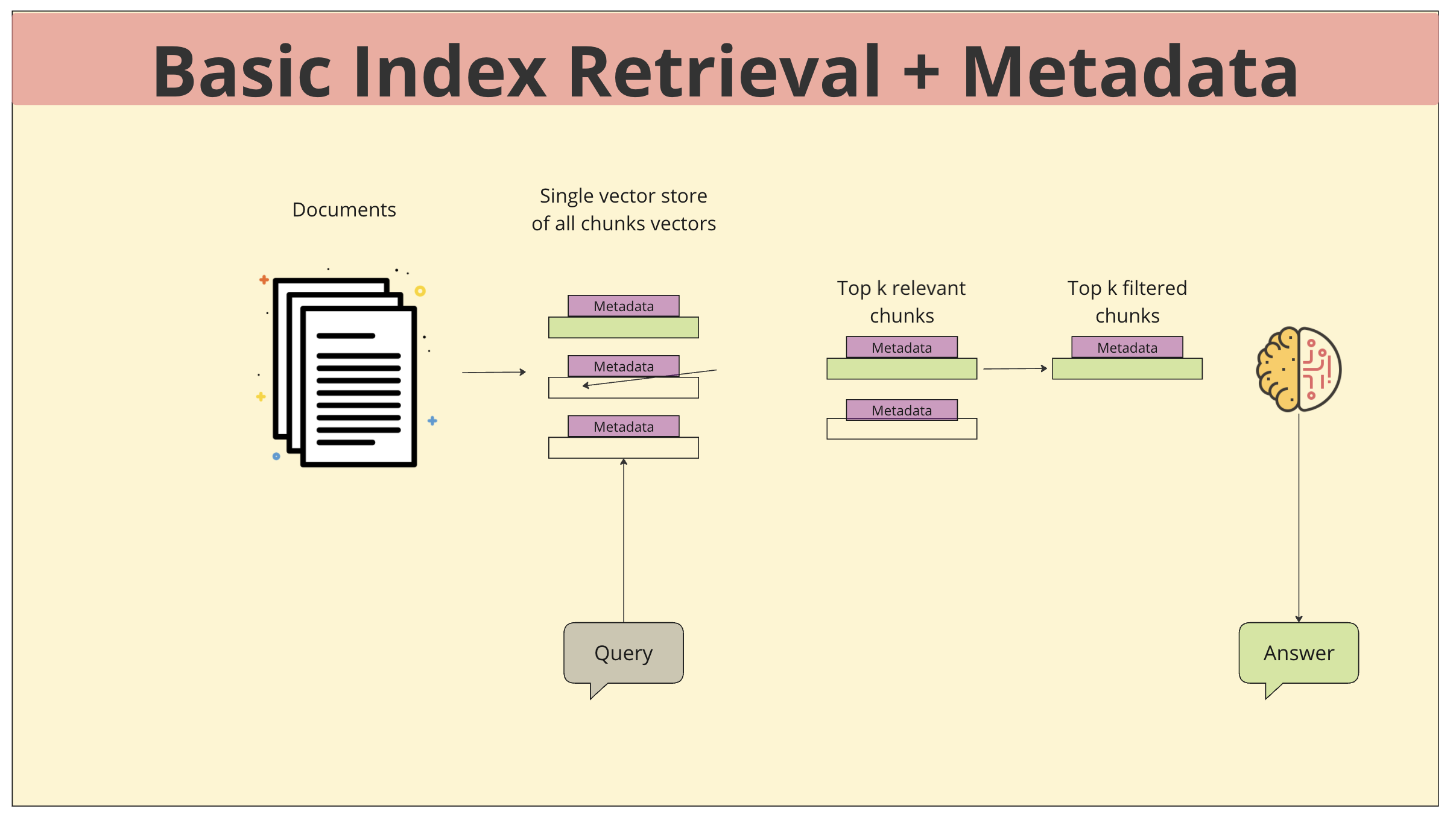
- Documnet: 다양한 문서들이 수집되고, 각 문서에 대한 추가적인 정보(메타데이터)가 함께 저장됩니다. 메타데이터는 문서의 제목, 작성자, 작성 날짜, 카테고리 등과 같은 정보를 포함하여 문서를 더 정확하게 설명하고 검색을 효율적으로 수행하는 데 도움을 줍니다.
- Vector store: 모든 문서는 의미를 수치적으로 표현하는 벡터로 변환되어 단일 벡터 저장소에 저장됩니다. 이 벡터는 문서의 내용을 변환한 것으로, 쿼리와의 유사도를 측정하는 데 사용됩니다.
- 쿼리 입력: 사용자가 질문이나 요청을 입력하면, 이 쿼리도 벡터로 변환됩니다.
- Tok k relevant chunks: 시스템은 쿼리 벡터와 가장 유사한 벡터를 가진 상위 k개의 문서 청크를 검색합니다.
- 추가 필터링: 검색된 청크들 중에서 메타데이터를 기반으로 추가적인 필터링을 수행합니다. 예를 들어, 특정 작성자의 문서만 추출하거나, 최근 작성된 문서만 선택하는 등의 작업이 가능합니다.
- 응답 생성: 최종적으로 선택된 청크들을 기반으로 대규모 언어 모델(LLM)이 답변을 생성합니다. LLM은 선택된 청크들의 정보를 종합하여 사용자의 질문에 대한 답변을 생성합니다.
Parent-child chunks Retrieval
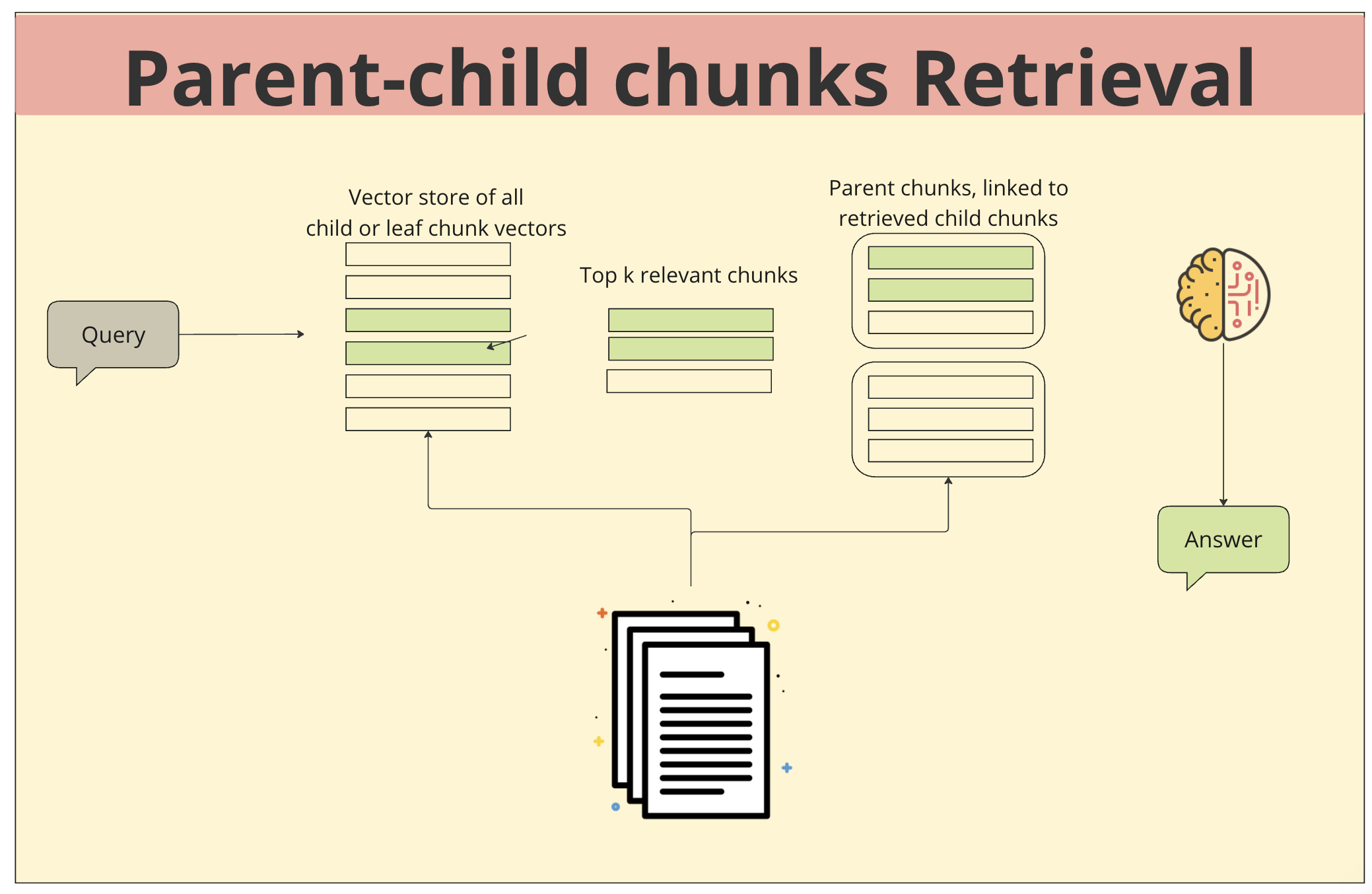
- 문서 및 청크: 문서를 chunk로 나눌때, 각 chunk는 부모-자식 관계를 형성하며, 이는 문서의 구조를 반영합니다. 예를 들어, 한 문서의 제목은 해당 문서의 모든 문장에 대한 부모 청크가 될 수 있습니다.
- 벡터 저장소: 모든 청크는 의미를 수치적으로 표현하는 벡터로 변환되어 단일 vector store에 저장됩니다.
- 쿼리 입력: 사용자가 질문이나 요청을 입력하면, 이 쿼리도 벡터로 변환됩니다.
- Tok k relevant chunks : 시스템은 쿼리 벡터와 가장 유사한 벡터를 가진 상위 k개의 청크를 검색합니다.
- 부모 청크 검색: 검색된 청크의 부모 청크를 찾아 추가적인 정보를 확보합니다. 이를 통해 더욱 넓은 맥락에서 쿼리에 대한 답변을 생성할 수 있습니다.
- 응답 생성: 최종적으로 선택된 청크들과 부모 청크들을 기반으로 대규모 언어 모델(LLM)이 답변을 생성합니다. LLM은 선택된 청크들의 정보를 종합하여 사용자의 질문에 대한 답변을 생성합니다.
Query Transformation
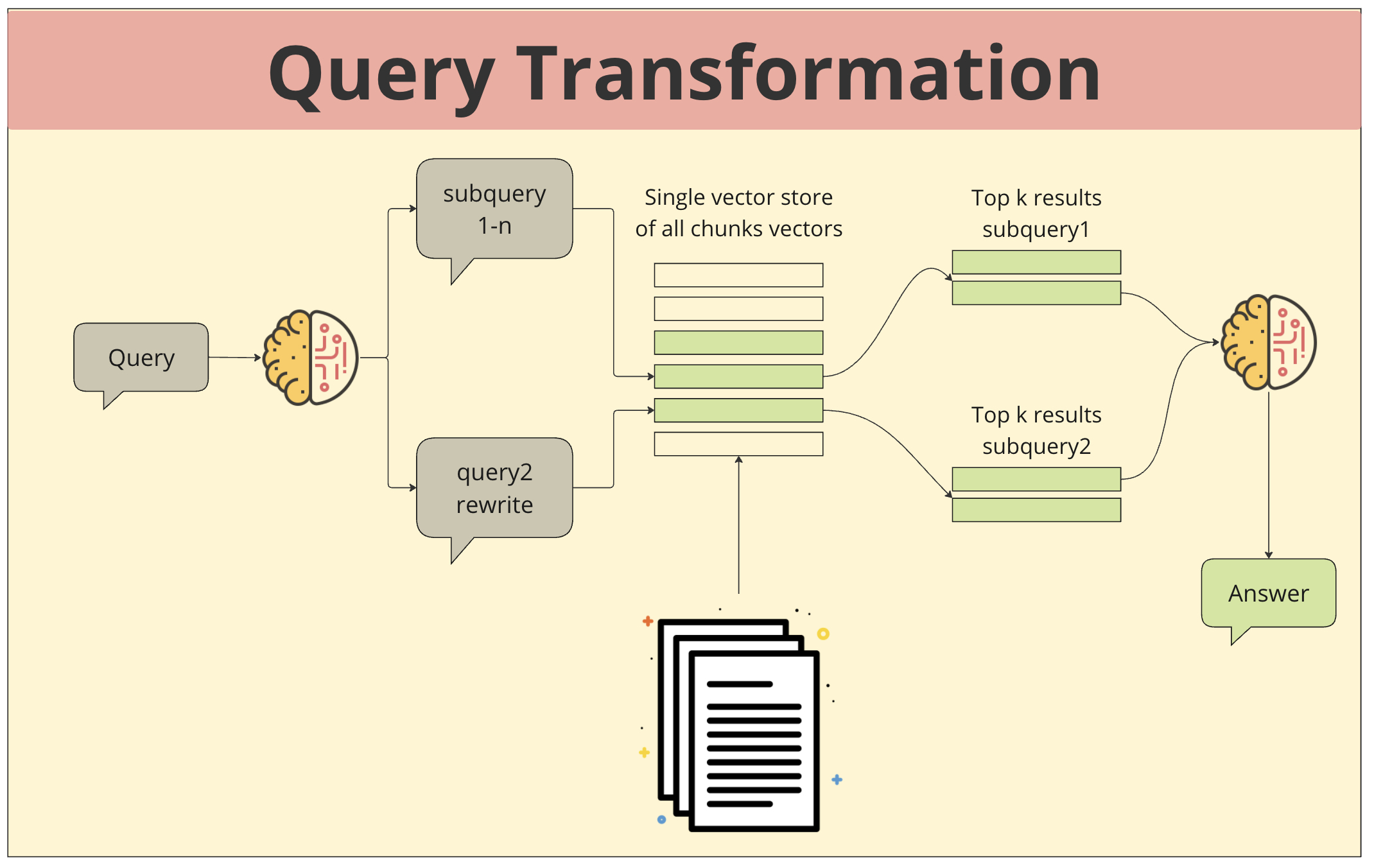
- 쿼리 입력: 사용자가 질문이나 요청을 입력합니다.
- 쿼리 분해: 입력된 쿼리가 여러 개의 하위 쿼리(subquery)로 분해됩니다. 이는 쿼리의 의미를 더욱 세분화하고, 다양한 관점에서 정보를 검색하기 위한 목적입니다.
- 쿼리 재작성: 필요에 따라 하위 쿼리를 재작성하여 검색 범위를 조정하거나 더욱 정확한 결과를 얻을 수 있습니다.
- 벡터 저장소 검색: 각 하위 쿼리가 벡터로 변환되어 벡터 저장소에서 가장 유사한 벡터를 가진 상위 k개의 청크를 검색합니다.
- 결과 통합 및 응답 생성: 각 하위 쿼리에서 얻은 결과들을 종합하여 최종적인 답변을 생성합니다. LLM은 다양한 관점에서 얻은 정보를 종합하여 사용자의 질문에 대한 답변을 생성합니다.
Hybrid Search (Fusion Rank)
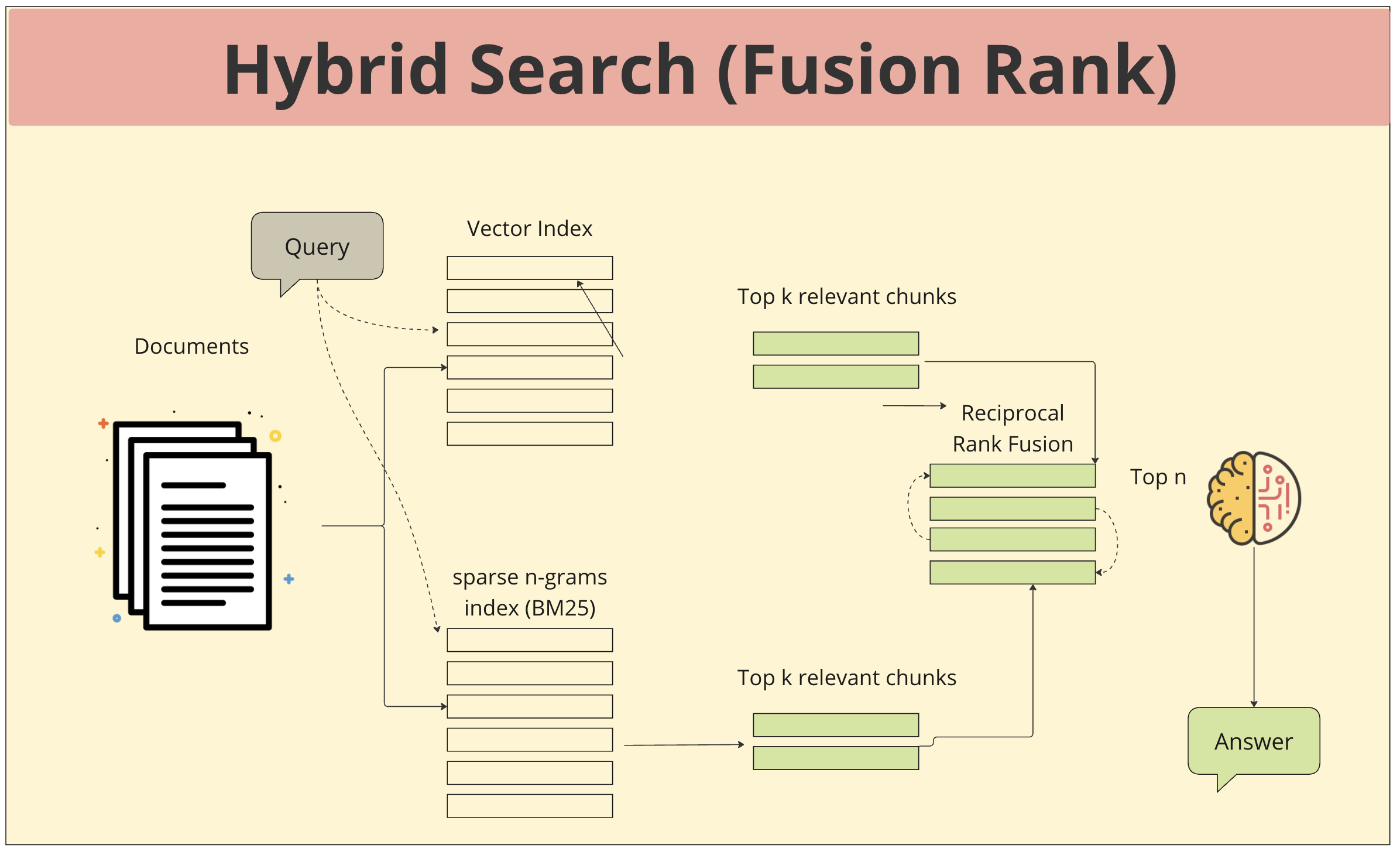
- 쿼리 입력: 사용자가 질문이나 요청을 입력합니다.
- Vector index 검색: 쿼리가 벡터로 변환되어 벡터 인덱스에서 가장 유사한 벡터를 가진 상위 k개의 청크를 검색합니다. Vector index스는 문서의 의미를 수치적으로 표현한 벡터를 저장하는 공간으로, 의미 기반의 유사도를 측정하는 데 효과적입니다.
- sparse n-gram 인덱스 검색: 쿼리의 단어 조합(n-gram)을 기반으로 sparse n-gram 인덱스에서 상위 k개의 청크를 검색합니다. sparse n-gram 인덱스는 문서 내 단어들의 순서와 빈도를 고려하여 검색을 수행하며, 정확한 단어 매칭에 강점이 있습니다.
- 결과 Fusion: 두 가지 검색 결과를 Reciprocal Rank Fusion 기법을 통해 하나의 순위 목록으로 합칩니다. 이는 각 검색 결과의 순위를 고려하여 최종적인 순위를 결정하는 방식입니다.
- 응답 생성: 4번의 결과로 계산된 상위 n개의 청크를 기반으로 최종적인 답변을 생성합니다. LLM은 다양한 관점에서 얻은 정보를 종합하여 사용자의 질문에 대한 답변을 생성합니다.
Query Routing
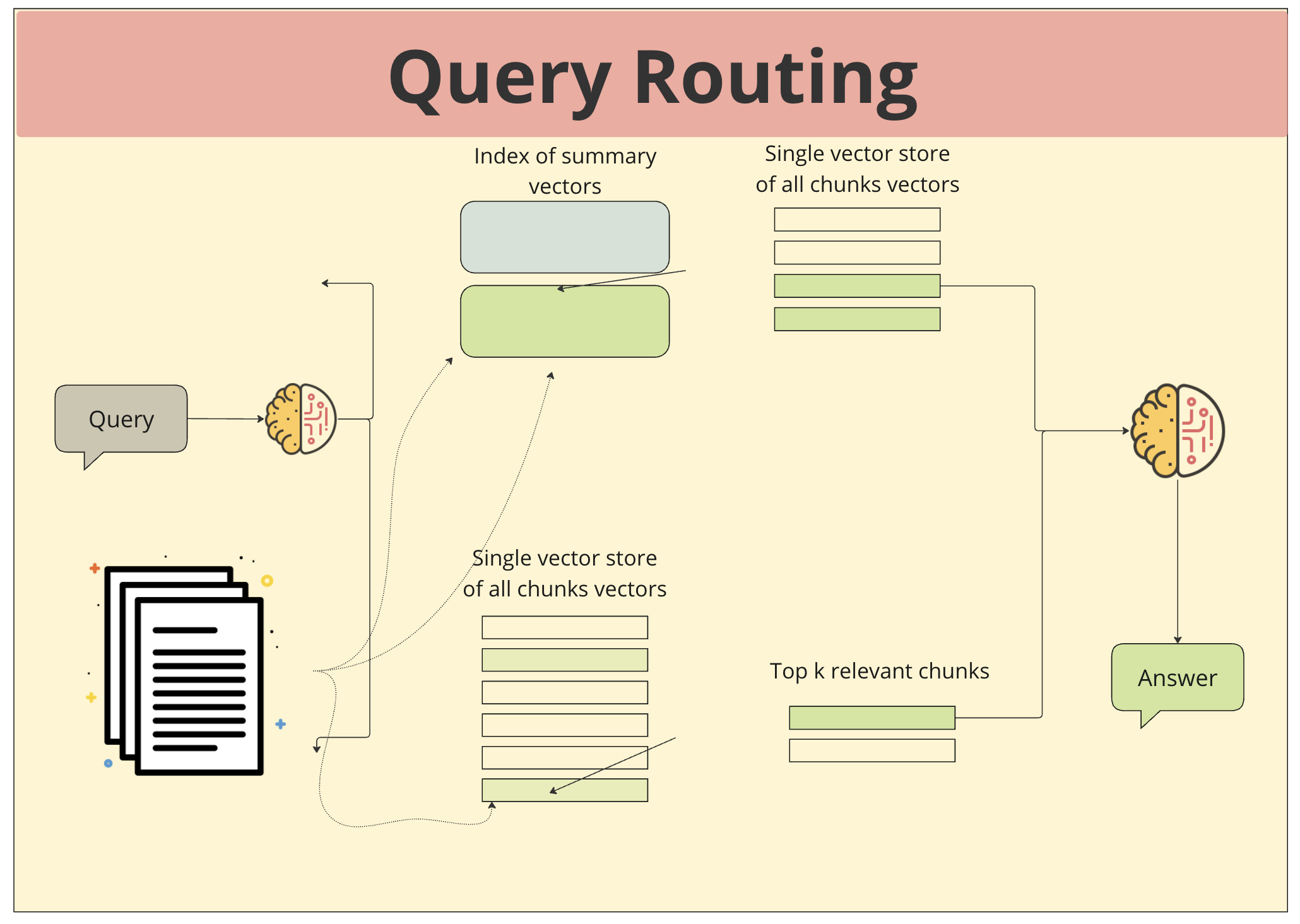
- 쿼리 입력: 사용자가 질문이나 요청을 입력합니다.
- 쿼리 라우팅: 입력된 쿼리가 어떤 벡터 저장소에서 검색해야 할지 결정됩니다. 이 과정에서 쿼리의 특징이나 목적에 따라 다른 벡터 저장소가 선택될 수 있습니다.
- 벡터 저장소 검색: 선택된 벡터 저장소에서 쿼리와 가장 유사한 벡터를 가진 상위 k개의 청크를 검색합니다.
- 결과 통합 및 응답 생성: 각 벡터 저장소에서 얻은 결과들을 종합하여 최종적인 답변을 생성합니다. LLM은 다양한 관점에서 얻은 정보를 종합하여 사용자의 질문에 대한 답변을 생성합니다.
Sentence Window Retrieval
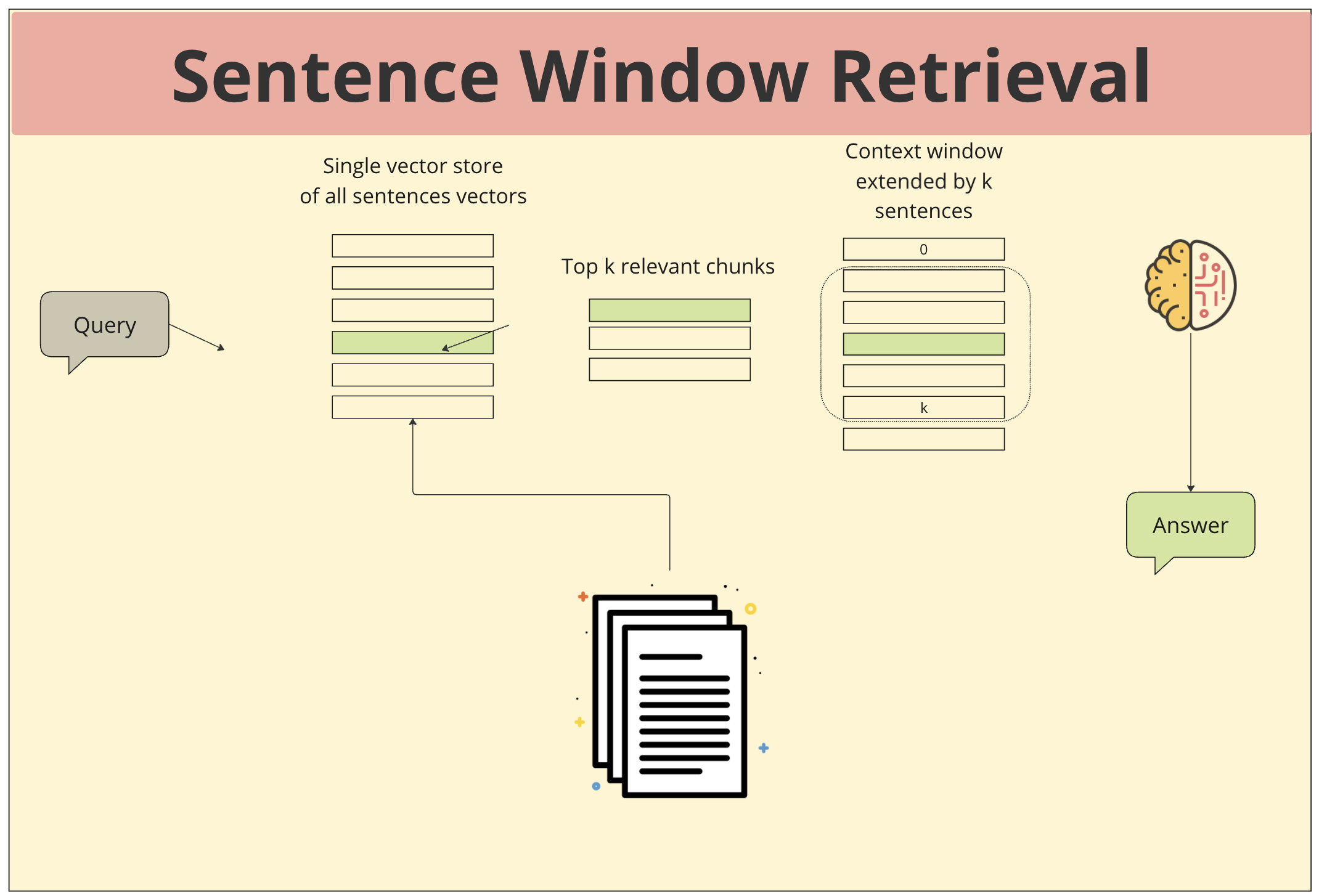
- 문장 단위 벡터화: 모든 문서를 문장 단위로 분리하고, 각 문장을 의미를 나타내는 벡터로 변환합니다.
- 벡터 저장: 변환된 문장 벡터들을 하나의 저장소에 모아둡니다.
- 쿼리 입력: 사용자가 질문을 입력하면, 이 역시 벡터로 변환됩니다.
- 유사도 검색: 입력된 쿼리 벡터와 저장된 문장 벡터들 간의 유사도를 측정하여 가장 유사한 상위 k개의 문장을 찾습니다.
- 문맥 윈도우 확장: 찾은 상위 k개의 문장뿐만 아니라, 그 주변의 k개 문장을 추가하여 더 넓은 문맥을 확보합니다. 이렇게 확장된 문장 집합을 Sentence Window라고 합니다.
- 응답 생성: 확보된 문맥 윈도우를 바탕으로 답변을 생성합니다. LLM은 문맥 윈도우 내의 정보를 종합하여 사용자의 질문에 대한 적절한 답변을 생성합니다.
Hierarchical Index Retrieval
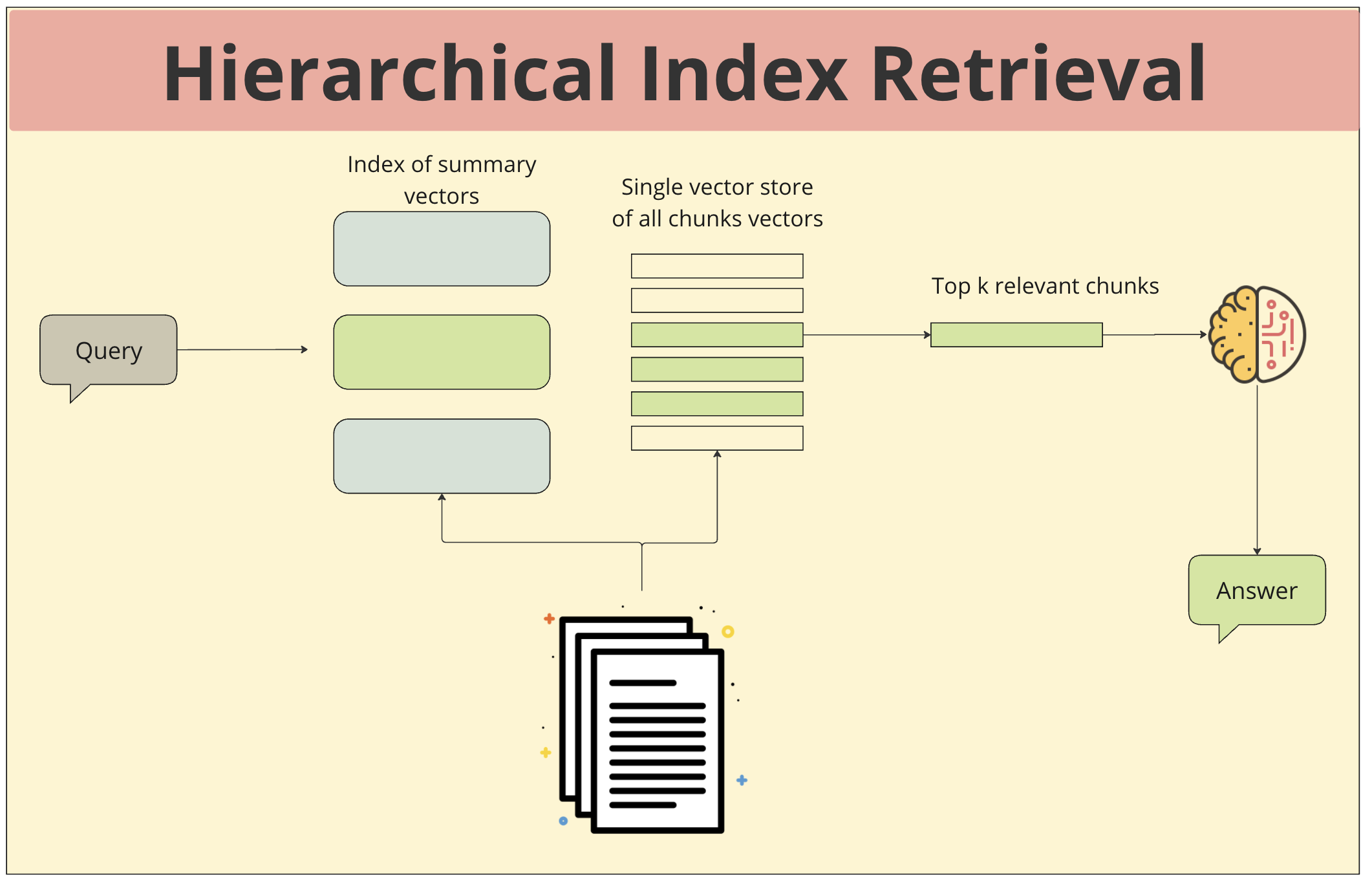
- 쿼리 입력: 사용자가 질문이나 요청을 입력합니다.
- 요약 벡터 인덱스 검색: 먼저 쿼리를 summary vectors index에서 검색합니다. summary vector는 문서 전체의 주요 내용을 담고 있기 때문에, 쿼리와의 전체적인 일치도를 빠르게 확인할 수 있습니다.
- 전체 청크 벡터 인덱스 검색: summary vector 검색을 통해 얻은 후보 문서들을 대상으로, 더 상세한 정보를 담고 있는 전체 청크 벡터 인덱스에서 정확한 답변을 찾기 위한 세밀한 검색을 진행합니다.
- 응답 생성: 두 단계의 검색을 통해 얻은 최종적으로 선택된 청크들을 기반으로 답변을 생성합니다.
HyDE Retrieval
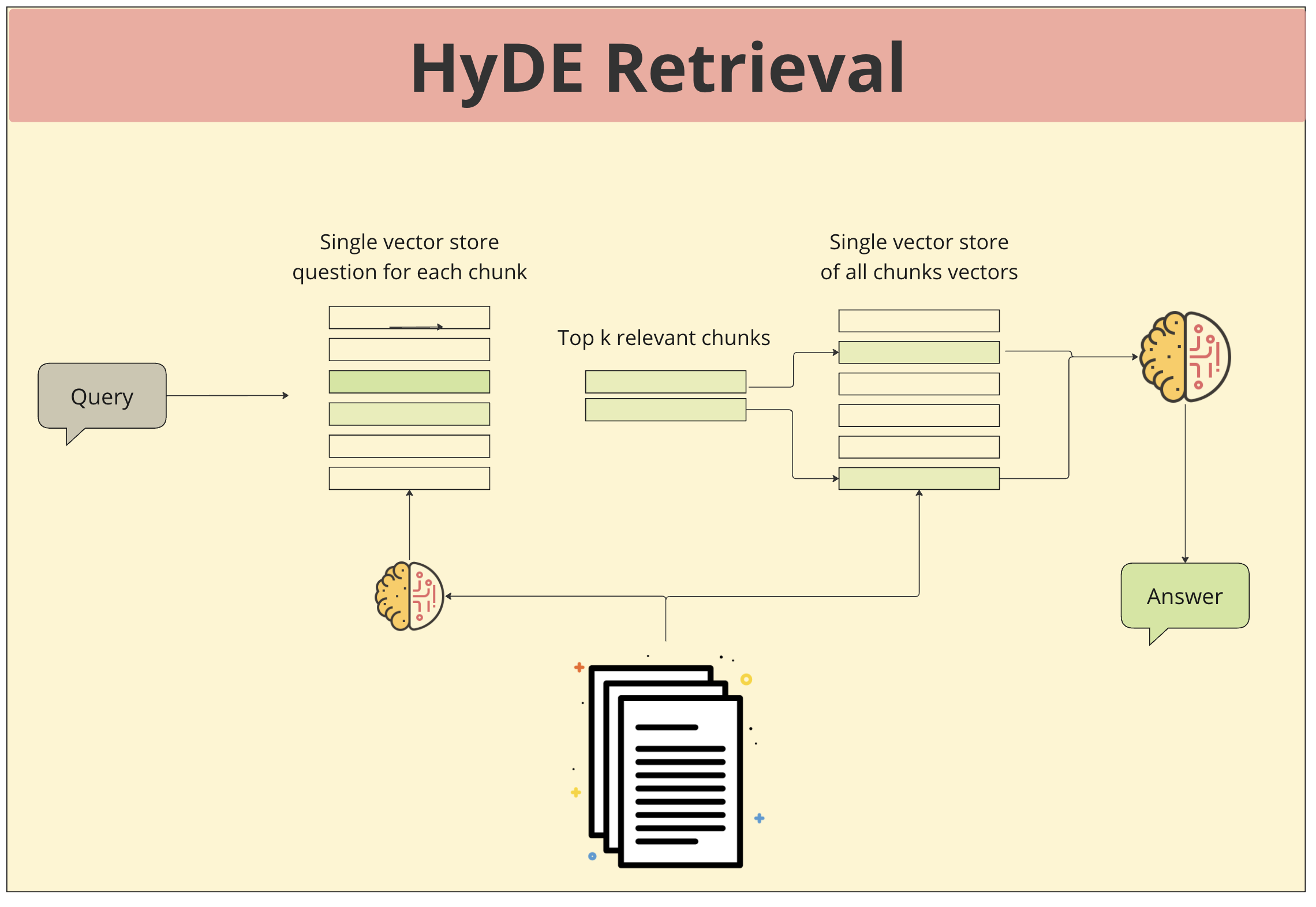
- 문서 분할: 문서는 작은 단위의 청크로 나뉩니다.
- 질문 생성: 각 청크에 대한 질문이 생성됩니다. 이 질문은 해당 청크의 주제나 내용을 파악하기 위한 것이며, 종종 "이 청크에서 가장 중요한 것은 무엇인가?", "이 청크는 무엇에 대한 내용인가?"와 같은 형태로 나타납니다.
- 벡터화: 생성된 질문과 각 청크는 모두 벡터로 변환됩니다.
- 유사도 측정: 입력된 쿼리와 각 청크에 대한 질문 벡터 간의 유사도를 측정합니다.
- 상위 k개 선택: 유사도가 높은 상위 k개의 청크를 선택합니다.
- 응답 생성: 선택된 청크들을 기반으로 대규모 언어 모델(LLM)이 최종적인 답변을 생성합니다.
Agents + Query Routing
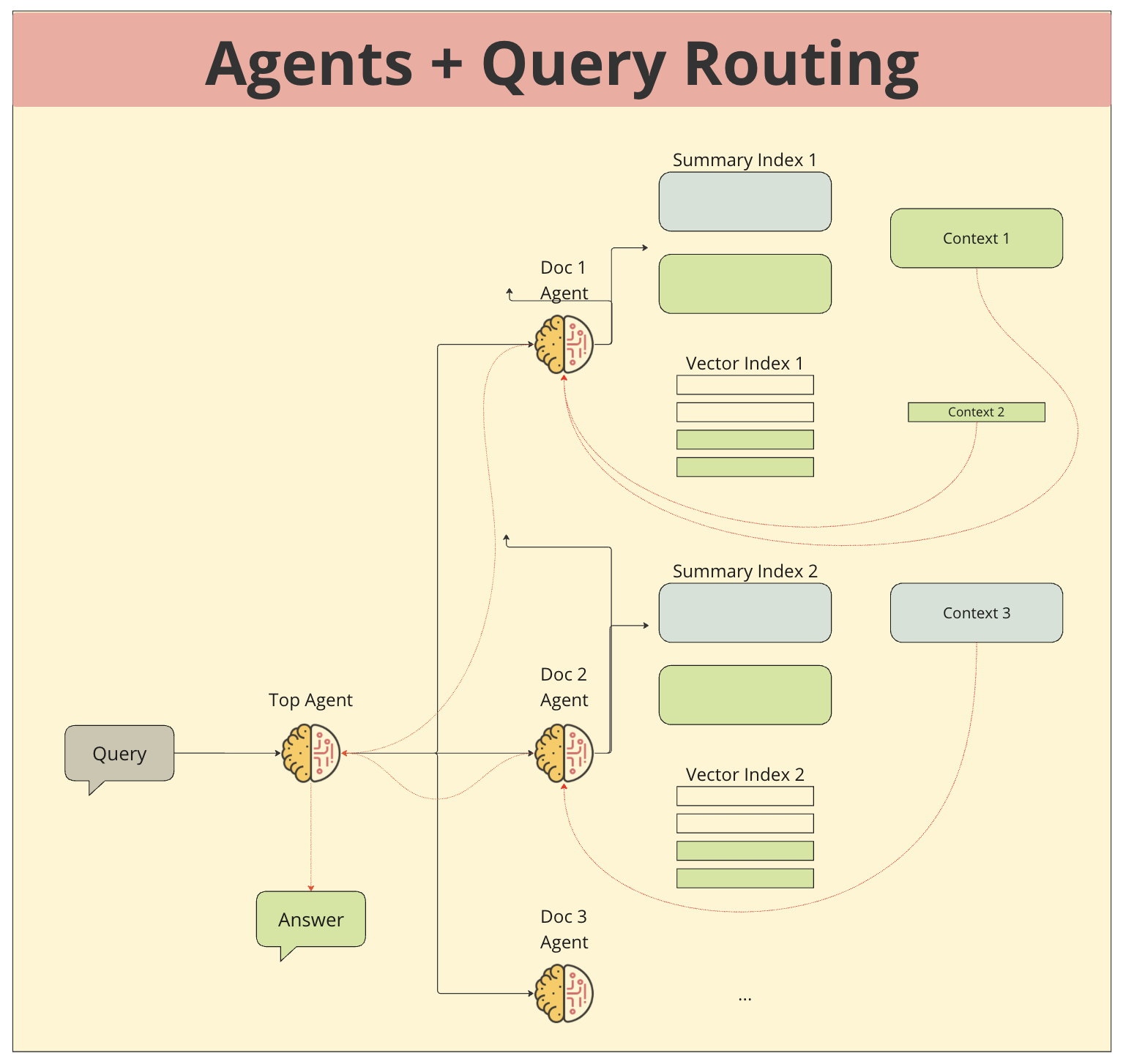
- 문서 및 에이전트: 각 문서에 특정한 Agent가 할당됩니다. 이 Agent는 해당 문서의 특성을 가장 잘 이해하고 있으며, 쿼리와의 관련성을 판단하는 역할을 합니다.
- 요약 및 벡터 인덱스: 각 문서는 요약 정보와 상세 정보를 담은 벡터 인덱스를 가지고 있습니다. 요약 인덱스는 문서의 전체적인 주제를 나타내고, 벡터 인덱스는 문서 내의 세부 정보를 나타냅니다.
- 쿼리 입력: 사용자가 질문을 입력하면, 이 쿼리는 모든 에이전트에게 전달됩니다.
- 에이전트 평가: 각 에이전트는 자신이 담당하는 문서와 쿼리의 관련성을 평가하고, 가장 관련성이 높은 문서를 선정합니다.
- 쿼리 라우팅: 가장 관련성이 높은 문서를 선정한 에이전트가 해당 문서의 벡터 인덱스를 검색하여 쿼리와 가장 유사한 부분을 찾습니다.
- 응답 생성: 찾은 정보를 바탕으로 최종적인 답변을 생성합니다.
RAG Generation
Information Compression
Information Compression은 검색된 정보를 효과적으로 처리하고 활용하기 위한 중요한 후처리 기법입니다. 이 기법의 주요 목적은 검색된 방대한 양의 정보를 압축하여 언어 모델의 컨텍스트 윈도우 제한을 해결하고, 중요한 정보를 보존하면서 불필요한 내용을 제거하는 것입니다.
Generator Fine Tuning
Generator Fine-Tuning은 RAG의 생성 모델(Generator) 부분을 특정 도메인이나 작업에 맞게 최적화하는 과정입니다.
Generator Fine-Tuning을 통해 LLM의 특정 도메인에 대한 이해도 증가와 검색된 정보를 더 효과적으로 활용하여 응답을 생성 할 수 있도록 합니다.
주요 방법론으로는 Domain Adaptation, Task Spectific training, Retrieval Augmented Fine-tuning이 있습니다.
- 도메인 적응(Domain Adaptation): 특정 분야의 데이터셋을 사용하여 생성 모델을 재훈련합니다. 이를 통해 모델은 해당 도메인의 용어와 맥락을 더 잘 이해하게 됩니다.
- Task Spectific training : 특정 유형의 질문-답변 쌍을 사용하여 모델을 미세 조정합니다. 이는 모델이 특정 작업에 더 적합한 응답을 생성하도록 돕습니다.
- RAFT(Retrieval Augmented Fine-Tuning): RAG를 사용하여 관련 정보를 검색한 후, 그 데이터로 모델을 미세 조정하는 방식입니다. 이는 도메인 특화 성능과 RAG 성능을 동시에 향상시킵니다.
Result Re-Rank
Result Re-Rank는 검색된 문서들의 순위를 재조정하여 가장 관련성 높은 정보를 상위에 배치하는 방법입니다.
Language model을 활용하여 검색 결과로 얻은 상위 k개 문서에 대해 질문과의 관련성을 재평가하고 순위를 조정할 수 있습니다.
복잡한 작업 없이도 검색 및 생성 정확도를 향상시킬 수 있어, RAG 시스템 최적화의 첫 단계로 고려해볼 만한 방법입니다.
Adapter Methods
Adapter Methods는 전체 모델을 fine-tuning하는 대신 작은 모듈을 추가하여 모델을 효율적으로 조정합니다.
주요 접근 방식은 다음과 같습니다.
- PRCA (Prompt Relevant Context Analysis): 이 방법은 정보 추출기를 학습시켜 실제 문맥과 압축된 문맥 사이의 차이를 최소화합니다. 입력 텍스트로부터 압축된 문맥을 생성하여 중요 정보를 보존합니다.
- RECOMP: 추출적(extractive) 및 생성적(generative) 압축기를 사용합니다. 이 방법은 관련 문장을 선택하거나 문서 정보를 종합하여 다중 문서 쿼리 집중 요약을 생성합니다.
- PKG (Prompt Knowledge Grounding): 이 방법은 외부 지식을 프롬프트에 통합하여 모델의 성능을 향상시킵니다.
RAG Evaluation
RAG 평가 주요 관점

Noise Robustness
Noise Robustness은 RAG 시스템이 검색된 정보에 노이즈가 있을 때도 안정적으로 작동하는 능력을 평가합니다.
- 주요 특징
- 다양한 유형의 노이즈(예: 관련 없는 정보, 부분적으로 관련된 정보, 오류 정보)에 대한 모델의 반응을 테스트합니다.
- RAAT(Retrieval-augmented Adaptive Adversarial Training)와 같은 기법을 사용하여 노이즈 견고성을 향상시킬 수 있습니다
- 평가 방법
- 노이즈가 있는 검색 결과를 의도적으로 주입하고 모델의 성능 변화를 측정합니다.
- F1 점수와 EM(Exact Match) 점수를 사용하여 다양한 노이즈 조건에서의 성능을 평가합니다.
Negative Rejection
Negative Rejection 는 모델이 답변할 수 없는 질문을 식별하고 적절히 거부하는 능력을 평가합니다.
- 주요 특징
- 모델이 "모르겠습니다" 또는 "이 질문에 답할 수 없습니다"와 같은 응답을 생성할 수 있어야 합니다.
- 잘못된 정보를 제공하는 것보다 모르는 것을 인정하는 것이 중요합니다.
- 평가 방법
- 답변할 수 없는 질문들을 포함한 테스트 세트를 사용합니다.
- 거부율(rejection rate)을 측정하여 모델이 얼마나 잘 부정적인 응답을 생성하는지 평가합니다.
Information Integration
Information Integration 은 RAG 시스템이 여러 소스에서 검색된 정보를 효과적으로 결합하여 일관되고 정확한 응답을 생성하는 능력을 평가합니다.
- 주요 특징
- 다양한 출처의 정보를 종합하여 포괄적인 답변을 생성해야 합니다.
- 정보 간의 모순이 있을 경우 이를 해결하고 일관된 응답을 제공해야 합니다.
- 평가 방법
- 여러 소스의 정보가 필요한 복잡한 질문을 사용하여 테스트합니다.
- 응답의 일관성, 정확성, 완전성을 평가합니다.
Counterfactual Robustness
Counterfactual Robustness 은 모델이 사실과 다른 정보나 가정에 직면했을 때의 성능을 평가합니다.
- 주요 특징
- 모델이 잘못된 정보나 가정을 식별하고 이에 적절히 대응할 수 있어야 합니다.
- 사실과 다른 정보를 그대로 수용하지 않고 비판적으로 평가해야 합니다.
- 평가 방법
- 의도적으로 잘못된 정보나 가정을 포함한 질문을 사용합니다.
- 모델이 이러한 오류를 식별하고 정정하는 능력을 평가합니다.
정량 지표를 측정할 수 있는 요소

Context Relevance
Context Relevance는 검색된 문서나 정보가 주어진 질문과 얼마나 관련이 있는지를 평가합니다.
- 주요 특징
- 검색 컴포넌트의 성능을 평가합니다.
- 대규모 데이터셋에서 관련 문서를 얼마나 정확하게 검색했는지 측정합니다.
- 평가 방법
- Precision (정밀도)
- Recall (재현율)
- Mean Reciprocal Rank (MRR)
- Mean Average Precision (MAP)
이러한 메트릭들은 검색된 문서의 관련성과 순위를 종합적으로 평가합니다.
Answer Relevance
Answer Relevance는 생성된 답변이 사용자의 질문에 얼마나 잘 부합하는지를 평가합니다.
- 주요 특징
- 생성된 응답이 질문에 얼마나 적절하게 답변하는지 측정합니다.
- 응답의 유용성과 정보 제공 능력을 평가합니다.
- 평가 방법
- BLEU, ROUGE, METEOR 같은 텍스트 유사도 메트릭
- 임베딩 기반 평가
이 평가는 응답의 품질과 질문에 대한 적절성을 종합적으로 측정합니다.
Faithfulness
Faithfulness는 생성된 응답이 검색된 문서의 사실에 얼마나 충실한지를 평가합니다.
- 주요 특징
- 생성된 응답이 검색된 문서의 정보와 일치하는지 확인합니다.
- 허위 정보나 환각(hallucination)을 방지하는 능력을 평가합니다.
- 평가 방법
- 인간 전문가의 평가
- 자동화된 사실 확인 도구
- 일관성 검사
- LLM을 활용한 평가 (예: GPT-4를 판단자로 사용)
Faithfulness는 RAG 시스템이 정확하고 신뢰할 수 있는 정보를 제공하는지 확인하는 데 중요한 역할을 합니다.
RAG 시스템 평가 프레임워크
유명한 평가 프레임워크로는 RAGAS, ARES, TruLens등이 있습니다.
RAGAS
RAGAS는 오픈소스 RAG 평가 프레임워크로, 참조 데이터 없이도 평가가 가능한 것이 특징입니다.
- 주요 특징
- Average Precision (AP)와 Faithfulness 같은 커스텀 메트릭을 사용합니다.
- 생성된 콘텐츠가 제공된 컨텍스트와 얼마나 잘 일치하는지 평가합니다.
- 초기 평가나 참조 데이터가 부족한 상황에 적합합니다.
ARES
ARES는 합성 데이터와 LLM 판단자를 활용하는 오픈소스 프레임워크입니다.
- 주요 특징
- Mean Reciprocal Rank (MRR)과 Normalized Discounted Cumulative Gain (NDCG)를 강조합니다.
- 지속적인 훈련과 업데이트가 필요한 동적 환경에 이상적입니다.
- 시스템의 관련성과 정확성을 유지하는 데 중점을 둡니다.
TruLens
TruLens는 RAG 시스템의 성능을 모니터링하고 개선하기 위한 오픈소스 도구입니다.
- 주요 특징
- 응답의 정확성, 관련성, 충실도를 평가합니다.
- 검색 품질과 LLM 응답 품질을 별도로 분석합니다.
- 실시간 모니터링과 디버깅 기능을 제공합니다.
Reference
- https://www.linkedin.com/feed/update/urn:li:activity:7243952578013614081
- Recursive Chunking Strategy
- Mastering RAG: Advanced Chunking Techniques for LLM Applications
- Hierarchy of Ideas or Chunking in NLP
- RAG Evaluation: Don’t let customers tell you first
- Evaluating Quality of Answers for Retrieval-Augmented Generation: A Strong LLM Is All You Need
- Ragas docs
- 한국어 Reranker를 활용한 검색 증강 생성 성능 올리기
- A Cheat Sheet and Some Recipes For Building Advanced RAG
- Retrieval Augmented Generation for LLMs
'딥러닝 > LLM' 카테고리의 다른 글
| 효율적인 LLM 서빙: vLLM과 Triton Inference Server 활용하기 (0) | 2024.12.07 |
|---|---|
| LLM 효율성을 높이는 양자화 기법 탐구 및 성능 분석 (0) | 2024.11.12 |
| RAG(Relevance-Augmented Generation): LLM의 한계를 넘는 새로운 접근 (0) | 2024.10.09 |
| LLM을 활용한 지식 증류: sLLM 성능 최적화 실험 (5) | 2024.09.01 |
| LLM의 양자화가 한국어에 미치는 영향 (0) | 2024.08.19 |