
들어가며
최근 공개되는 오픈소스 언어모델들의 스펙 시트를 살펴보면, 입력 토큰의 최대 길이가 128k에서 256k에 달하는 경우를 흔히 목격하게 됩니다. 하지만 30B 이하의 매개변수를 가진 경량 모델들이 과연 해당 길이에서 유의미한 정보 처리 능력을 갖추고 있는지에 대해서는 늘 의구심이 뒤따랐습니다.
특히 한국어 환경에서의 실효성은 검증된 바가 적기에, 개인적인 궁금증을 해소하고자 시중의 모델들을 대상으로 직접 실험을 수행하였습니다.
테스트 설계 및 대상
테스트는 아래 github repo를 참고하였으며, 데이터셋은 한국어로 새로 생성하였고, 코드 일부를 수정하여 테스트를 진행하였습니다.
LLMTest_NeedleInAHaystack
GitHub - gkamradt/LLMTest_NeedleInAHaystack: Doing simple retrieval from LLM models at various context lengths to measure accura
Doing simple retrieval from LLM models at various context lengths to measure accuracy - gkamradt/LLMTest_NeedleInAHaystack
github.com
실제 테스트에 활용한 코드, 데이터가 있는 github
https://github.com/parkchanghyup/Kor-NeedleInHaystack
GitHub - parkchanghyup/Kor-NeedleInHaystack
Contribute to parkchanghyup/Kor-NeedleInHaystack development by creating an account on GitHub.
github.com
테스트 설계
[1] Single Needle Position Retrieval
특정 컨텍스트 길이 내에서 정보의 위치(Depth)에 따른 정보 추출 성능 변화를 측정하여, 이른바 'Lost-in-the-Middle' 현상을 검증하였습니다.
- 실험 설계
- 바늘 개수 (N): 1개
- 삽입 위치 (D): 전체 문서의 0%, 10%, 25%, 50%, 75%, 90%, 100% 지점 (총 7개 포인트)
- 사용된 바늘 예시
- “달빛을 연료로 움직이는 도시는 새벽이 되면 천천히 지면으로 가라앉는다.”
- “맛있는 피자를 만들기 위한 비밀 재료는 시나몬입니다.” 등 5종.
[S2] Distributed Multi-Needle Retrieval
대량의 정보 속에서 다수의 특정 정보를 유실 없이 모두 추출할 수 있는 성능을 측정하였습니다.
- 실험 설계
- 바늘 개수 (N): 3개, 5개
- 삽입 위치: 콘텍스트 내 랜덤 배치 (단, 바늘 간 최소 10% 이상의 거리 유지)
- 사용된 바늘 예시 :
- “김길동의 취미는 의미 없는 약속 시간을 달력에 표시하는 것이다.”
- “김길동 취미는 한 번도 사용되지 않은 단축키를 찾는 작업이다.” 등 5종.
테스트한 모델들
Qwen3-30B-A3B - https://huggingface.co/Qwen/Qwen3-30B-A3B
Qwen/Qwen3-30B-A3B · Hugging Face
Qwen3-30B-A3B Qwen3 Highlights Qwen3 is the latest generation of large language models in Qwen series, offering a comprehensive suite of dense and mixture-of-experts (MoE) models. Built upon extensive training, Qwen3 delivers groundbreaking advancements in
huggingface.co
- 오픈소스
- 최대 256K context
- 요즘 제일 많이 쓰이는 30B급 모델 중 하나
Kanana-2-30B-A3B (Kakao) - https://huggingface.co/kakaocorp/kanana-2-30b-a3b-instruct
kakaocorp/kanana-2-30b-a3b-instruct · Hugging Face
🤗 Kanana-2 Models | 📕 Kanana-2 Blog Kanana-2 Hightlights Kanana-2, the latest open-source evolution of the Kanana model family, is designed specifically for Agentic AI, presenting substantial enhancements in tool calling, complex instruction
huggingface.co
- 오픈소스
- 최대 입력 길이: 32K
- 카카오의 최신 오픈소스 모델
Gemini 2.5 Flash Lite
- ❌ 오픈소스 아님 (비교용)
- Google 경량 모델
- 최대 1000K context 지원
모델 별 테스트 contxet 범위
| 모델 명 | 최대 테스트 context 길이 |
| Kanana-2-30B | 32K |
| Qwen3-30B-A3B | 100K |
| Gemini 2.5 Flash Lite | 100K |
테스트 결과 분석
[1] Single Needle Test 결과
가장 기본적인 정보 검색 능력을 측정한 결과는 아래와 같습니다.
| 모델 | 평균 점수 | 표준편차 | 최고/최저 점수 |
| Qwen3-30B-A3B | 10.00 | 0.00 | 10.00 / 10.00 |
| Gemini 2.5 Flash Lite | 9.95 | 0.29 | 10.00 / 8.20 |
| Kakao Kanana-2-30B | 9.23 | 0.86 | 10.00 / 7.20 |



히트맵을 분석하면, Qwen3는 전 구간에서 무결점의 성능을 유지합니다. 반면 Kakao Kanana-2는 24,000~28,000 토큰 구간에서 depth와 무관하게 점수가 하락하는 '성능 저하 구간'이 관찰됩니다.
[2] Multi-Needle Test 결과 (3개 및 5개 추출)
추출해야 할 정보의 양이 늘어날 때 모델의 정보 추출 능력을 평가한 결과입니다.

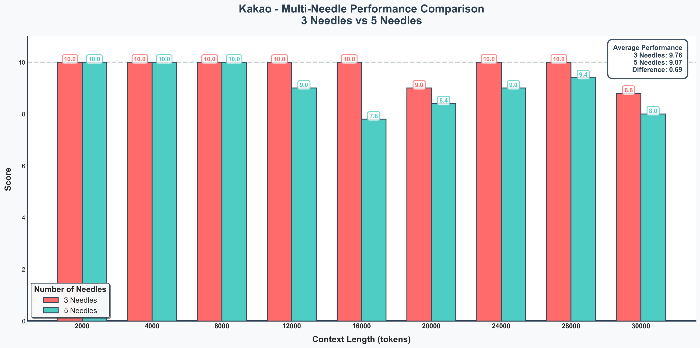

- Qwen3-30B-A3B: 바늘 개수에 관계없이 10.00점을 유지하며 압도적인 일관성을 입증하였습니다.
- Kakao Kanana-2-30B: 5개 바늘 추출 시 평균 9.07점으로 하락하며, 콘텍스트가 길어질수록 다중 정보 처리 능력이 저하되는 양상을 보였습니다.
- Gemini 2.5 Flash Lite: 가장 큰 성능 저하가 확인되었다. 특히 5개 바늘 테스트 시 평균 8.43점, 100k 지점에서는 5.8점까지 급락하며 다중 정보 검색에서의 취약점을 드러냈습니다.
[3] 모델별 성능 요약
Qwen3-30B-A3B
수행한 모든 테스트 케이스(1, 3, 5 Needles) 및 100k에 달하는 전 구간에서 만점이라는 경이로운 성능을 보여주었습니다.
위치나 정보의 밀도와 관계없이 완벽한 정보 추출 성능을 보였으며, 사람들이 많이 쓰는 데는 이유가 있는 거 같습니다.
Kakao Kanana-2-30B
전반적으로 우수한 성능을 보였으나, 24,000~28,000 토큰 구간에서 위치(Depth)와 관계없이 점수가 하락(최저 7.2점)하였습니다.
최대 입력 길이인 32k에 근접할수록 성능 변동성이 커지는 특성을 보이고, 다른 모델에 비해 최대 입력길이가 짧은 것이 다소 아쉽습니다.
Gemini 2.5 Flash Lite
단일 정보 검색(Single Needle)에서는 뛰어난 성능을 보였으나, 추출해야 할 정보가 늘어날수록 성능이 급격히 하락하였습니다. 특히 100k 컨텍스트 + 5개 정보 추출 시나리오에서는 5.8점을 기록하며 긴 context에서 정보 추출 성능의 한계를 드러냈습니다.
마무리하며
종합적으로 평가하자면, Qwen3의 성능이 타 모델 대비 압도적으로 우수함을 확인하였습니다. Kakao Kanana-2 모델은 Qwen3와 비교하여 모든 지표에서 아쉬운 결과를 보여주었으며, 단순 챗봇 이상의 고도화된 컨텍스트 처리가 필요한 작업이라면 굳이 해당 모델을 채택할 이유가 없어보입니다.
또한, 로컬 GPU 자원이 부족하더라도 OpenRouter.ai와 같은 플랫폼을 통해 Qwen 모델을 API 형태로 매우 저렴하게 이용할 수 있습니다.
- Qwen3 비용

- Gemini 2.5 Flash-Lite 비용

- 수치상으로도 Qwen3가 더 경제적이면서 뛰어난 성능을 보장합니다.
이번 실험을 통해 오픈소스의 최대 입력 token에 따른 성능을 비교해 보았습니다.
많은 테스트를 해보진 못했지만, 그래도 오픈소스 모델이 보여준 기술적 진보는 유료 상용 모델을 위협하기에 충분한 수준에 도달했다는 것을 다시 한번 느낄 수 있었습니다.
긴 글 읽어주셔서 감사합니다.
'AI > LLM' 카테고리의 다른 글
| GPT-OSS (0) | 2025.11.23 |
|---|---|
| oLLM (0) | 2025.11.02 |
| Context Engineering (0) | 2025.09.11 |
| Testing 18 RAG Techniques to Find the Best (1) | 2025.05.27 |
| LLM을 서빙하는 프레임워크, vLLM 사용법 (0) | 2025.05.06 |