
들어가며..
OpenAI가 지난 8월, GPT-2 이후 처음으로 오픈 웨이트 모델인 gpt-oss-120b와 gpt-oss-20b를 공개했습니다.
두 모델은 OpenAI의 최신 모델들을(o3 등) 참고해 개발되었으며, 다양한 학습 기법과 강화 학습을 바탕으로 훈련된 모델입니다.
gpt-oss-120b 모델은 단일 80GB GPU에서 작동 가능하며, 핵심 추론 벤치마크에서 OpenAI o4-mini와 거의 동등한 결과를 달성하였습니다.
마찬가지로 gpt-oss-20b 모델은 벤치마크에서 OpenAI o3‑mini와 비슷한 결과를 달성하였으며, 단 16GB vRam을 가진 에지 디바이스에서도 실행할 수 있어, 개인이 인프라에 대한 고민 없이 사용하기에 적합한 모델입니다.
이번 글에서는 GPT-OSS의 아키텍쳐, 특징, 주요 벤치마크 결과등에 대해 알아보겠습니다.
GPT-OSS 아키텍쳐
<그림 1>을 보면 알겠지만, 사실 다른 LLM과 구별되는 특징은 보이지 않습니다.
최근 LLM 개발팀들은 대체로 동일한 기본 아키텍처를 사용하고, 약간의 tweaks(조정)을 적용하는 형태로 모델을 개발하기 때문입니다.

그 이유는 여러 가지가 있겠지만, 가장 큰 이유는 아직까지 트랜스포머 아키텍처를 확실히 능가하는 대안이 뚜렷하게 등장하지 않았기 때문일 것입니다.
최근 구글이 소개한 text diffusion 모델이나 state space model 등도 벤치마크에서는 앞서는 결과를 보이지만, 실제 활용 사례를 찾기는 여전히 쉽지 않습니다.
아무튼 그럼에도 아키텍처상 여러 가지 살펴볼만한 내용들이 있습니다. 이 부분은 뒤에서 조금 더 자세히 다뤄보도록 하겠습니다.
GPT-2 → GPT Oss
gpt-oss와 최신 아키텍처를 비교하기 전에, 이전 openai가 공개했던 모델인 GPT-2와 비교해 보며 얼마나 변화가 있었는지 확인해 보겠습니다.
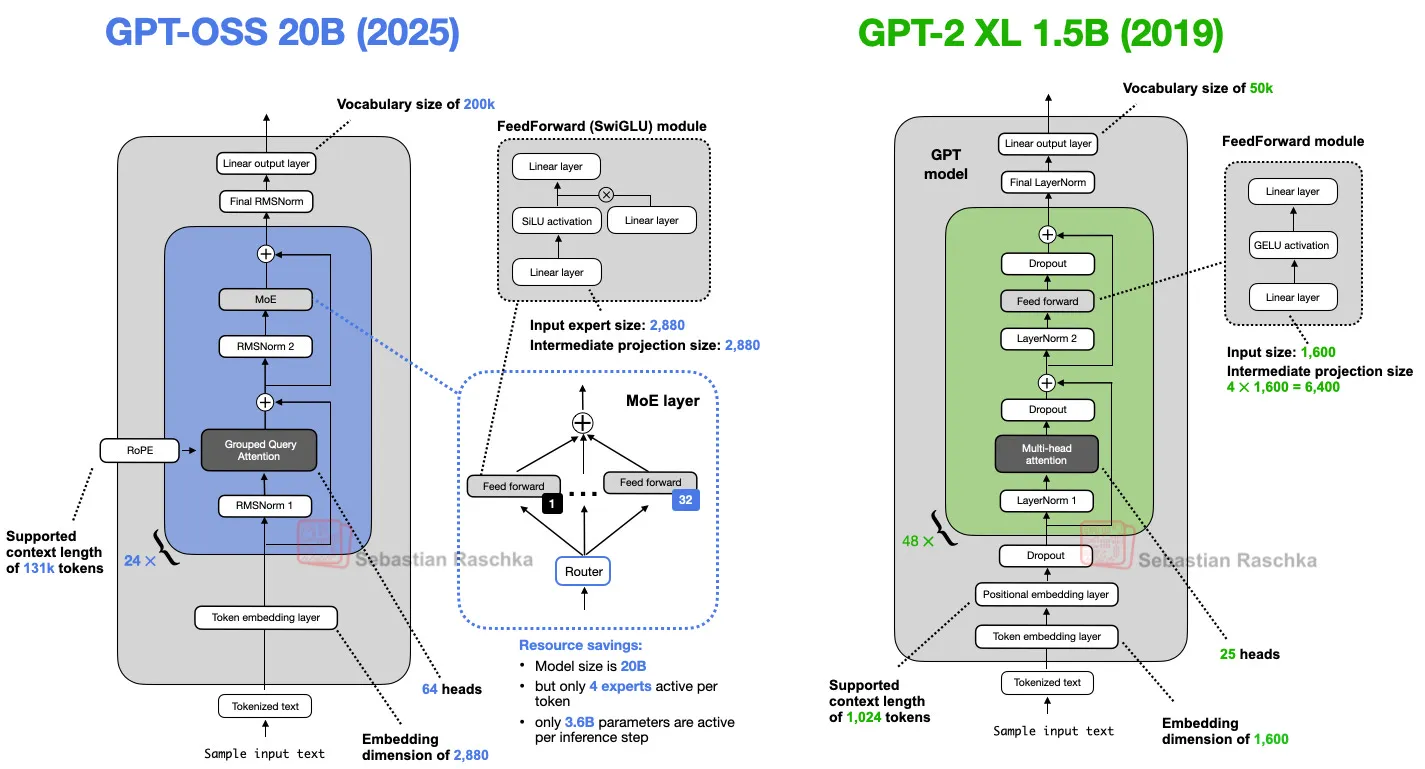
gpt-oss와 GPT-2 모두 Attention Is All You Need(2017)에서 제안된 트랜스포머 기반의 디코더 전용 모델이지만, 시간이 흐르면서 모델의 아키텍처는 수많은 세부 요소가 발전해 왔습니다.
이러한 변화들은 다른 LLM들에서도 공통적으로 나타나는 변화들이고, gpt-oss만의 특징은 아닙니다.
2.1 Dropout 제거
Dropout(2012)은 훈련 중 일부 활성값이나 어텐션 스코어를 무작위로 0으로 만들어 과적합을 방지하는 고전적인 기법입니다.
하지만 최신 LLM에서는 거의 쓰이지 않으며, GPT-2 이후 대부분의 모델은 이를 제거했습니다.

아마 GPT-2에 Dropout이 포함된 이유는 원래 트랜스포머 아키텍처에 원래 포함되어 있어, 그대로 아키텍처를 가져왔기 때문일 것입니다.
Dropout이 처음 등장했을 때는 수백 에폭 반복 학습이 일반적이었으며, 그 환경에서 과적합 방지에 효과적이었습니다.
그러나 최근의 LLM을 학습할 때는 방대한 데이터셋을 단 한 번의 에폭으로 학습하는 경우가 많고, 이러한 경우 Dropout이 성능 향상에는 도움이 되지 않는다는 점이 발견되었습니다.
정리하자면, LLM은 학습 시 각 데이터를 한 번만 보기 때문에 과적합 위험이 낮기에, Dropout의 필요성이 흐려지게 되었습니다.
2.2 Rope : 상대적 Positional Embedidng
트랜스포머 기반 LLM에서는 기본적으로 어텐션은 입력 토큰에 순서를 부여하지 않고 병렬로 입력하여 학습하기 때문에 순서 정보가 필요합니다.
초기 GPT 아키텍처에서는 이를 해결하기 위해 Absolute Positional Embedidng을 사용했습니다. 즉, 각 위치마다 학습 가능한 벡터를 만들고, 이를 토큰 임베딩에 더하는 방식을 적용하였습니다.

다양한 길이의 입력에 대응하도록 학습 데이터셋을 구성하면 모델이 추론 시에도 비교적 안정적으로 작동하기 때문에, 이러한 방식은 짧은 길이의 입력에 대해서는 효과적일 수 있습니다.
그러나 최근에는 입력 길이가 100k 토큰에 이르는 경우도 흔해지면서, 이런 모든 상황을 포괄하는 데이터셋을 구축해 학습하는 것은 사실상 불가능해졌습니다.
그래서 RoPE(Rotrary Position Embedidng)은 각 토큰의 절대적인 위치가 아니라 상대적인 위치를 계산해 토큰 임베딩에 반영하여 이러한 문제를 해결하였습니다.

RoPE 논문 자체는 2021년에 소개되었지만, 2023년 Llama가 이를 채택하면서 본격적으로 업계 표준으로 자리 잡았고, 지금은 대부분의 LLM이 해당 방식을 사용하고 있습니다.
2.3 Gelu를 대체한 Swish/SwiGLU
GPT-2는 활성화 함수로 GLUE를 사용했지만 gpt-oss는 왜 Siwsh를 사용합니다.
Siwsh가 Gelu 보다 더 좋은 활성화 함수라는 분석은 여러 가지가 있지만 가자 직관적인 이유는 단순히 계산 비용이 약간 더 낮기 때문에 속도 면에서 유리합니다.
딥러닝 초창기에는 ReLU부터 시작하 다양한 활성화 함수들이 사용되었습니다. 그러면서 이때까지 살아남은 게 GELU와 Siwsh이며 둘 다 ReLU보다 조금 더 부드러운 곡선을 가진 형태를 보입니다.

2.4 Mixture-of-Experts
Mixture-of-Experts(MoE) 방식은 단일 FeedForword(이하 FF) 모듈을 여러 개의 FF 모듈로 대체하고, 각 토큰을 처리할 때 여러 개의 FF 모듈 중 일부분만 선택적으로 사용하는 방식입니다.

단일 FF 모듈을 여러 개의 FF로 바꾸게 되면 전체 parameter 수가 크게 증가합니다.
하지만 핵심은 모든 FF 모듈(이하 expert)을 매번 사용하는 것이 아니라, 라우터(router)가 입력되는 토큰마다 몇 개의 expert만 사용한다는 것입니다.
요즘 모델 이름 뒤에 파라미터 수(B) 뿐만 아니라 A(Active)가 붙은 경우가 자주 보이는데, 이러한 모델들은 모두 MoE 아키텍처를 가지는 모델입니다.
예를 들어 Qwen-3-30B3A 모델은 전체 파라미터수는 30B이지만 추론 시 사용하는(활성화되는) 파라미터는 3B입니다. 그래서 해당 모델의 추론 속도는 3B 모델과 동일하거나 조금 느린 수준입니다.
모든 expert를 쓰지 않기 때문에 sparse(희소) 모듈이라고 하고, 반대로 항상 모든 파라미터를 사용하는 기존 방식은 dense 모듈이라고 표현합니다.
MoE 아키텍처는 전체 파라미터 수는 커지지만, 실제 계산은 일부 expert만 수행하므로 추론 비용은 크게 늘지 않습니다.
그리고 더 많은 파라미터는 모델 용량(capacity)을 증가시켜 더 많은 지식을 학습할 수 있게 합니다.
2.5 Multi Head Attention → Grouped Query Attention(GQA)
Grouped Query Attention(GQA)은 최근 몇 년 동안 Multi-Head Attention(MHA)의 더 효율적인 대안으로 널리 쓰이기 시작했습니다.
MHA에서는 각 head가 자신의 key와 value를 가지지만, GQA는 여러 head가 key·value를 공유하도록 그룹화해 메모리 사용을 줄입니다.
예를 들어 그림 8처럼 key–value 그룹이 2개, attention head가 4개라면
- head 1, 2는 동일한 key·value를 공유
- head 3, 4는 또 다른 key·value를 공유

이렇게 하면 key·value 계산량이 줄어 메모리를 덜 사용하고, 효율성은 높아지며, 실험 결과 모델링 성능은 거의 동일하다는 것이 밝혀졌습니다.
GQA의 핵심은 간단합니다.
- key·value head 수를 줄여서
- 파라미터 수 감소 + KV 캐시 접근 비용 감소
즉, 추론 속도가 빨라지고 메모리 효율이 좋아집니다.
여러 논문(Llama 2, GQA 원 논문 등)에서도 GQA는 MHA와 거의 동등한 성능을 보인다고 설명합니다.
2.6 Sliding Window Attention
슬라이딩 윈도우 어텐션은 LongFormer(2020)에서 처음 제안되었고, 이후 Mistral에서 적용되며 확산되었습니다.

흥미로운 점은 gpt-oss는 2개 레이어 중 1개 레이어에만 슬라이딩 윈도우를 적용한다.
구체적으로 gpt-oss는 다음과 같이 동작합니다.
첫 번째 layer: 전체 문맥에 GQA 적용 -> 그다음 layer: 128 토큰 윈도우에만 제한된 로컬 어텐션 사용 -> 이후 동일한 패턴 반복
Gemma 2는 GPT-OSS와 동일한 1:1 비율을 사용했고, Gemma 3는 더 극단적으로 5개의 로컬 어텐션 레이어마다 1개의 전체 문맨에 GQA를 적용합니다.
Gemma의 실험에서는 sliding-window 사용은 성능 하락이 거의 없다고 설명했습니다.
참고로 Gemma2는 window 크기가 4096, Gemm3는 1024이며, 그에 반해 gpt-oss의 window는 단 128 토큰으로 매우 작은 편입니다.
LayerNorm을 대체한 RMSNorm
마지막으로 변경된 점은 LayerNorm(2016)을 RMSNorm(2019)으로 대체한 것이다.
이는 최근 LLM 전반에서 보이는 명확한 추세입니다. Swish와 SwiGLU로 교체한 것처럼, RMSNorm도 작지만 효율적인 최적화에 속합니다.
두 기법 모두 활성값의 스케일을 안정화하는 역할을 합니다. 둘 다 학습 안정성을 크게 높이지만, RMSNorm이 계산 비용이 더 낮습니다.

gpt-oss와 최근 아키텍처(Qwen3) 비교
앞에서 GPT-2 → GPT OSS로 이어지는 발전 과정을 살펴봤으니, 이제 좀 더 최근에 나온 아키텍처인 Qwen3와 비교해 보겠습니다.
Qwen3는 2025년 5월에 공개되었으며, GPT OSS보다 세 달 먼저 공개되었습니다.
<그림 11>은 gpt-oss-20b와 비슷한 크기의 Qwen3 모델을 비교한 그림입니다.

보시다시피 gpt-oss 20B와 Qwen3 30B-A3B는 아키텍처 구성 요소가 매우 비슷합니다. 주요 차이점은 gpt-oss는 슬라이딩 윈도우 어텐션을 사용하지만 Qwen3는 사용하지 않는다는 점입니다.
그래도 몇 가지 차이점이 있기에, 알아보도록 하겠습니다.
3.1 너비(Width) vs. 깊이(Depth)
두 모델의 아키텍처를 자세히 보면 Qwne3는 더 깊은 아키텍처이고, gpt-oss는 더 넓은 아키텍처입니다.

| 항목 | Qwen3 | gpt-oss |
|---|---|---|
| 모델 성향 | 깊고 얇은 구조 | 넓고 얕은 구조 |
| 트래스포머 블록 수 | 48개 (더 깊음) | 24개 (더 얕음) |
| 임베딩 차원 | 2048 (작음) | 2880 (큼) |
| FFN 중간 차원 | 768 | 2880 |
| 어텐션 헤드 수 | 상대적으로 적음 | 약 2배 더 많음 |
| 장점 | 높은 표현력, 더 복잡한 패턴 학습 | 높은 병렬성, 빠른 추론 |
| 단점 | 학습 난이도 ↑ (기울기 문제 등) | 메모리 사용량 ↑ |
파라미터 수가 정해져 있을 때, 일반적으로 더 깊은 모델은 표현력은 크지만, 기울기 폭발·소실 등으로 인해 훈련이 더 어려울 수 있습니다.
반면 더 넓은 모델은 병렬화가 잘 되어 추론 속도(tokens/sec)가 빠르지만 메모리 비용이 증가합니다.
성능 면에서는 동일 파라미터·동일 데이터로 엄밀하게 비교한 연구는 많지 않지만, Gemma 2 논문(Table 9)의 9B 아키텍처 비교 실험에서는 더 넓은 모델이 약간 더 우수했습니다.

3.2 Few Large Experts vs Many Small Experts
<그림 12>에서 보듯 gpt-oss는 Experts 수가 매우 적습니다. 게다가 토큰 당 활성 전문가 수도 Qwen에 비하면 절반 수준입니다. 대신 gpt-oss의 각 Experts는 Qwen3에 비해 훨씬 큽니다.
조금 흥미로운 사실은 최근 연구 흐름은 일반적으로 전문가 수를 더 많이 두고 각 전문가는 더 작게 설계하는 방향이라는 것입니다. 이를 일정한 전체 파라미터 규모 내에서 시각적으로 잘 보여주는 것이 DeepSeekMoE 논문입니다.

참고로 DeepSeek 모델과는 달리 gpt-oss와 Qwen3는 모두 shared experts를 사용하지 않습니다.
gpt-oss에서 experts 수가 적은 이유는 전체 모델 규모가 20B로 비교적 작은 데에 있을 가능성이 큽니다. 왜냐하면 120B 모델에서는 experts 수와 트랜스포머 블록 수를 함께 늘리면서, 그 외 구성은 대부분 동일하게 유지했기 때문입니다.
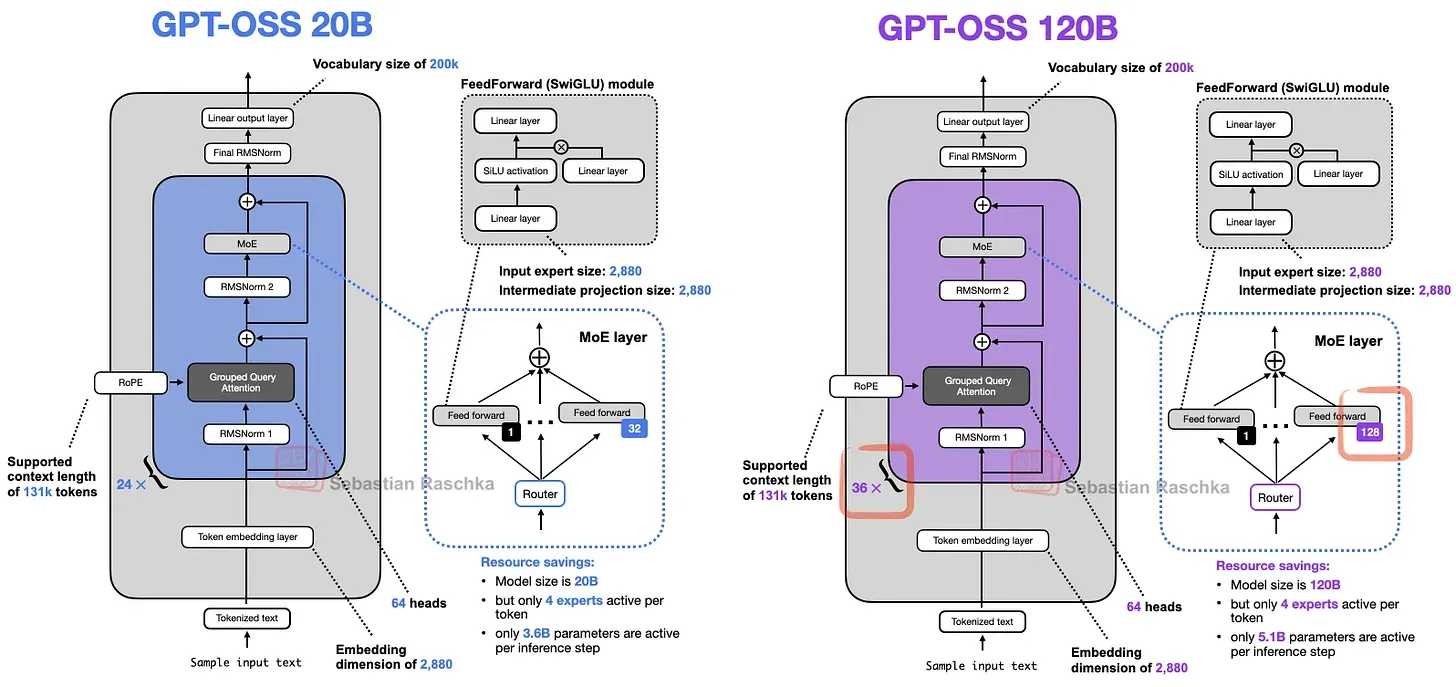
20B와 120B의 구조가 비슷한 이유는, 120B를 기반으로 블록 수와 전문가 수만 축소해 20B를 만들었거나, 120B를 학습한 뒤 일부를 잘라내는 방식으로 축소했기 때문으로 보입니다.
어쨌든 블록 수와 전문가 수만 조정해 스케일링하는 방식은 꽤 이례적입니다. 예를 들어 Qwen3 MoE 계열은 모델 크기에 따라 훨씬 다양한 구성 요소를 보다 비례적으로 조정하는 접근을 취합니다.

4. 몇가지 특이점
앞서 gpt2와의 차이점이나 최신 아키텍처(qwen3)와 비교를 통해 gpt-oss의 특징을 살펴봤습니다.
이제 마지막으로 그 외에 주목할만한 점들에 대해 알아보겠습니다.
4.1 학습 개요
학습 데이터셋의 규모나 알고리즘에 대한 정보는 충분히 공개되지 않았지만, model card report(1)와 announcement post(2)에서 확인되는 핵심 내용은 다음과 같습니다.
- gpt-oss는 최신 사전학습 및 후처리(post-training) 기법을 활용해 학습되었다. (1)
- 전체 학습에는 210만 H100 GPU 시간이 투입되었고, gpt-oss-20b는 이보다 약 10분의 1 수준의 시간이 필요했다. (1)
- 지도학습 기반 학습 단계와 고연산 강화학습(RL) 단계가 포함되었다. (2)
- 영어 중심의 텍스트 전용 데이터셋을 사용했으며, STEM·코딩·일반 지식 비중이 높았다. (2)
4.2 Reasoning Efforts
gpt-oss는 기본적으로 reasoning 모델이지만, 사용자가 추론 강도를 추론 단계(Inference time)에서 직접 조절할 수 있도록 훈련되었습니다.
구체적으로 gpt-oss는 시스템 프롬프트에 다음과 같은 지시를 받을 수 있습니다.
- “Reasoning effort:
low/medium/high”
이 설정은 모델의 응답 길이와 정확도에 직접적인 영향을 줍니다

이런 조절 기능은 비용·연산량·정확도 간 균형을 쉽게 맞출 수 있다는 이점이 있습니다.
예를 들어
- 간단한 지식 질문
- 오타 수정 같은 단순 편집 작업
등에서는 긴 추론 과정을 생략함으로써 시간·비용을 아끼고 불필요한 장황한 응답을 피할 수 있습니다.
참고로 초기 Qwen3 모델들 역시 reasoning 모드를 켜고 끄는 기능을 제공했습니다.(enable_thinking=True/False).
다만 출시 이후 Qwen3 팀은 하이브리드 모델을 포기하고 Instruct / Thinking / Coder 모델을 완전히 분리된 형태로 재정비했습니다.
MXFP4 최적화
흥미롭게도 OpenAI는 gpt-oss 모델을 MoE Experts 부분을 MXFP4 양자화 형식으로 최적화한 상태로 공개했습니다.
양자화는 예전에는 모바일·임베디드 모델에 주로 쓰이던 기술이었지만, 요즘처럼 모델 사이즈가 커지면서 중요성이 급격히 커졌습니다. MXFP4 덕분에 gpt-oss 모델은 단일 GPU 장비에서도 실행 가능합니다.
실제 적용 예시는 다음과 같습니다.
- 120B 모델은
- 단일 80GB H100 또는 그 이후 세대 GPU에서 실행 가능
- 소비자용은 아니지만, 다중 GPU 구성보다 훨씬 저렴
- GPU 간 통신 오버헤드를 걱정할 필요 없음
- AMD MI300X도 출시 첫날부터 지원됨
- 20B 모델은
- 16GB VRAM만 있어도 실행 가능
- 단, RTX 50 시리즈 이상에서 MXFP4를 지원한다는 조건
- (최근 패치로 RTX 4090 같은 구형 카드도 지원 추가)
참고로 MXFP4 없이 실행하면 메모리 사용량이 훨씬 커집니다.
- gpt-oss-20b → 약 48GB (bfloat16)
- gpt-oss-120b → 약 240GB (bfloat16)
주요 벤치마크 및 활용사례
LM Arena 리더보드를 살펴보면, 오픈 웨이트 모델들에 비해 순위가 다소 낮습니다. 특히 비교적 최근 공개된 kimi-k2-thinking이나 glm-4.6과는 차이가 많이 나며, (1425 →1352) Qwen3에 비해서도 성능 자체는 다소 아쉽습니다.


이 외에 gpt-oss 발표 글에서 제공된 reasoning 벤치마크를 보면, gpt-oss 모델들은 OpenAI의 상용 모델뿐 아니라 Qwen3와도 비슷한 수준의 성능을 보입니다.

여기서 알아야 한 사실은 gpt-oss-120b는 Qwen3 A235B-A22B-Thinking-2507 모델보다 거의 절반 크기이며, 단일 GPU에서도 실행 가능하다는 사실입니다.
하지만 벤치마크 점수가 실제 사용성을 정확히 반영하는 것은 아닙니다. 며칠간 실제 사용해 본 유저들의 말에 의하면 gpt-oss가 상당히 유능하긴 했지만, hallucination 발생 빈도가 비교적 높은 편입니다(이는 모델 카드에도 명시되어 있음).
그 이유는 아마 수학·퍼즐·코드 같은 추론 중심 작업에 집중한 학습 과정에서 일반 상식 지식 일부가 희석되었기 때문일 수 있습니다.
하지만 gpt-oss는 애초에 도구 활용(tool use)을 염두에 두고 설계된 모델이기 때문에, 장기적으로 이 약점은 크게 문제 되지 않을 가능성이 있습니다.
오픈소스 LLM에서의 도구 통합은 아직 초기 단계이지만, 발전하게 되면 모델에게 사실 기반 질문을 할 때 외부 정보(검색 등)에 직접 접근하도록 허용하는 방향으로 자연스럽게 흘러갈 것입니다.
그렇게 된다면, 인간 학습에서도 암기보다 문제 해결력이 더 중요하듯, 모델에서도 기억력보다 추론 능력이 더 중요한 가치가 될 수 있습니다.
그리고 openai는 gpt-oss와 o3, o3-mini, o4-mini 등 다른 openAI 모델들과 비교하는 벤치마크를 공개하였습니다.


벤치마크상 gpt-oss-120b는 OpenAI o3‑mini보다 뛰어난 성능을 보여주었으며, Codeforces, 일반 문제 해결(MMLU 및 HLE), 도구 호출(TauBench)에서 OpenAI o4-mini와 비슷하거나 더 우수한 성능을 보여주었습니다.
뿐만 아니라 의료 관련 쿼리(HealthBench)와 경쟁 수학(AIME 2024 & 2025)에서 o4-mini보다 나은 결과를 달성했습니다.
gpt-oss-20b는 작은 규모에도 불구하고 동일한 평가에서 OpenAI o3‑mini와 비슷하거나 더 나은 결과를 달성했으며 경쟁 수학과 의료에서는 더 뛰어난 성능을 보여주었습니다.




마무리하며
종합하자면, 일부에서는 이번 발표를 “과하게 포장됐다”는 시선으로 보기도 하지만, 많은 사람들이 실제로 쓰는 OpenAI가 직접 공개한 모델이라는 점에서 긍정적인 의미가 큽니다. 앞으로도 이런 흐름이 계속되어 더 다양한 모델이 등장하길 기대합니다.
물론 벤치마크만으로 실제 활용도를 온전히 판단할 수는 없고, 아직 충분한 사용 사례가 쌓인 것도 아닙니다. 그럼에도 오픈웨이트·로컬·프라이빗 모델을 다루는 이들에게 점점 더 좋은 환경이 마련되고 있다는 사실만큼은 분명해 보입니다.
Reference
- https://magazine.sebastianraschka.com/p/from-gpt-2-to-gpt-oss-analyzing-the
- https://arxiv.org/pdf/2508.10925
- https://huggingface.co/openai/gpt-oss-20b
- https://deepmind.google/models/gemini-diffusion/
- https://openai.com/ko-KR/index/introducing-gpt-oss/
- https://arxiv.org/pdf/1706.03762
- https://www.researchgate.net/figure/A-plot-of-the-swish-activation-function-the-GELU-activation-function-and-the-ReLU_fig24_376410479
- https://arxiv.org/pdf/2408.00118
- https://arxiv.org/abs/2401.06066
- https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
- https://lmarena.ai/
- https://huggingface.co/Qwen/Qwen3-235B-A22B-Thinking-2507
'AI > LLM' 카테고리의 다른 글
| LLM은 진짜 100K 토큰을 전부 다 볼까? (0) | 2026.01.04 |
|---|---|
| oLLM (0) | 2025.11.02 |
| Context Engineering (0) | 2025.09.11 |
| Testing 18 RAG Techniques to Find the Best (1) | 2025.05.27 |
| LLM을 서빙하는 프레임워크, vLLM 사용법 (0) | 2025.05.06 |