BART
BART는 페이스북에서 개발한 모델 아키텍쳐이다. BART는 트랜스포머 아키텍쳐를 기반으로한다.
BART는 본질적으로 노이즈 제거 오토 인코더(denoising autoencoder)다. 손상된 텍스트를 재구성하며 학습을 진행한다.
BERT와 마찬가지로 사전 학습된 BART를 사요하고 여러 다운스트림 태스크에 맞추 ㅓ파인튜닝할 수 있다. BART는 텍스트 생성에 가장 적합하다. 또한 언어 번역 및 이해와 같은 다른 태스크에도 사용된다.
BART 아키텍쳐
BART는 본질적으로 이놐더와 디코더가 있는 트랜스포머 모델이다. 손상된 텍스트를 인코더에 입력하고 인코더는 주어진 텍슽의 표현을 학습시키고 그 표현을 디코더로 보낸다.
디코더는 인코더가 생성한 표현을 가져와 손상되지 않은 원본 텍스트를 재구성 한다.
BART의 인코더는 양방향이이고 디코더는 단방향(왼쪽에서 오른쪽)이다.
아래그림 BART의 아키텍쳐이다. 몇 개의 단어를 마스킹 하여 원본 텍스트를 손상시키고 인코더에 입력한다.
인코더는 주어진 텍스트의 표현을 학습시키고 그 표현을 디코더로 보낸이후 원래의 텍스트(손상되지 않은)를 복구 시킨다.
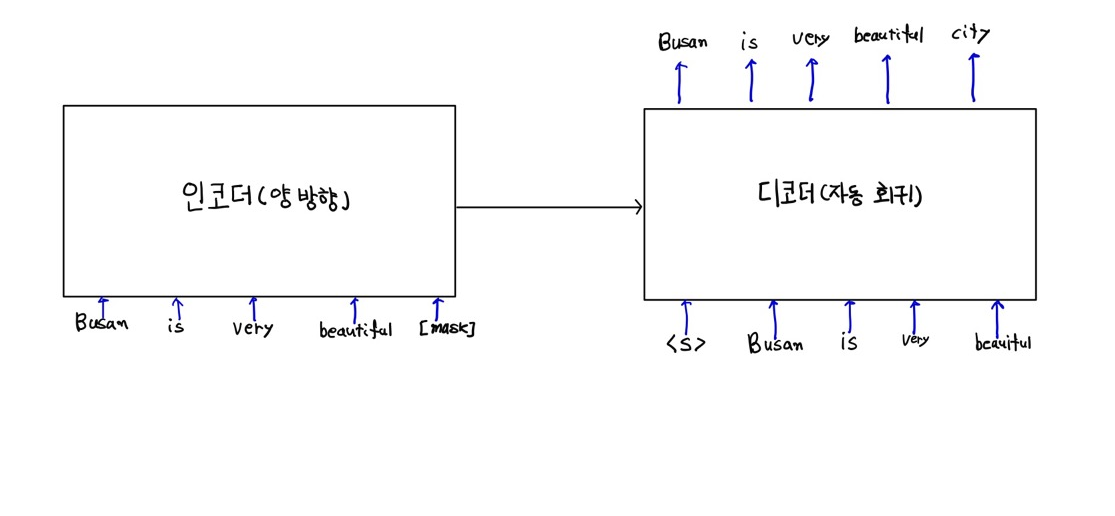
BERT에서는 마스크된 토큰을 인코더에 입력한다음 인코더의 결과를 마스크된 토큰을 예측하는 피드포워드 네트워크에 입력한다. 그러나 BART에서는 인코더의 결과를 디코더에 입력해 원래 문장을 생성 및 재구성한다.
노이징 기술
인코더에 입력하는 데이터를 노이징하는 기술은 여러가지가 있다.
- 토큰 마스킹 : 몇 개의 토큰을 무작위로 마스킹
- 토큰 삭제 : 일부 토큰을 무작위로 삭제
- 토큰 채우기 : 단일 [MASK] 토큰으로 연속된 토큰셋을 마스킹
- 한국은 떡볶이가 제일 맛있다. -> 한국은 [MASK] 맛있다.
- 문장 셔플 : 문장의 순서를 무작위로 섞음
- 문서 회전 : 문서를 특정 단어 부터 다시 시작 시킨다.
- 떡볶이 중 신전떡볶이가 제일 맛있어요 -> 신전떡볶이가 제일 맛있어요 떡볶이중
노이징 기술에 따른 사전 학습 비교
| 노이징 기술 | SQuAD 1.1 F1 | MNLI Acc | ELI5 Acc | XSum PPL | ConvAI2 PPL | CNN/DM PPL |
|---|---|---|---|---|---|---|
| 토큰 마스킹 | 90.4 | 84.1 | 25.05 | 7.08 | 11.73 | 6.10 |
| 토큰 삭제 | 90.4 | 84.1 | 24.61 | 6.90 | 11.46 | 5.87 |
| 텍스트 채우기 | 90.8 | 84.0 | 24.26 | 6.61 | 11.05 | 5.83 |
| 문장 회전 | 77.2 | 75.3 | 53.69 | 17.14 | 19.87 | 10.59 |
| 문장 셔플 | 58.4 | 81.5 | 41.87 | 10.93 | 16.67 | 7.89 |
| 텍스트 채우기 + 문장 셔플 | 90.8 | 83.8 | 24.17 | 6.62 | 11.12 | 5.41 |
BART로 텍스트 요약 하기
# 라이브러리 로딩
from transformers import BartTokenizer, BartForConditionalGenerationmodel = BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn')
tokenizer =BartTokenizer.from_pretrained('facebook/bart-large-cnn')text = "Machine learning (ML) is the study of computer algorithms that can improve automatically through experience and by the use of data.\
It is seen as a part of artificial intelligence. Machine learning algorithms build a model based on sample data, known as training data, \
in order to make predictions or decisions without being explicitly programmed to do so.[2] Machine learning algorithms are used in a wide variety of applications, \
such as in medicine, email filtering, speech recognition, and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks"# 텍스트 토큰화
inputs = tokenizer([text], max_length = 1024, return_tensors = 'pt')
# 모델로 요약 토큰 생성
summary = model.generate(inputs['input_ids'], num_beams = 4,
max_length = 100, early_stopping = True)# 요약 문을 토크나이저로 디코드
summary = ([tokenizer.decode(i, skip_special_tokens = True,
clean_up_tokenization_spaces=False) for i in summary])summary['Machine learning is the study of computer algorithms that can improve automatically through experience and by the use of data. It is seen as a part of artificial intelligence. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, speech recognition, and computer vision.']'딥러닝 > NLP' 카테고리의 다른 글
| DistilBERT : 지식 증류BERT (0) | 2022.02.06 |
|---|---|
| SpanBERT (0) | 2022.02.06 |
| XLM-BERT (0) | 2022.01.26 |
| bertsum (0) | 2022.01.26 |
| ROUGE 이해하기 (0) | 2022.01.25 |
BART
BART는 페이스북에서 개발한 모델 아키텍쳐이다. BART는 트랜스포머 아키텍쳐를 기반으로한다.
BART는 본질적으로 노이즈 제거 오토 인코더(denoising autoencoder)다. 손상된 텍스트를 재구성하며 학습을 진행한다.
BERT와 마찬가지로 사전 학습된 BART를 사요하고 여러 다운스트림 태스크에 맞추 ㅓ파인튜닝할 수 있다. BART는 텍스트 생성에 가장 적합하다. 또한 언어 번역 및 이해와 같은 다른 태스크에도 사용된다.
BART 아키텍쳐
BART는 본질적으로 이놐더와 디코더가 있는 트랜스포머 모델이다. 손상된 텍스트를 인코더에 입력하고 인코더는 주어진 텍슽의 표현을 학습시키고 그 표현을 디코더로 보낸다.
디코더는 인코더가 생성한 표현을 가져와 손상되지 않은 원본 텍스트를 재구성 한다.
BART의 인코더는 양방향이이고 디코더는 단방향(왼쪽에서 오른쪽)이다.
아래그림 BART의 아키텍쳐이다. 몇 개의 단어를 마스킹 하여 원본 텍스트를 손상시키고 인코더에 입력한다.
인코더는 주어진 텍스트의 표현을 학습시키고 그 표현을 디코더로 보낸이후 원래의 텍스트(손상되지 않은)를 복구 시킨다.
BERT에서는 마스크된 토큰을 인코더에 입력한다음 인코더의 결과를 마스크된 토큰을 예측하는 피드포워드 네트워크에 입력한다. 그러나 BART에서는 인코더의 결과를 디코더에 입력해 원래 문장을 생성 및 재구성한다.
노이징 기술
인코더에 입력하는 데이터를 노이징하는 기술은 여러가지가 있다.
- 토큰 마스킹 : 몇 개의 토큰을 무작위로 마스킹
- 토큰 삭제 : 일부 토큰을 무작위로 삭제
- 토큰 채우기 : 단일 [MASK] 토큰으로 연속된 토큰셋을 마스킹
- 한국은 떡볶이가 제일 맛있다. -> 한국은 [MASK] 맛있다.
- 문장 셔플 : 문장의 순서를 무작위로 섞음
- 문서 회전 : 문서를 특정 단어 부터 다시 시작 시킨다.
- 떡볶이 중 신전떡볶이가 제일 맛있어요 -> 신전떡볶이가 제일 맛있어요 떡볶이중
노이징 기술에 따른 사전 학습 비교
| 노이징 기술 | SQuAD 1.1 F1 | MNLI Acc | ELI5 Acc | XSum PPL | ConvAI2 PPL | CNN/DM PPL |
|---|---|---|---|---|---|---|
| 토큰 마스킹 | 90.4 | 84.1 | 25.05 | 7.08 | 11.73 | 6.10 |
| 토큰 삭제 | 90.4 | 84.1 | 24.61 | 6.90 | 11.46 | 5.87 |
| 텍스트 채우기 | 90.8 | 84.0 | 24.26 | 6.61 | 11.05 | 5.83 |
| 문장 회전 | 77.2 | 75.3 | 53.69 | 17.14 | 19.87 | 10.59 |
| 문장 셔플 | 58.4 | 81.5 | 41.87 | 10.93 | 16.67 | 7.89 |
| 텍스트 채우기 + 문장 셔플 | 90.8 | 83.8 | 24.17 | 6.62 | 11.12 | 5.41 |
BART로 텍스트 요약 하기
# 라이브러리 로딩
from transformers import BartTokenizer, BartForConditionalGenerationmodel = BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn')
tokenizer =BartTokenizer.from_pretrained('facebook/bart-large-cnn')text = "Machine learning (ML) is the study of computer algorithms that can improve automatically through experience and by the use of data.\
It is seen as a part of artificial intelligence. Machine learning algorithms build a model based on sample data, known as training data, \
in order to make predictions or decisions without being explicitly programmed to do so.[2] Machine learning algorithms are used in a wide variety of applications, \
such as in medicine, email filtering, speech recognition, and computer vision, where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks"# 텍스트 토큰화
inputs = tokenizer([text], max_length = 1024, return_tensors = 'pt')
# 모델로 요약 토큰 생성
summary = model.generate(inputs['input_ids'], num_beams = 4,
max_length = 100, early_stopping = True)# 요약 문을 토크나이저로 디코드
summary = ([tokenizer.decode(i, skip_special_tokens = True,
clean_up_tokenization_spaces=False) for i in summary])summary['Machine learning is the study of computer algorithms that can improve automatically through experience and by the use of data. It is seen as a part of artificial intelligence. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, speech recognition, and computer vision.']'딥러닝 > NLP' 카테고리의 다른 글
| DistilBERT : 지식 증류BERT (0) | 2022.02.06 |
|---|---|
| SpanBERT (0) | 2022.02.06 |
| XLM-BERT (0) | 2022.01.26 |
| bertsum (0) | 2022.01.26 |
| ROUGE 이해하기 (0) | 2022.01.25 |