
서론
최근(?) 출시된 LLM을 보면 input text를 128K를 지원하는 경우를 심심치 않게 볼 수 있습니다.
불과 몇달전만 하더라도 4K ~ 8K가 고작이었던 것 같은데 어떻게 이렇게 비약적으로 상승할 수 있게 되었는지 궁금증을 가지게 되었습니다.
그러던 중, Qwen2.5 모델을 활용하기 위해 Hugging Face의 레포지토리를 읽다 보니, 긴 텍스트에 대한 처리가 필요하다는 언급이 있었습니다. 이 과정에서 RoPE Scaling이라는 개념을 접하게 되었고, 이에 대해 더 깊이 알아보며 이 글을 작성하게 되었습니다.

What is RoPE Scaling?
RoPE Scaling은 LLM이 입력된 텍스트의 순서를 이해할 수 있도록 위치 정보를 임베딩에 추가하는 Positional Encoding 기법 중 하나입니다.

문서 요약을 위해 평균 token 수가 100인 데이터로 학습된 LLM이 있다고 가정해봅시다. 학습 데이터의 범위내에 있는 문서들에 대해서는 LLM은 요약을 그럭저럭 잘 진행할 수 있을 것입니다. 그러나 token 수가 500이상인 문서에 대해 요약을 요청하면, LLM은 제대로된 요약을 하지 못할 가능성이 존재합니다.
이러한 문제를 해결하는 방법 중 하나가 바로 RoPE Scaling입니다.
일반적으로 RoPE는 삼각함수를 사용하여 텍스트의 순서 정보를 표현하는데, 이때 사용되는 기본 기저값(base value)을 조정하면 RoPE의 위치 정보가 더 긴 문맥에서도 일관되게 유지됩니다. 기저값은 삼각함수의 주기를 조절하는 역할을 하며, 이를 높이면 주기가 길어지고, 낮추면 주기가 짧아집니다.
RoPE Scaling의 문제점 및 한계
RoPE Scaling은 학습된 문맥 길이를 넘어서 더 긴 텍스트에 적용하기 위해 RoPE의 기저값을 조정합니다. 하지만 몇 가지 문제와 한계를 가지고 있습니다
- 기저값 선택의 어려움: RoPE의 기저값을 크게 또는 작게 설정할 경우 특정 길이에서 성능이 개선될 수 있지만, 기저값에 따라 특정 문맥 길이 이상에서는 성능이 급격히 저하될 수 있습니다.
- 성능 한계: 너무 큰 기저값은 일정 문맥 길이 이상에서는 성능이 급격히 떨어지게 하고, 너무 작은 기저값은 제한된 문맥 길이에서만 성능을 보장합니다. 이를 해결하지 않으면 RoPE의 위치 인코딩이 학습된 문맥을 벗어나면 비정상적인 결과를 낼 수 있습니다.
- 복잡한 최적화 필요성: RoPE Scaling을 적용하려면 최적의 기저값과 학습 길이를 설정해야 하는데, 이는 모델과 학습 데이터에 따라 달라지므로 복잡한 최적화 작업이 필요합니다.
LLM에서 효과적으로 RoPE Scaling을 사용하기 위한 방법
그렇다면 RoPE Scaling의 문제점을 어떻게 해결하여 LLM에 활용할 수 있을까요?
위 물음에 대한 답변은 아래 논문에서 체계적으로 분석하고 있습니다. 그 중 일부분의 내용만 작성하겠습니다.
Scaling Laws of RoPE-based Extrapolation
1. 기저값 조정
논문에 따르면 RoPE의 기저값을 단순히 고정된 10,000에서 벗어나 크거나 작은 값으로 설정할 때 모델의 extrapolation성능이 크게 향상됩니다. 특히, LLaMA2 모델에서는 기저값을 100만으로 설정하거나 더 작은 500 등의 값으로 설정할 때 학습된 문맥 길이를 훨씬 초과하는 긴 문맥에서도 성능이 유지되었습니다. 이처럼 문맥 길이에 따른 최적의 기저값을 찾아 적용하는 것이 중요합니다.
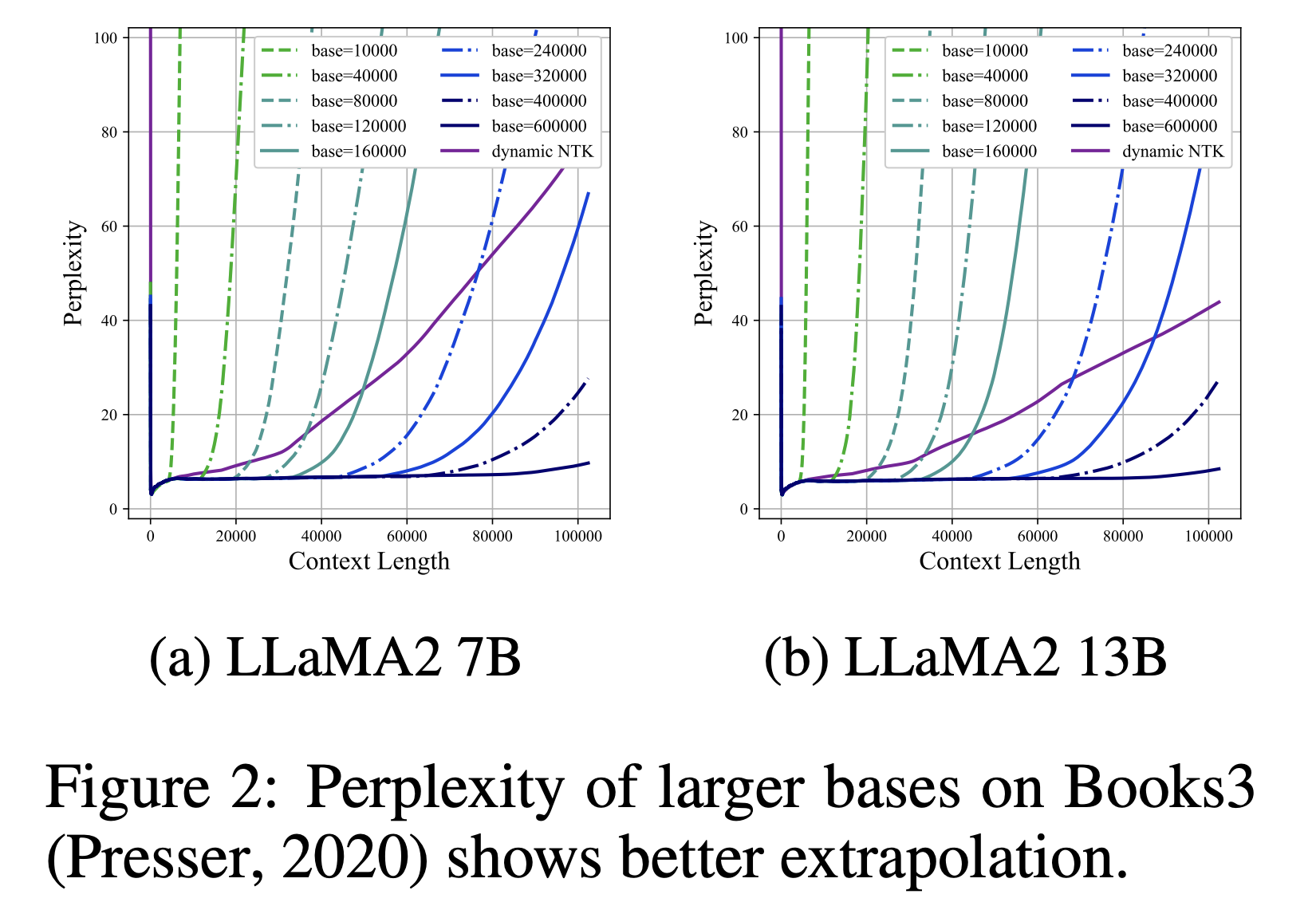

2. 스케일링 법칙을 적용한 개선
스케일링 법칙을 적용한 개선의 의미는 RoPE의 기저값(base 값)을 조정하여 모델이 더 긴 컨텍스트 길이를 잘 다룰 수 있도록 학습시키라는 의미입니다. 여기서 핵심은 RoPE가 위치 정보를 어떻게 다루는지를 고려해, 기저값을 더 크게 또는 더 작게 설정하여 모델의 extrapolation 성능을 개선하는 것입니다.
작은 기저값을 사용하는 경우:
- 기저값을 작게 설정하면, 모델이 훈련 중에 위치 정보를 더 세밀하게 학습할 수 있게 됩니다.
- 작은 기저값(예: 500)을 사용하면 모델이 훈련된 길이보다 더 긴 콘텍스트에서도 성능 저하가 완만하게 일어나며, 매우 긴 문장에서도 안정적으로 정보를 처리할 수 있습니다.
- 수학적으로는 작은 기저값이 위치 정보의 주기성을 더 촘촘하게 표현하게 되어, 모델이 긴 콘텍스트 길이에서도 위치 변화를 잘 이해하도록 돕습니다.
큰 기저값을 사용하는 경우:
- 기저값을 크게 설정(예: 1,000,000)하면 모델이 훈련된 컨텍스트 길이보다 더 길어진 문맥에서도 성능을 유지할 수 있는 extrapolation 한계를 늘릴 수 있습니다.
- 하지만 큰 기저값은 어느 정도 한계가 있어서, 특정 길이를 초과하면 성능이 급격히 저하될 수 있습니다. 따라서 이 방법은 비교적 예측 가능한 길이 내에서 안정적인 성능을 원할 때 효과적입니다.
- 큰 기저값은 RoPE가 각 위치 간 간격을 더 길게 설정하도록 하여, 훈련되지 않은 길이에서도 위치 정보를 비교적 안정적으로 보존할 수 있게 해 줍니다.
앞서 언급한 논문에서는 위 2가지 기법 말고도, RoPE 기본값을 학습 데이터의 길이에 따라 동적으로 조정하는 동적 NTK방법,
서로 다른 기저값으로 모델을 추가학습하는 방법 등 다양한 방법으로 RoPE Scaling을 LLM에서 활용하기 위한 방법들을 설명하고 있습니다. 더 상세한 내용이 궁금하신 분들은 논문을 한번 읽어보는것도 좋을것 같습니다.
결론
결론적으로, RoPE Scaling은 LLM이 더 긴 문맥 길이를 처리하도록 도와주는 중요한 기술입니다.
그러나 RoPE Scaling을 효과적으로 활용하기 위해서는 기저값을 적절하게 조정하는 것이 핵심입니다. 작은 기저값은 세밀한 위치 정보를 학습하게 해 주어 긴 문장에서도 안정적인 성능을 보장하지만, 특정 길이 이상에서는 성능이 저하될 수 있습니다.
반면, 큰 기저값은 더 긴 문맥에서 성능을 유지하는 데 유리하지만, 지나치게 큰 경우에는 모델의 성능이 급격히 떨어질 수 있습니다. 이러한 한계를 해결하기 위해 동적 NTK 방법이나 서로 다른 기저값으로 추가 학습을 수행하는 등 다양한 개선 방법이 연구되고 있으며, 이는 LLM의 extrapolation 성능을 더욱 강화하고자 하는 방향으로 나아가고 있습니다.
이러한 최적화 기법을 통해 RoPE Scaling이 다양한 길이의 문맥에서도 안정적인 성능을 발휘할 수 있는 가능성을 보여주고 있습니다.
Reference
'딥러닝 > LLM' 카테고리의 다른 글
| LLM 효율성을 높이는 양자화 기법 탐구 및 성능 분석 (0) | 2024.11.12 |
|---|---|
| All you need to know about RAG (0) | 2024.10.09 |
| RAG(Relevance-Augmented Generation): LLM의 한계를 넘는 새로운 접근 (0) | 2024.10.09 |
| LLM을 활용한 지식 증류: sLLM 성능 최적화 실험 (3) | 2024.09.01 |
| LLM의 양자화가 한국어에 미치는 영향 (0) | 2024.08.19 |