지식 증류 기반 BERT
사전 학습된 BERT를 사용하는데 따르는 문제는 계산 비용이 많이 들고 제한된 리소스로 모델을 실행하기가 매우 어렵다는 것이다. 사전 학습된 BERT는 매개변수가 많고 추론에 시간이 오래 걸려 휴대폰과 같은 edge 디바이스에서 사용이 어렵다.
이러한 문제를 완하 하기 위해 사전 학습된 large bert에서 small bert로 지식을 이전하는 지식 증류를 사용할 수 있다.
지식 증류 란 ?
지식 증류란 사전 학습된 대형 모델의 동작을 재현하기 위해 소형 모델을 학습시키는 모델 압축 기술이다. teacher-student learning 이라고도 하는데, 사전 학습된 대형 모델은 교사이고 소형 모델은 학생이 된다.
문장의 다음 단어를 예측하기 위해 대형 모델을 사전 학습했다고 가정하자.
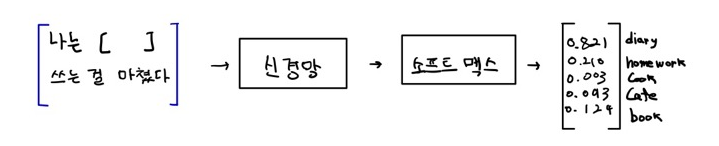
위 그림에서 네트워크가 반환한 확률 분포를 관찰할 수 있다. diary(일기)라는 단어의 확률이 높기 때문에 문장에서 다음 단어로 diary를 선택한다.
확률이 높은 단어를 선택하는 것 외에도 네트워크가 반환한 확률 분포에서 다른 유용한 정보를 추출할 수는 없을까?
아래 그림처럼 확률이 가장 높은 단어 외에도 다른 단어에 비해 확률이 높아 눈에 띄는 단어를 확인할 수 있다.

이것은 diray라는 단어 외에도 book과 homework가 문장과 관련 있음을 알 수 있다. 이것을 dark knowledge(암흑지식) 이라고 한다. 지식을 증류하는 동안 학생 네트워크가 교사로부터 이 암흑 지식에 대해서도 배우길 원한다.
하지만 실제로 서능 좋은 모델은 아래 그림과 같이 정답 클래스의 경우 1에 가까운 높은 확률을 반환하고 이외의 다른 클래스의 경우 0에 매우 가까운 확률을 반환한다.

위와 같은 상황이라면 암흑 지식을 추출하기가 쉽지 않다. 그럴 때 사용하는 것이 temperature이다. temperature와 함께 소프트맥스를 사용하여 확률 분포를 평활화시킨다.
temperature에 대한 softmax 함수는 아래와 같다.
 |
 |
결과적으로 소프트맥스 temperature를 사용해 암흑 지식을 얻을 수 있다. 이를 위해 먼저, 암흑 지식을 얻기 위해 소프트맥스 템퍼러처로 교사 네트워크를 사전 학습한다.
그런 다음 지식 증류(교사로부터 학생에게 지식 전달)를 통해 이 암흑 지식을 교사로부터 학생에게 전달한다.
DistilBERT : BERT의 지식 증류 버전
이름에서 알 수 있듯이 DistilBERT는 지식 증류를 사용한다. DistilBERT의 궁극적인 아이디어는 사전 학습된 대규모 BERT 모델을 기반으로 지식 증류를 통해 지식을 소규모 BERT로 이전하는 것이다.
DistilBERT는 대형 bert에 비해 60% 더 빠르며 40% 더 작다
교사-학습 아키텍처
교사와 학생 BERT를 좀 더 자세히 살펴보자.
교사 BERT는 사전 학습된 대규모 BERT 모델이다. 여기서는 사전 학습된 BERT-BASE 모델을 교사로 활용해서 예시를 들어보자.
BERT는 MLM 태스크를 사용해 사전 학습되었으므로 사전 학습된 BERT 모델을 사용해 마스크 된 단어를 예측할 수 있다.
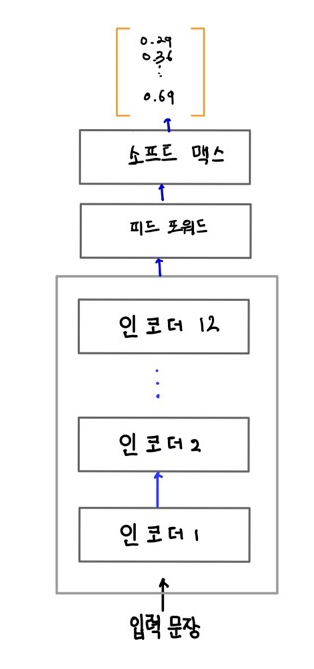
위 그림에서 마스크된 입력 문장이 주어지면 사전 학습된 BERT가 어휘 사전의 모든 단어에 대해 마스크된 단어 확률 분포를 제공한다는 것을 알 수 있다. 이 확류 분포에는 암흑 지식이 포함되어 있으며 이 지식을 학생 BERT에게 전달해야 한다.
학생 BERT 학습
교사 BERT 사전 학습에 사용한 것과 동일한 데이터셋으로 학생 BERT를 학습시킬 수 있다.
RoBERTa 모델에서 몇 가지 학습 방법을 차용했는데, Roberta 링크 지식 증류 학습도 MLM 태스크만 사용해 학생 BERT를 학습시킨다. 동적 마스킹 방법으로 매번 같은 시퀀스에 대해서 다른 마스킹을 적용한다. 또한 큰 배치 크기를 사용한다.
아래 그림과 같이 마스크 된 문장을 교사 BERT 와 학생 BERT에 입력으로 제공하고 어휘 사전에 대한 확률 분포를 출력으로 얻는다. 그리고 소프트 타깃과 소프트 예측 사이의 cross entropy loss로 증류 손실을 계산한다.
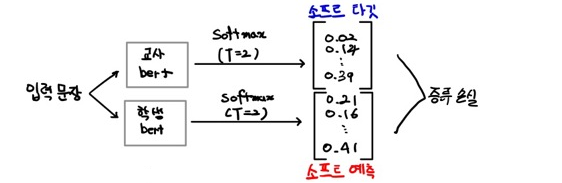
위 그림과 같이 증류 손실과 함께 학생 손실, 즉 MLM 손실에 대한 cross entropy loss도 계산한다.
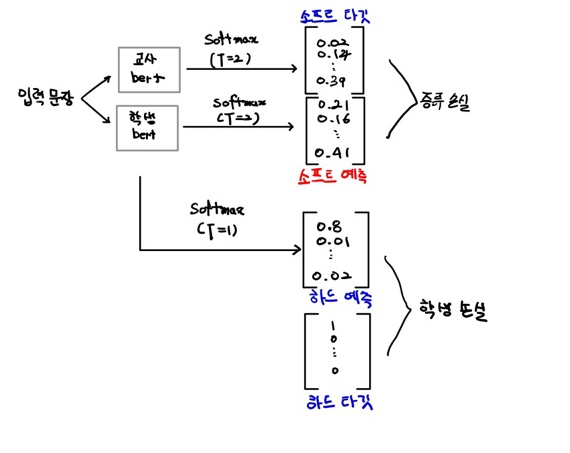
증류 및 학생 손실과는 별도로 코사인 임베딩 손실도 계산한다. 이는 교사와 학생 BERT가 출력하는 벡터 사이의 거리 측정이다. 코사인 임베딩 손실을 최소화하면 학생 임베딩을 더 정확하면서도 교사 임베딩과 유사하게 표현할 수 있다.
따라서 손실 함수는 다음 세 가지 손실의 합계이다.
- 증류 손실
- MLM 손실
- 코사인 임베딩 손실 DistilBERT는 BERT-base 모델의 97% 정도의 성능을 제공한다. DistilBERT는 더 가볍기 때문에 속도가 60%가 더 빠르다.
- 위의 세 가지 손실의 합을 최소화하는 방향으로 학생 BERT(DistilBERT)를 학습시킬 수 있다. 이러한 방식으로 학생 BERT는 교사로부터 지식을 습득하게 된다.
결론
지식 증류는 대규모 BERT 모델의 성능을 경량화된 소형 모델에 효과적으로 이전할 수 있는 중요한 기술입니다.
BERT와 같은 사전 학습된 대형 모델은 높은 계산 비용과 리소스 한계로 인해 많은 제약이 있지만, 지식 증류를 통해 이러한 한계를 극복할 수 있습니다.
DistilBERT는 그 대표적인 사례로, BERT의 성능을 97% 이상 유지하면서도 훨씬 빠르고 가벼운 모델을 제공합니다. 이를 통해 제한된 리소스에서도 효율적으로 딥러닝 모델을 사용할 수 있는 가능성이 열렸습니다.
앞으로도 지식 증류와 같은 기술이 계속 발전함에 따라, 더 많은 애플리케이션에서 경량화된 모델을 활용할 수 있을 것으로 기대됩니다.