XLM(cross-lingual language model)
다국어를 목표로 사전 학습 시킨 BERT를 교차 언어 모델(XLM)이라고 한다.
XLM은 단일 언어 및 병렬 데이터셋을 사용해 사전 학습된다. 병렬 데이터셋은 언어 쌍의 텍스트로 구성된다. 즉 ,2개의 다른 언어로 된 동일한 텍스트로 구성된다.
예를 들어 영어 문장이 있다고 가정하면 프랑스어처럼 다른 언어로 된 문장이 동시에 있다. 이 병렬 데이터셋을 교차 언어 데이터셋이라고 한다.
또한 XLM은 바이트 쌍 인코딩(BPE)를 사용하고 모든 언어에서 공유된 어휘를 사용한다.
XLM의 사전 학습 전략
XLM은 다음을 사용해 사전 학습한다.
- 인과 언어 모델링(CLM)
- 마스크 언어 모델링(MLM)
- 번역 언어 모델링(TLM)
CLM(causal language modeling)
CLM은 가장 간단한 사전 학습 방법이다. CLM의 목표는 주어진 이전 단어셋에서 현재 단어의 확률을 예측 하는 것이다.
$P(W_t|W_1, W_2,...,W_{t-1};\theta)$ 로 표현 된다.
MLM(masked language modeling)
MLM 태스크에서는 토큰의 15%를 무작위로 마스킹 하고 마스크된 토큰을 예측하도록 학습한다. 80-10-10% 규칙으로 총 토큰의 15%를 마스킹 한다.
- 80% 토큰을 [mask]토큰으로 교체
- 10%는 임의의 토큰(무작위 단어)로 교체
- 나머지 10% 토큰은 변경하지 않음
BERT를 학습시킨 방법과 마찬가지로 MLM 태스크를 사용해 XLM 모델을 학습시키지만 2가지의 차이가 있다.
- BERT는 문장 쌍에서 몇 개의 토큰을 무작위로 마스킹한 후 모델에 문장 쌍을 입력한다. 그러나 XLM 에서는 꼭 문장 쌍을 제공할 필요가 없다. 대신 임의의 문장을 특수 토큰[\s]로 구분하여 입력한다. 총 토큰의 길이는 256으로 유지한다.
- 빈번한 단어와 그렇지 않은 단어의 균형을 맞추기 위해 가중치를 sqrt(1/빈도수)로 해 다항분포에 따라 토큰을 샘플링한다.
아래 그림은 MLM 목적의 XLM 모델이다. 여기서 특수 토큰[\s]로 구분된 임의의 문장을 입력으로 사용하는 것을 알 수 있다.
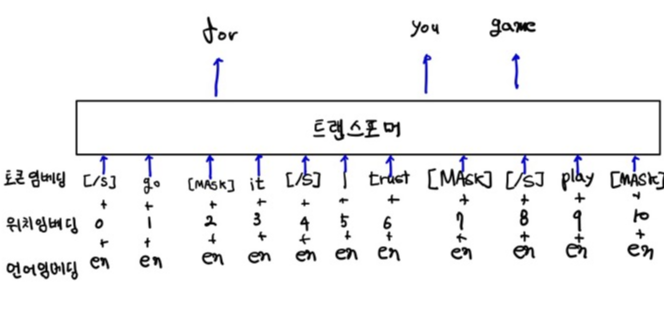
TLM(translation language modeling)
CLM과 MLM에서는 단일 언어 데이터에 대해 모델을 학습한다. 하지만 TLM에서는 서로 다른 두 언어로서 동일한 텍스트로 구성된 병렬 교차 언어 데이터를 이용해 모델을 학습시킨다.
TLM 방법은 앞서 본 MLM과 동일하게 작동한다. MLM과 유사하게 여기서는 마스크된 단어를 예측하도록 모델을 학습시킨다. 그러나 임의의 문장을 입력하는 것이 아니라 교차 언어 표현을 학습시키기 위해 병렬 문장을 입력한다.
아래 그림은 TLM을 수행하는 XLM 모델이다. 그림에서 볼 수 있듯이 병렬 문장을 빙력한다. 즉, 2개의 다른 언어로 된 동일한 텍스트를 제공한다.
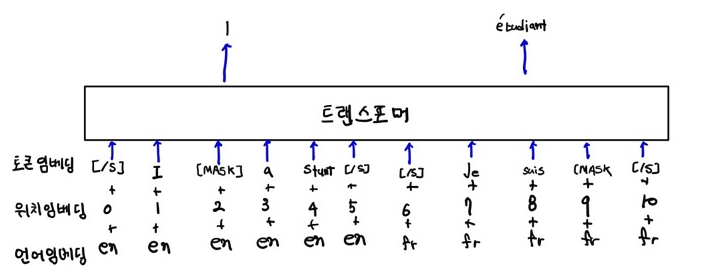
XLM에서는 다음 3가지 방법으로 사전 학습을 진행한다.
- CLM 사용
- MLM 사용
- TLM과 MLM을 결합해서 사용
CLM 또는 MLM을 사용해 XLM을 학습시키는 경우 단일 언어 데이터셋을 사용한다. 총 256개의 토큰으로 임의의 문장을 사용한다.
TLM의 경우 병렬 데이터셋을 사용한다. 모델 학습에 MLM과 TLM을 사용하는 경우 MLM과 TLM으로 목적 함수를 변경한다.
XLM-R
XLM-R은 성능 향상을 위해 XLM 에서 몇 가지를 보완한 확장 버전이다. XLM-R은 XLM-RoBERTa로 교차 언어 표현 학습을 위한 기술이다. XLM은 MLM및 TLM을 이용해 학습을 진행했다. MLM은 단일 언어 데이터셋을 사용하고 TLM은 병렬 데이터를 사용한다.
그러나 병렬 데이터셋을 구하는 것은 자료가 적은 언어의 경우 특히 어렵다. 따라서 XLM-R에서는 MLM으로만 모델을 학습시키고 TLM은 사용하지 않는다.
즉, XLM-R에서는 단일 언어 데이터 셋 만 있으면 된다.
XLM-R은 다음 두 가지 구성으로 학습된다.
- $XLM-R_{base}$ : 12개의 인코더 레이어, 14개의 어텐션 헤드 및 768 은닉 크기
- XLM-R : 24개의 인코더 레이어, 16개의 어텐션 헤드 및 1024 은닉 크기.
XLM(cross-lingual language model)
다국어를 목표로 사전 학습 시킨 BERT를 교차 언어 모델(XLM)이라고 한다.
XLM은 단일 언어 및 병렬 데이터셋을 사용해 사전 학습된다. 병렬 데이터셋은 언어 쌍의 텍스트로 구성된다. 즉 ,2개의 다른 언어로 된 동일한 텍스트로 구성된다.
예를 들어 영어 문장이 있다고 가정하면 프랑스어처럼 다른 언어로 된 문장이 동시에 있다. 이 병렬 데이터셋을 교차 언어 데이터셋이라고 한다.
또한 XLM은 바이트 쌍 인코딩(BPE)를 사용하고 모든 언어에서 공유된 어휘를 사용한다.
XLM의 사전 학습 전략
XLM은 다음을 사용해 사전 학습한다.
- 인과 언어 모델링(CLM)
- 마스크 언어 모델링(MLM)
- 번역 언어 모델링(TLM)
CLM(causal language modeling)
CLM은 가장 간단한 사전 학습 방법이다. CLM의 목표는 주어진 이전 단어셋에서 현재 단어의 확률을 예측 하는 것이다.
$P(W_t|W_1, W_2,...,W_{t-1};\theta)$ 로 표현 된다.
MLM(masked language modeling)
MLM 태스크에서는 토큰의 15%를 무작위로 마스킹 하고 마스크된 토큰을 예측하도록 학습한다. 80-10-10% 규칙으로 총 토큰의 15%를 마스킹 한다.
- 80% 토큰을 [mask]토큰으로 교체
- 10%는 임의의 토큰(무작위 단어)로 교체
- 나머지 10% 토큰은 변경하지 않음
BERT를 학습시킨 방법과 마찬가지로 MLM 태스크를 사용해 XLM 모델을 학습시키지만 2가지의 차이가 있다.
- BERT는 문장 쌍에서 몇 개의 토큰을 무작위로 마스킹한 후 모델에 문장 쌍을 입력한다. 그러나 XLM 에서는 꼭 문장 쌍을 제공할 필요가 없다. 대신 임의의 문장을 특수 토큰[\s]로 구분하여 입력한다. 총 토큰의 길이는 256으로 유지한다.
- 빈번한 단어와 그렇지 않은 단어의 균형을 맞추기 위해 가중치를 sqrt(1/빈도수)로 해 다항분포에 따라 토큰을 샘플링한다.
아래 그림은 MLM 목적의 XLM 모델이다. 여기서 특수 토큰[\s]로 구분된 임의의 문장을 입력으로 사용하는 것을 알 수 있다.
TLM(translation language modeling)
CLM과 MLM에서는 단일 언어 데이터에 대해 모델을 학습한다. 하지만 TLM에서는 서로 다른 두 언어로서 동일한 텍스트로 구성된 병렬 교차 언어 데이터를 이용해 모델을 학습시킨다.
TLM 방법은 앞서 본 MLM과 동일하게 작동한다. MLM과 유사하게 여기서는 마스크된 단어를 예측하도록 모델을 학습시킨다. 그러나 임의의 문장을 입력하는 것이 아니라 교차 언어 표현을 학습시키기 위해 병렬 문장을 입력한다.
아래 그림은 TLM을 수행하는 XLM 모델이다. 그림에서 볼 수 있듯이 병렬 문장을 빙력한다. 즉, 2개의 다른 언어로 된 동일한 텍스트를 제공한다.
XLM에서는 다음 3가지 방법으로 사전 학습을 진행한다.
- CLM 사용
- MLM 사용
- TLM과 MLM을 결합해서 사용
CLM 또는 MLM을 사용해 XLM을 학습시키는 경우 단일 언어 데이터셋을 사용한다. 총 256개의 토큰으로 임의의 문장을 사용한다.
TLM의 경우 병렬 데이터셋을 사용한다. 모델 학습에 MLM과 TLM을 사용하는 경우 MLM과 TLM으로 목적 함수를 변경한다.
XLM-R
XLM-R은 성능 향상을 위해 XLM 에서 몇 가지를 보완한 확장 버전이다. XLM-R은 XLM-RoBERTa로 교차 언어 표현 학습을 위한 기술이다. XLM은 MLM및 TLM을 이용해 학습을 진행했다. MLM은 단일 언어 데이터셋을 사용하고 TLM은 병렬 데이터를 사용한다.
그러나 병렬 데이터셋을 구하는 것은 자료가 적은 언어의 경우 특히 어렵다. 따라서 XLM-R에서는 MLM으로만 모델을 학습시키고 TLM은 사용하지 않는다.
즉, XLM-R에서는 단일 언어 데이터 셋 만 있으면 된다.
XLM-R은 다음 두 가지 구성으로 학습된다.
- $XLM-R_{base}$ : 12개의 인코더 레이어, 14개의 어텐션 헤드 및 768 은닉 크기
- XLM-R : 24개의 인코더 레이어, 16개의 어텐션 헤드 및 1024 은닉 크기.